



Apache Beam 移动游戏管道示例
本节将逐步介绍一系列 Apache Beam 管道示例,这些示例演示了比基本 WordCount 示例更复杂的功能。本节中的管道处理来自用户在移动电话上玩的游戏的假设游戏。管道演示了越来越复杂的处理级别;例如,第一个管道展示了如何运行批处理分析作业以获取相对简单的得分数据,而后面的管道使用 Beam 的窗口和触发器功能来提供低延迟数据分析和关于用户游戏模式的更复杂的信息。
注意:这些示例假设您已经熟悉 Beam 编程模型。如果您还没有,我们建议您先熟悉编程模型文档并运行一个基本的示例管道,然后再继续。另请注意,这些示例使用 Java 8 lambda 语法,因此需要 Java 8。但是,您可以使用 Java 7 创建具有等效功能的管道。
注意:这些示例假设您已经熟悉 Beam 编程模型。如果您还没有,我们建议您先熟悉编程模型文档并运行一个基本的示例管道,然后再继续。
注意:MobileGaming 目前尚不支持 Go SDK。对此有一个未解决的问题(问题 18806)。
每次用户玩我们假设的移动游戏时,他们都会生成一个数据事件。每个数据事件包含以下信息
- 玩游戏的用户的唯一 ID。
- 用户所属团队的团队 ID。
- 该特定游戏实例的得分值。
- 记录特定游戏实例发生时间的日期时间戳 - 这是每个游戏数据事件的事件时间。
当用户完成游戏实例时,他们的手机会将数据事件发送到游戏服务器,服务器将在其中记录数据并将其存储在文件中。通常,数据会在完成时立即发送到游戏服务器。但是,有时网络在各个点可能会发生延迟。另一种可能的情况是用户在“离线”状态下玩游戏,此时他们的手机与服务器断开连接(例如,在飞机上或网络覆盖区域外)。当用户的手机重新与游戏服务器建立连接时,手机将发送所有累积的游戏数据。在这些情况下,一些数据事件可能会延迟到达并乱序。
下图显示了理想情况(事件按发生顺序处理)与现实情况(在处理之前通常存在时间延迟)。
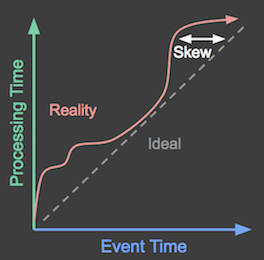
图 1:X 轴表示事件时间:游戏事件实际发生的时间。Y 轴表示处理时间:游戏事件被处理的时间。理想情况下,事件应该在发生时被处理,如图表中的虚线所示。但是,实际上并非如此,它看起来更像是图表中理想线以上的红色波浪线所示。
游戏服务器可能会在用户生成数据事件后很久才收到这些数据事件。这种时间差(称为倾斜)可能会对考虑每个得分生成时间的管道处理产生影响。例如,此类管道可能会跟踪每天每个小时生成的得分,或者计算用户持续玩游戏的时长,这两种情况都取决于每个数据记录的事件时间。
由于我们的一些示例管道使用数据文件(例如来自游戏服务器的日志)作为输入,因此每个游戏的事件时间戳可能嵌入在数据中,即它是每个数据记录中的一个字段。这些管道需要在从输入文件读取每个数据记录后,从每个数据记录中解析事件时间戳。
对于从无界源读取无界游戏数据的管道,数据源会将每个 PCollection 元素的内在 时间戳 设置为适当的事件时间。
移动游戏示例管道在复杂度上有所不同,从简单的批处理分析到更复杂的管道,这些管道可以执行实时分析和滥用检测。本节将逐步介绍每个示例,并演示如何使用 Beam 的窗口和触发器等功能来扩展管道的功能。
UserScore:批处理中的基本得分处理
UserScore 管道是处理移动游戏数据的最简单示例。UserScore 确定有限数据集(例如,游戏服务器上存储的一天的得分)中每个用户的总得分。UserScore 等管道最适合在收集完所有相关数据后定期运行。例如,UserScore 可以作为每天晚上针对当天收集的数据运行的作业。
注意:有关完整的示例管道程序,请参阅 GitHub 上的 UserScore。
注意:有关完整的示例管道程序,请参阅 GitHub 上的 UserScore。
UserScore 的作用是什么?
在一整天的得分数据中,每个用户 ID 可能有多条记录(如果用户在分析窗口期间玩了不止一次游戏),每条记录都有自己的得分值和时间戳。如果我们想确定用户在当天玩的所有实例的总得分,我们的管道将需要将所有记录按单个用户分组。
随着管道处理每个事件,事件得分将添加到该特定用户的总计中。
UserScore 只解析它需要的每个记录中的数据,具体来说是用户 ID 和得分值。管道不会考虑任何记录的事件时间;它只是处理您在运行管道时指定的输入文件中存在的所有数据。
注意:要有效地使用
UserScore管道,您需要确保您提供的输入数据已经按所需的事件时间段进行分组,即,您指定一个仅包含您关心的日期数据的输入文件。
UserScore 的基本管道流程执行以下操作
- 从文本文件读取当天的得分数据。
- 通过按用户 ID 对每个游戏事件进行分组,并将得分值组合起来以获取该特定用户的总得分,来汇总每个唯一用户的得分值。
- 将结果数据写入文本文件。
下图显示了几个用户在管道分析期间的得分数据。在图中,每个数据点都是一个导致一个用户/得分对的事件。
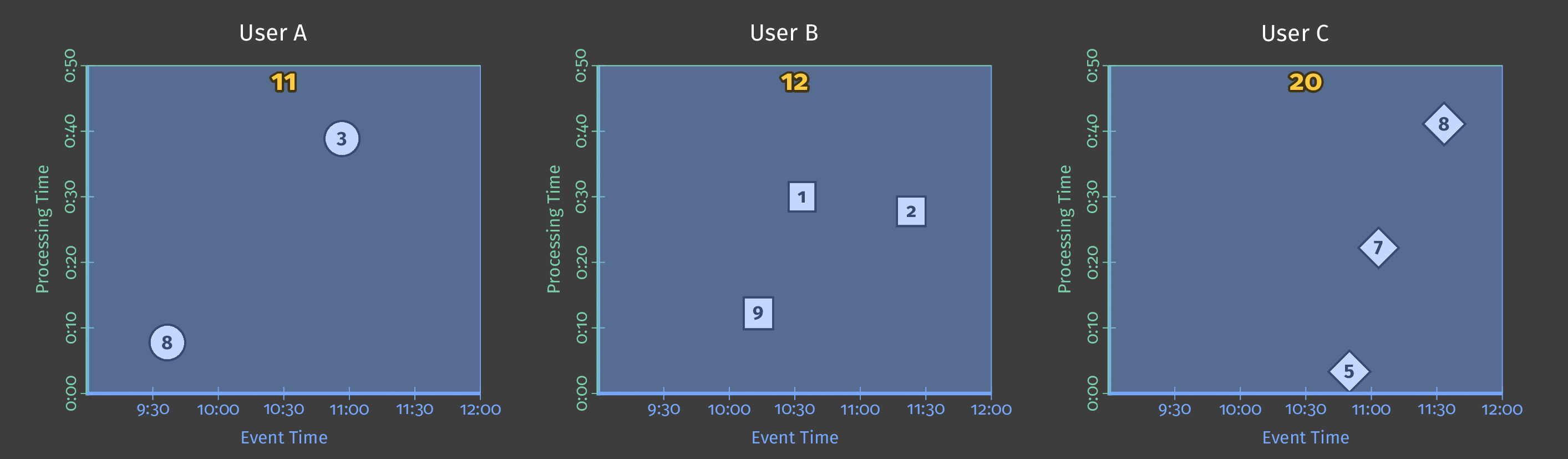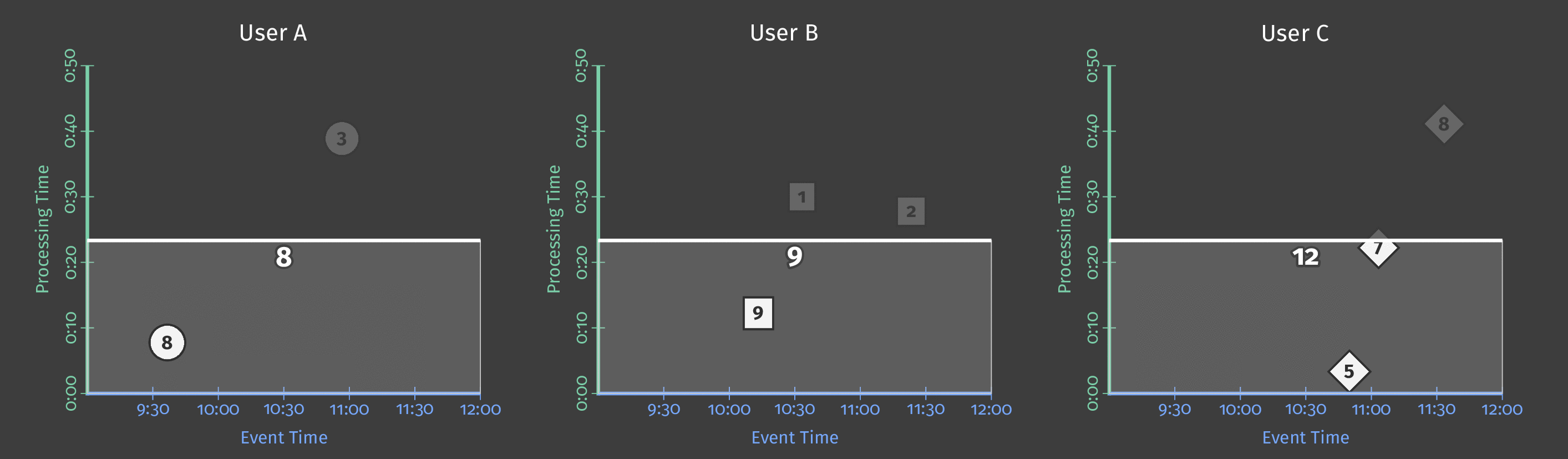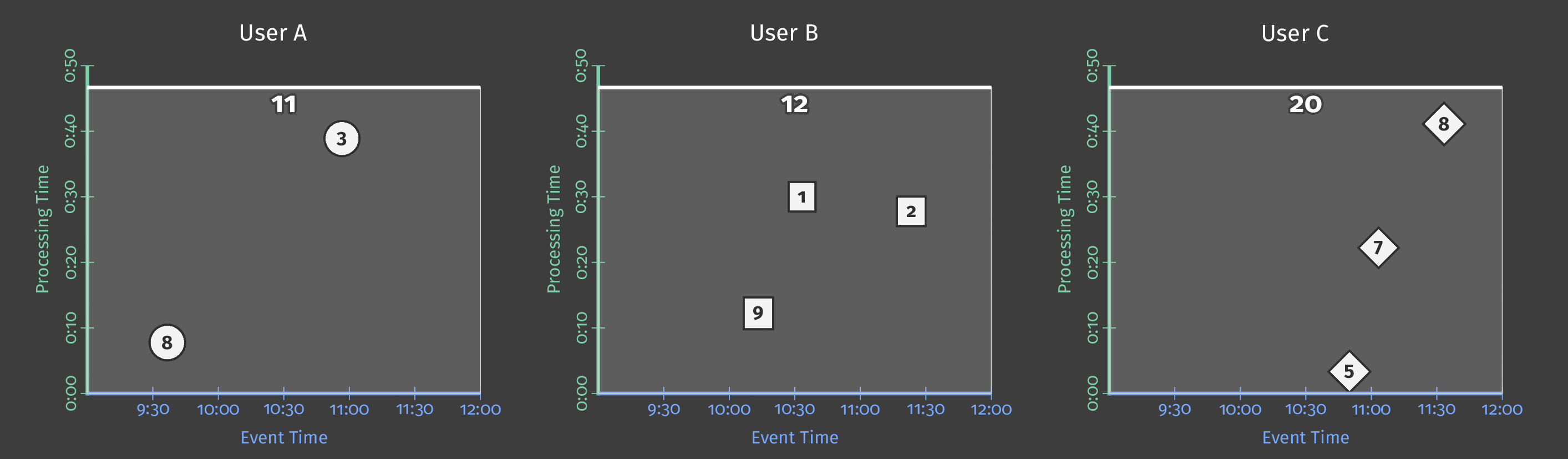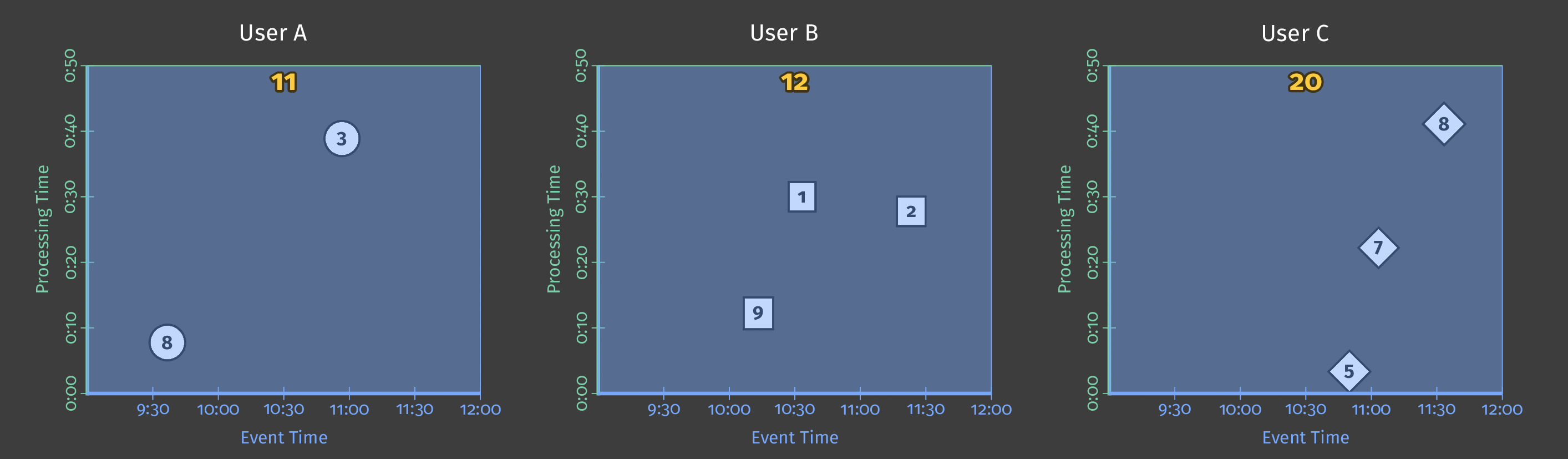
图 2:三个用户的得分数据。
此示例使用批处理,图表的 Y 轴表示处理时间:管道首先处理 Y 轴上较低的事件,然后处理较高的事件。图表的 X 轴表示每个游戏事件的事件时间,如该事件的时间戳所示。请注意,图表中的各个事件不是按发生顺序(根据其时间戳)由管道处理的。
从输入文件读取得分事件后,管道将所有这些用户/得分对分组在一起,并将得分值汇总为每个唯一用户的一个总值。UserScore 将该步骤的核心逻辑封装为 用户定义的复合转换 ExtractAndSumScore
public static class ExtractAndSumScore
extends PTransform<PCollection<GameActionInfo>, PCollection<KV<String, Integer>>> {
private final String field;
ExtractAndSumScore(String field) {
this.field = field;
}
@Override
public PCollection<KV<String, Integer>> expand(PCollection<GameActionInfo> gameInfo) {
return gameInfo
.apply(
MapElements.into(
TypeDescriptors.kvs(TypeDescriptors.strings(), TypeDescriptors.integers()))
.via((GameActionInfo gInfo) -> KV.of(gInfo.getKey(field), gInfo.getScore())))
.apply(Sum.integersPerKey());
}
}class ExtractAndSumScore(beam.PTransform):
"""A transform to extract key/score information and sum the scores.
The constructor argument `field` determines whether 'team' or 'user' info is
extracted.
"""
def __init__(self, field):
# TODO(BEAM-6158): Revert the workaround once we can pickle super() on py3.
# super().__init__()
beam.PTransform.__init__(self)
self.field = field
def expand(self, pcoll):
return (
pcoll
| beam.Map(lambda elem: (elem[self.field], elem['score']))
| beam.CombinePerKey(sum))ExtractAndSumScore 的编写更加通用,因为您可以传入要按其分组数据的字段(在我们的游戏中,按唯一用户或唯一团队分组)。这意味着我们可以将 ExtractAndSumScore 重新用于其他管道,例如按团队对得分数据进行分组的管道。
以下是 UserScore 的主要方法,显示了我们如何应用管道的三个步骤
public static void main(String[] args) throws Exception {
// Begin constructing a pipeline configured by commandline flags.
Options options = PipelineOptionsFactory.fromArgs(args).withValidation().as(Options.class);
Pipeline pipeline = Pipeline.create(options);
// Read events from a text file and parse them.
pipeline
.apply(TextIO.read().from(options.getInput()))
.apply("ParseGameEvent", ParDo.of(new ParseEventFn()))
// Extract and sum username/score pairs from the event data.
.apply("ExtractUserScore", new ExtractAndSumScore("user"))
.apply(
"WriteUserScoreSums", new WriteToText<>(options.getOutput(), configureOutput(), false));
// Run the batch pipeline.
pipeline.run().waitUntilFinish();
}def run(argv=None, save_main_session=True):
"""Main entry point; defines and runs the user_score pipeline."""
parser = argparse.ArgumentParser()
# The default maps to two large Google Cloud Storage files (each ~12GB)
# holding two subsequent day's worth (roughly) of data.
parser.add_argument(
'--input',
type=str,
default='gs://apache-beam-samples/game/small/gaming_data.csv',
help='Path to the data file(s) containing game data.')
parser.add_argument(
'--output', type=str, required=True, help='Path to the output file(s).')
args, pipeline_args = parser.parse_known_args(argv)
options = PipelineOptions(pipeline_args)
# We use the save_main_session option because one or more DoFn's in this
# workflow rely on global context (e.g., a module imported at module level).
options.view_as(SetupOptions).save_main_session = save_main_session
with beam.Pipeline(options=options) as p:
def format_user_score_sums(user_score):
(user, score) = user_score
return 'user: %s, total_score: %s' % (user, score)
( # pylint: disable=expression-not-assigned
p
| 'ReadInputText' >> beam.io.ReadFromText(args.input)
| 'UserScore' >> UserScore()
| 'FormatUserScoreSums' >> beam.Map(format_user_score_sums)
| 'WriteUserScoreSums' >> beam.io.WriteToText(args.output))局限性
如示例中所写,UserScore 管道有一些限制
由于一些得分数据可能是由离线玩家生成的,并在每日截止日期后发送,因此对于游戏数据,
UserScore管道生成的的结果数据可能不完整。UserScore仅处理管道运行时输入文件(s)中存在的固定输入集。UserScore在处理时间处理输入文件中存在的所有数据事件,不会根据事件时间检查或进行错误检查。因此,结果可能包含一些其事件时间超出相关分析期间的值,例如前一天的延迟记录。由于
UserScore仅在收集完所有数据后才运行,因此从用户生成数据事件(事件时间)到计算结果(处理时间)之间存在高延迟。UserScore还只报告全天的总结果,不提供有关数据在当天如何累积的任何更细粒度的信息。
从下一个管道示例开始,我们将讨论如何使用 Beam 的功能来解决这些限制。
HourlyTeamScore:使用窗口的批处理中的高级处理
HourlyTeamScore 管道扩展了 UserScore 管道中使用的基本批处理分析原理,并改进了其一些限制。HourlyTeamScore 执行更细粒度的分析,既通过使用 Beam SDK 中的附加功能,也通过考虑游戏数据的更多方面。例如,HourlyTeamScore 可以过滤掉不属于相关分析期间的数据。
与UserScore类似,HourlyTeamScore 最好理解为一个定期运行的作业,在所有相关数据收集完毕后运行(例如每天运行一次)。管道从文件中读取固定数据集,并将结果写入文本文件写入 Google Cloud BigQuery 表格。
注意: 请参阅GitHub 上的 HourlyTeamScore,了解完整的示例管道程序。
注意: 请参阅GitHub 上的 HourlyTeamScore,了解完整的示例管道程序。
HourlyTeamScore 的作用是什么?
HourlyTeamScore 计算固定数据集(例如一天的数据)中每个团队每小时的总得分。
HourlyTeamScore不会一次性处理整个数据集,而是将输入数据划分为逻辑窗口,并对这些窗口执行计算。这使得HourlyUserScore可以提供每个窗口的评分数据信息,每个窗口代表游戏中得分在固定时间间隔内的进度(例如每小时一次)。HourlyTeamScore根据数据事件的事件时间(由嵌入的时间戳指示)是否在相关的分析时间段内来过滤数据事件。基本上,管道会检查每个游戏事件的时间戳,并确保它在我们要分析的范围内(在本例中为所讨论的当天)。来自前几天的数据事件将被丢弃,不会包含在总得分中。这使得HourlyTeamScore比UserScore更健壮,更不容易出现错误的结果数据。它还允许管道考虑在相关分析时间段内具有时间戳的延迟到达数据。
下面我们将详细了解 HourlyTeamScore 中的这些增强功能。
固定时间窗口
使用固定时间窗口允许管道提供关于事件在分析期间内如何在数据集中累积的更佳信息。在我们的例子中,它告诉我们当天每个团队何时活跃以及该团队在这些时间段内的得分情况。
下图显示了管道在应用固定时间窗口后如何处理一天的单个团队得分数据。
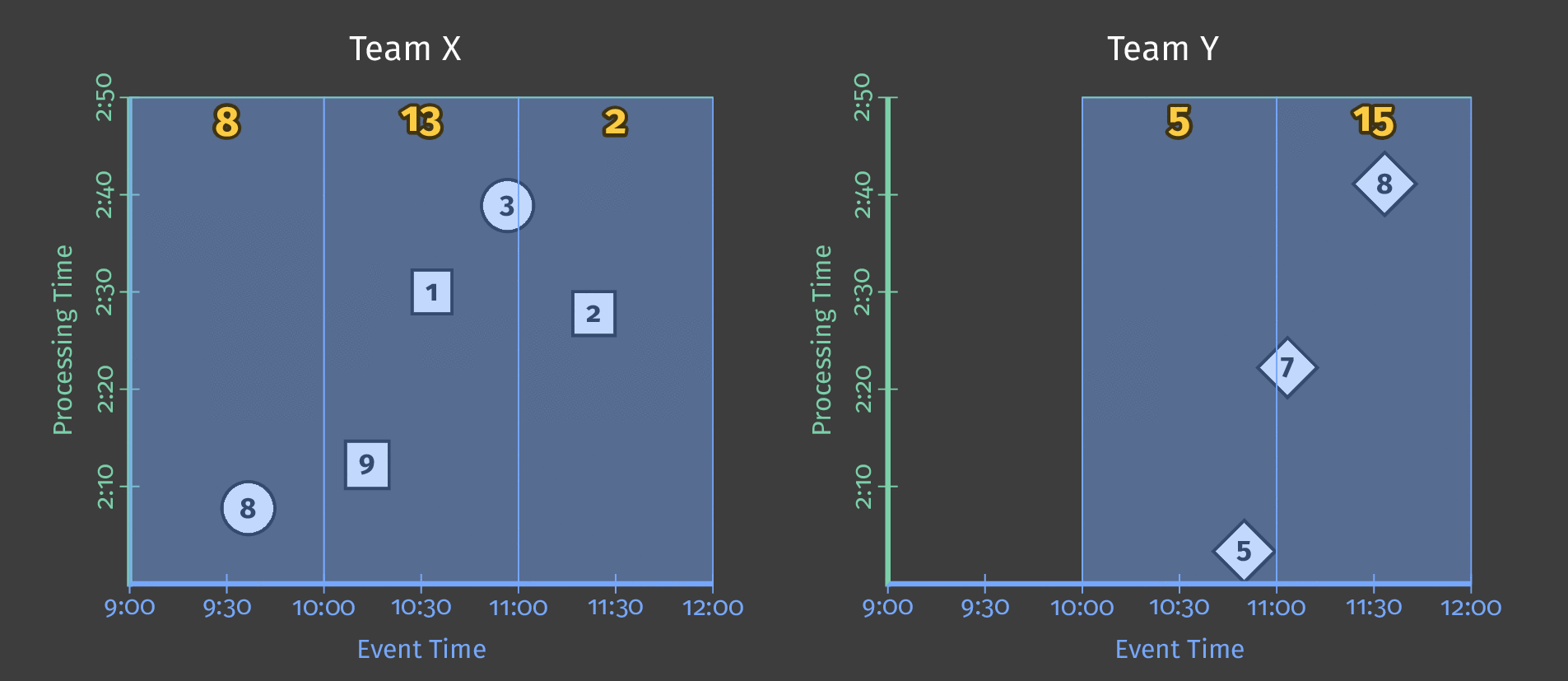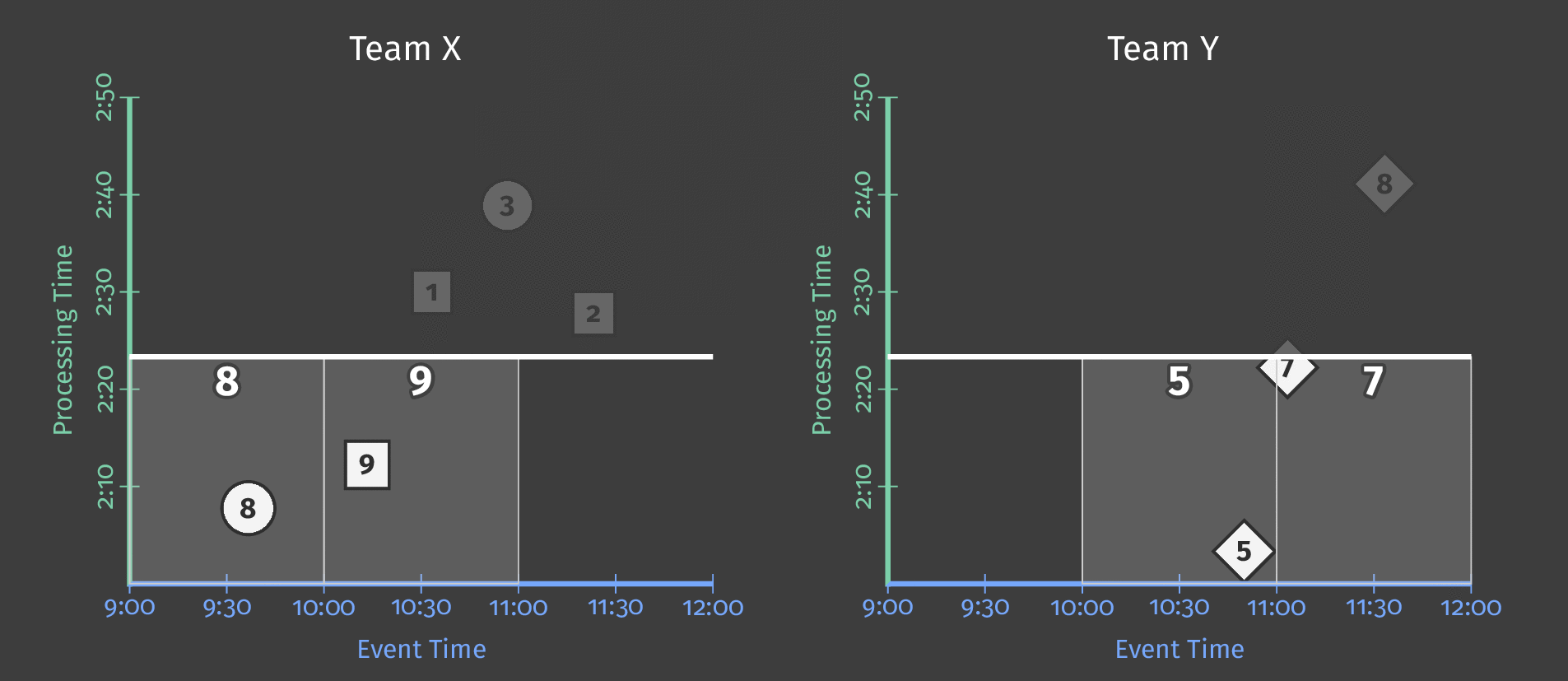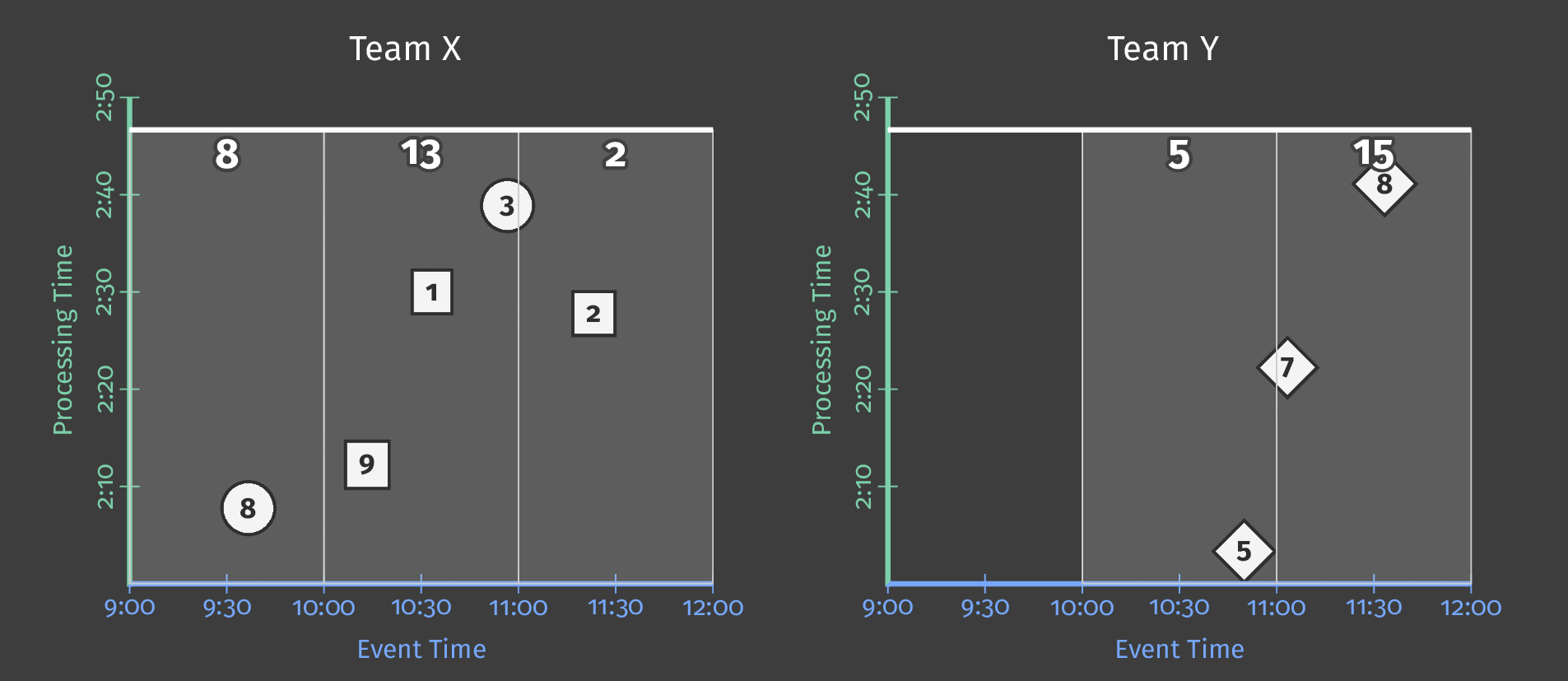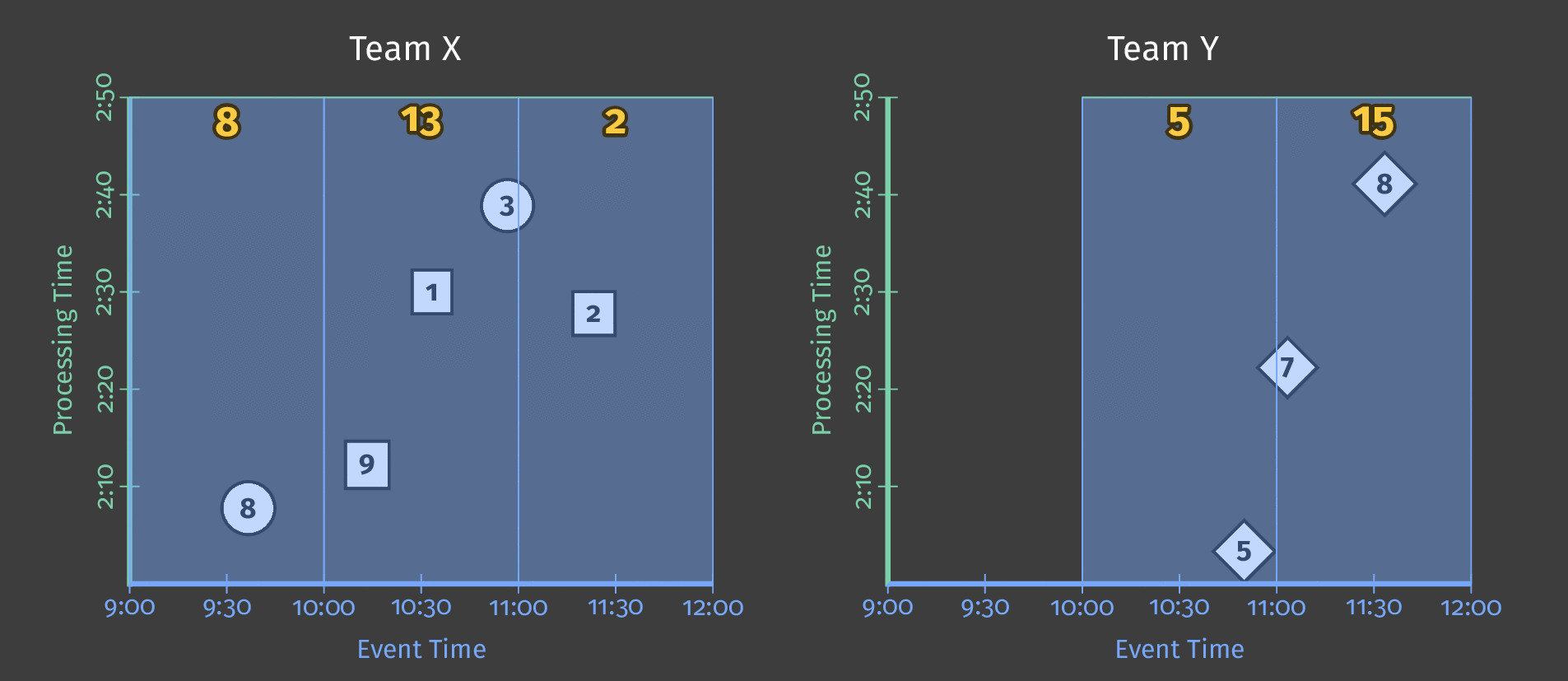
图 3:两个团队的得分数据。每个团队的得分根据这些得分在事件时间内发生的时间划分为逻辑窗口。
请注意,随着处理时间的推进,总和现在是每窗口的;每个窗口代表当天事件时间中得分发生的 1 个小时。
注意: 如上图所示,使用窗口会产生每个时间间隔的独立总计(在本例中,每个小时)。
HourlyTeamScore不会在每个小时提供整个数据集的累计总计 - 它提供仅在该小时内发生的所有事件的总得分。
Beam 的窗口功能使用附加到 PCollection 中每个元素的内在时间戳信息。因为我们希望管道根据事件时间进行窗口划分,所以我们必须首先提取嵌入在每个数据记录中的时间戳,并将其应用到得分数据 PCollection 中的对应元素。然后,管道就可以应用窗口功能将 PCollection 划分为逻辑窗口。
HourlyTeamScore 使用WithTimestamps 和Window 变换来执行这些操作。
HourlyTeamScore 使用 FixedWindows 变换(位于window.py 中)来执行这些操作。
以下代码展示了这一点。
// Add an element timestamp based on the event log, and apply fixed windowing.
.apply(
"AddEventTimestamps",
WithTimestamps.of((GameActionInfo i) -> new Instant(i.getTimestamp())))
.apply(
"FixedWindowsTeam",
Window.into(FixedWindows.of(Duration.standardMinutes(options.getWindowDuration()))))# Add an element timestamp based on the event log, and apply fixed
# windowing.
| 'AddEventTimestamps' >> beam.Map(
lambda elem: beam.window.TimestampedValue(elem, elem['timestamp']))
| 'FixedWindowsTeam' >> beam.WindowInto(
beam.window.FixedWindows(self.window_duration_in_seconds))请注意,管道用于指定窗口划分的变换与实际数据处理变换(如 ExtractAndSumScores)是不同的。此功能在设计 Beam 管道时为您提供了一定的灵活性,您可以对具有不同窗口划分特征的数据集运行现有变换。
根据事件时间过滤
HourlyTeamScore 使用过滤来删除数据集中的任何事件,这些事件的时间戳不在相关的分析时间段内(即,它们不是在我们感兴趣的当天生成的)。这可以防止管道错误地包含任何数据,例如,这些数据是在前一天离线生成的,但在当天发送到游戏服务器。
它还允许管道包含相关的延迟数据 - 具有有效时间戳但到达时间晚于我们的分析时间段结束的数据。例如,如果我们的管道截止时间是午夜 12 点,我们可能在凌晨 2 点运行管道,但会过滤掉时间戳表明它们发生在午夜 12 点截止时间之后的所有事件。在凌晨 12 点 01 分到凌晨 2 点之间延迟到达但时间戳表明它们发生在午夜 12 点截止时间之前的数据事件将包含在管道处理中。
HourlyTeamScore 使用 Filter 变换来执行此操作。当您应用 Filter 时,您会指定一个谓词,每个数据记录都会与该谓词进行比较。通过比较的数据记录将被包含,而未通过比较的事件将被排除。在我们的例子中,谓词是我们指定的截止时间,我们只比较数据的一部分 - 时间戳字段。
以下代码展示了 HourlyTeamScore 如何使用 Filter 变换过滤在相关分析时间段之前或之后发生的事件。
.apply(
"FilterStartTime",
Filter.by(
(GameActionInfo gInfo) -> gInfo.getTimestamp() > startMinTimestamp.getMillis()))
.apply(
"FilterEndTime",
Filter.by(
(GameActionInfo gInfo) -> gInfo.getTimestamp() < stopMinTimestamp.getMillis()))| 'FilterStartTime' >>
beam.Filter(lambda elem: elem['timestamp'] > self.start_timestamp)
| 'FilterEndTime' >>
beam.Filter(lambda elem: elem['timestamp'] < self.stop_timestamp)计算每个窗口每个团队的得分
HourlyTeamScore 使用与 UserScore 管道相同的 ExtractAndSumScores 变换,但传递不同的键(团队,而不是用户)。此外,因为管道在对输入数据应用固定时间 1 小时窗口之后才应用 ExtractAndSumScores,所以数据会按团队和窗口进行分组。您可以在 HourlyTeamScore 的主方法中看到完整的变换序列。
public static void main(String[] args) throws Exception {
// Begin constructing a pipeline configured by commandline flags.
Options options = PipelineOptionsFactory.fromArgs(args).withValidation().as(Options.class);
Pipeline pipeline = Pipeline.create(options);
final Instant stopMinTimestamp = new Instant(minFmt.parseMillis(options.getStopMin()));
final Instant startMinTimestamp = new Instant(minFmt.parseMillis(options.getStartMin()));
// Read 'gaming' events from a text file.
pipeline
.apply(TextIO.read().from(options.getInput()))
// Parse the incoming data.
.apply("ParseGameEvent", ParDo.of(new ParseEventFn()))
// Filter out data before and after the given times so that it is not included
// in the calculations. As we collect data in batches (say, by day), the batch for the day
// that we want to analyze could potentially include some late-arriving data from the
// previous day.
// If so, we want to weed it out. Similarly, if we include data from the following day
// (to scoop up late-arriving events from the day we're analyzing), we need to weed out
// events that fall after the time period we want to analyze.
// [START DocInclude_HTSFilters]
.apply(
"FilterStartTime",
Filter.by(
(GameActionInfo gInfo) -> gInfo.getTimestamp() > startMinTimestamp.getMillis()))
.apply(
"FilterEndTime",
Filter.by(
(GameActionInfo gInfo) -> gInfo.getTimestamp() < stopMinTimestamp.getMillis()))
// [END DocInclude_HTSFilters]
// [START DocInclude_HTSAddTsAndWindow]
// Add an element timestamp based on the event log, and apply fixed windowing.
.apply(
"AddEventTimestamps",
WithTimestamps.of((GameActionInfo i) -> new Instant(i.getTimestamp())))
.apply(
"FixedWindowsTeam",
Window.into(FixedWindows.of(Duration.standardMinutes(options.getWindowDuration()))))
// [END DocInclude_HTSAddTsAndWindow]
// Extract and sum teamname/score pairs from the event data.
.apply("ExtractTeamScore", new ExtractAndSumScore("team"))
.apply(
"WriteTeamScoreSums", new WriteToText<>(options.getOutput(), configureOutput(), true));
pipeline.run().waitUntilFinish();
}class HourlyTeamScore(beam.PTransform):
def __init__(self, start_min, stop_min, window_duration):
# TODO(BEAM-6158): Revert the workaround once we can pickle super() on py3.
# super().__init__()
beam.PTransform.__init__(self)
self.start_timestamp = str2timestamp(start_min)
self.stop_timestamp = str2timestamp(stop_min)
self.window_duration_in_seconds = window_duration * 60
def expand(self, pcoll):
return (
pcoll
| 'ParseGameEventFn' >> beam.ParDo(ParseGameEventFn())
# Filter out data before and after the given times so that it is not
# included in the calculations. As we collect data in batches (say, by
# day), the batch for the day that we want to analyze could potentially
# include some late-arriving data from the previous day. If so, we want
# to weed it out. Similarly, if we include data from the following day
# (to scoop up late-arriving events from the day we're analyzing), we
# need to weed out events that fall after the time period we want to
# analyze.
# [START filter_by_time_range]
| 'FilterStartTime' >>
beam.Filter(lambda elem: elem['timestamp'] > self.start_timestamp)
| 'FilterEndTime' >>
beam.Filter(lambda elem: elem['timestamp'] < self.stop_timestamp)
# [END filter_by_time_range]
# [START add_timestamp_and_window]
# Add an element timestamp based on the event log, and apply fixed
# windowing.
| 'AddEventTimestamps' >> beam.Map(
lambda elem: beam.window.TimestampedValue(elem, elem['timestamp']))
| 'FixedWindowsTeam' >> beam.WindowInto(
beam.window.FixedWindows(self.window_duration_in_seconds))
# [END add_timestamp_and_window]
# Extract and sum teamname/score pairs from the event data.
| 'ExtractAndSumScore' >> ExtractAndSumScore('team'))
def run(argv=None, save_main_session=True):
"""Main entry point; defines and runs the hourly_team_score pipeline."""
parser = argparse.ArgumentParser()
# The default maps to two large Google Cloud Storage files (each ~12GB)
# holding two subsequent day's worth (roughly) of data.
parser.add_argument(
'--input',
type=str,
default='gs://apache-beam-samples/game/gaming_data*.csv',
help='Path to the data file(s) containing game data.')
parser.add_argument(
'--dataset',
type=str,
required=True,
help='BigQuery Dataset to write tables to. '
'Must already exist.')
parser.add_argument(
'--table_name',
default='leader_board',
help='The BigQuery table name. Should not already exist.')
parser.add_argument(
'--window_duration',
type=int,
default=60,
help='Numeric value of fixed window duration, in minutes')
parser.add_argument(
'--start_min',
type=str,
default='1970-01-01-00-00',
help='String representation of the first minute after '
'which to generate results in the format: '
'yyyy-MM-dd-HH-mm. Any input data timestamped '
'prior to that minute won\'t be included in the '
'sums.')
parser.add_argument(
'--stop_min',
type=str,
default='2100-01-01-00-00',
help='String representation of the first minute for '
'which to generate results in the format: '
'yyyy-MM-dd-HH-mm. Any input data timestamped '
'after to that minute won\'t be included in the '
'sums.')
args, pipeline_args = parser.parse_known_args(argv)
options = PipelineOptions(pipeline_args)
# We also require the --project option to access --dataset
if options.view_as(GoogleCloudOptions).project is None:
parser.print_usage()
print(sys.argv[0] + ': error: argument --project is required')
sys.exit(1)
# We use the save_main_session option because one or more DoFn's in this
# workflow rely on global context (e.g., a module imported at module level).
options.view_as(SetupOptions).save_main_session = save_main_session
with beam.Pipeline(options=options) as p:
( # pylint: disable=expression-not-assigned
p
| 'ReadInputText' >> beam.io.ReadFromText(args.input)
| 'HourlyTeamScore' >> HourlyTeamScore(
args.start_min, args.stop_min, args.window_duration)
| 'TeamScoresDict' >> beam.ParDo(TeamScoresDict())
| 'WriteTeamScoreSums' >> WriteToBigQuery(
args.table_name,
args.dataset,
{
'team': 'STRING',
'total_score': 'INTEGER',
'window_start': 'STRING',
},
options.view_as(GoogleCloudOptions).project))局限性
正如所写,HourlyTeamScore 仍然存在一个限制。
HourlyTeamScore仍然存在数据事件发生(事件时间)到生成结果(处理时间)之间延迟时间长的问题,因为作为批处理管道,它需要等到所有数据事件都出现才能开始处理。
LeaderBoard:使用实时游戏数据的流式处理
我们可以帮助解决 UserScore 和 HourlyTeamScore 管道中存在的延迟问题的一种方法是从无界源读取得分数据。LeaderBoard 管道通过从产生无限数量数据的无界源(而不是从游戏服务器上的文件)读取游戏得分数据,引入了流式处理。
LeaderBoard 管道还演示了如何相对于处理时间和事件时间处理游戏得分数据。LeaderBoard 输出有关单个用户得分和团队得分的数据,每个数据都相对于不同的时间框架。
由于 LeaderBoard 管道在生成数据时从无界源读取游戏数据,因此您可以将管道视为与游戏进程同时运行的持续作业。因此,LeaderBoard 可以提供有关用户在任何给定时间如何玩游戏的低延迟洞察 - 如果我们想提供实时基于网络的记分牌,以便用户可以在玩游戏时跟踪他们在其他用户中的进度,这将很有用。
注意: 请参阅GitHub 上的 LeaderBoard,了解完整的示例管道程序。
注意: 请参阅GitHub 上的 LeaderBoard,了解完整的示例管道程序。
LeaderBoard 的作用是什么?
LeaderBoard 管道读取发布到无界源的游戏数据,该无界源以接近实时的速度产生无限数量的数据,并使用该数据执行两个独立的处理任务。
LeaderBoard计算每个唯一用户的总得分,并发布每 10 分钟处理时间的推测结果。也就是说,在收到数据 10 分钟后,管道输出管道迄今已处理的每个用户的总得分。这种计算提供了接近实时的累计“记分牌”,无论实际游戏事件何时生成。LeaderBoard计算管道运行的每个小时的团队得分。如果我们想(例如)奖励每个小时玩游戏时得分最高的团队,这将很有用。团队得分计算使用固定时间窗口划分输入数据,将数据划分为基于事件时间(由时间戳指示)的每小时有限窗口,因为数据到达管道。此外,团队得分计算使用 Beam 的触发机制为每个小时提供推测结果(每 5 分钟更新一次,直到该小时结束),并且还捕获任何延迟数据,并将其添加到它所属的特定每小时窗口。
下面我们将详细介绍这两个任务。
根据处理时间计算用户得分
我们希望管道为每 10 分钟的处理时间输出每个用户的累计总得分。此计算不考虑用户游戏实例实际生成分数的时间;它只输出管道迄今收到的该用户的全部分数的总和。延迟数据在管道运行时到达时会包含在计算中。
由于我们希望在每次更新计算时获取所有到达管道的數據,因此我们让管道在单个全局窗口中考虑所有用户得分数据。单个全局窗口是无界的,但我们可以使用处理时间触发器为每 10 分钟的计算指定一种临时的截止点。
当我们为单个全局窗口指定 10 分钟处理时间触发器时,管道会在触发器每次触发时有效地对窗口的内容进行“快照”。此快照在收到数据后 10 分钟过去后发生。如果没有数据到达,管道将在元素到达后 10 分钟进行下一个“快照”。由于我们使用的是单个全局窗口,因此每个快照都包含到那时为止收集的所有数据。下图显示了在单个全局窗口上使用处理时间触发器的影响。
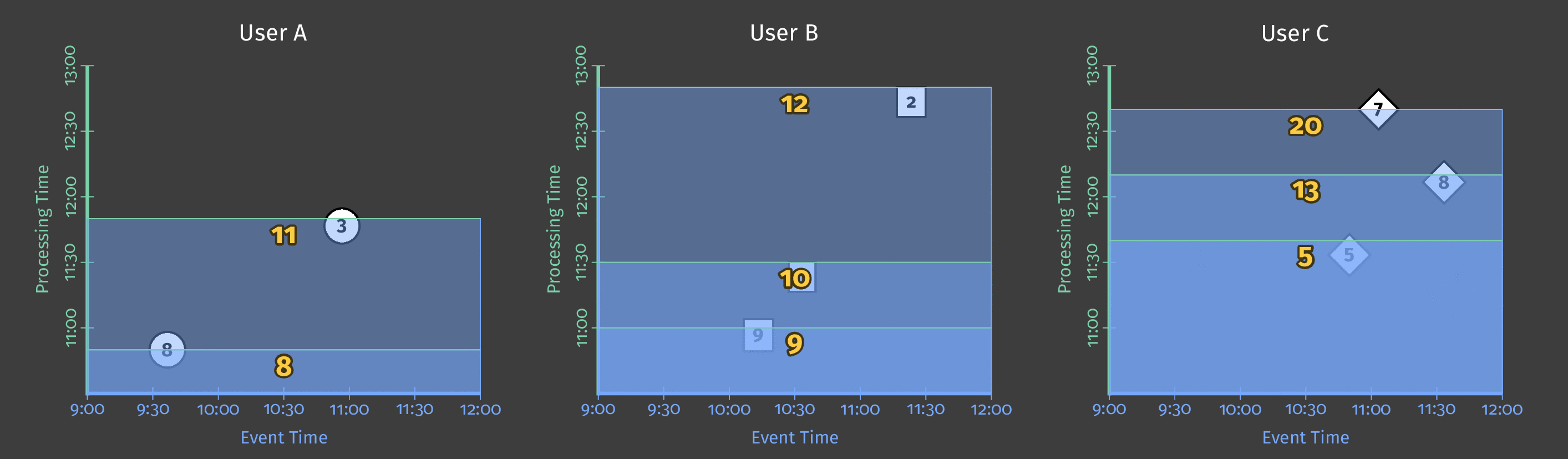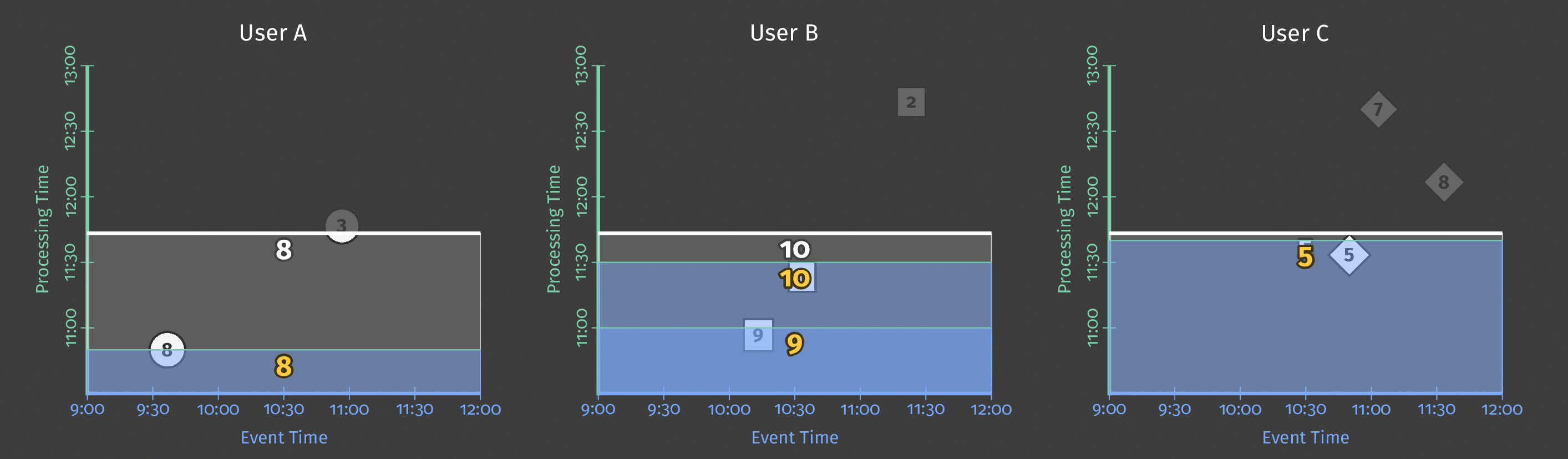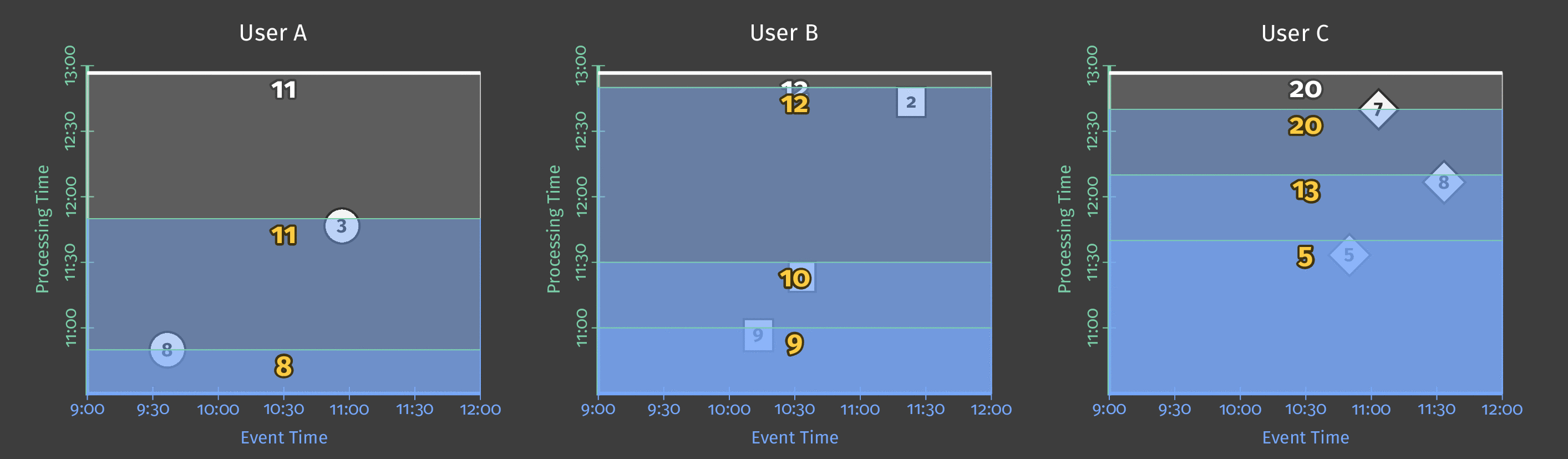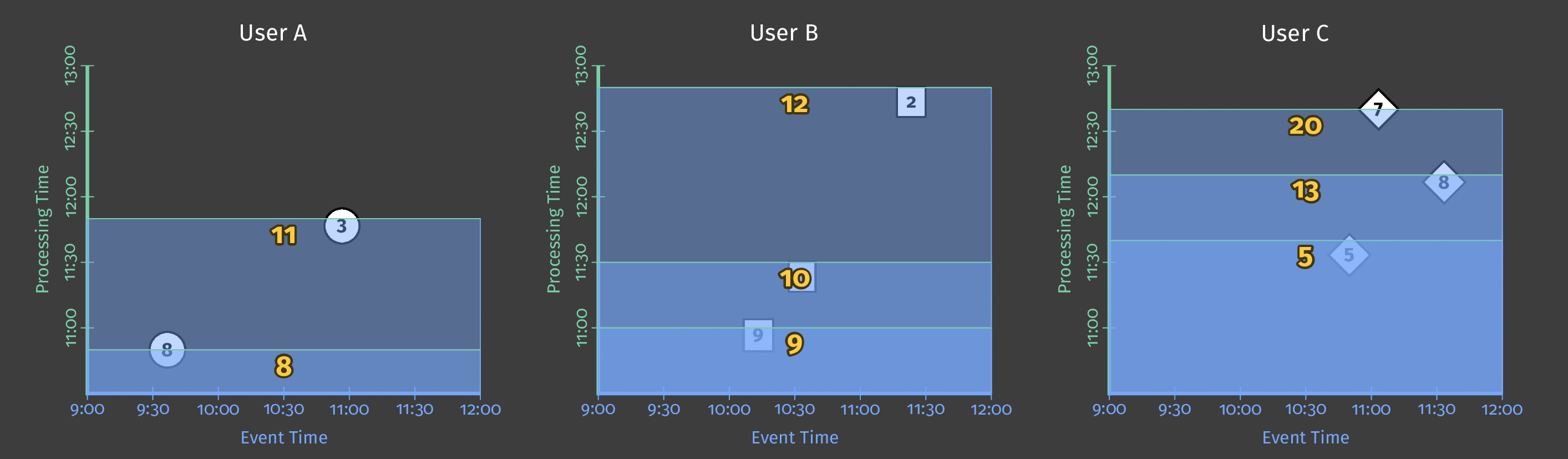
图 4:三个用户的得分数据。每个用户的得分都集中在一个全局窗口中,触发器会在收到数据后 10 分钟生成一个快照以供输出。
随着处理时间的推移以及更多分数的处理,触发器输出每个用户的更新后的总和。
以下代码示例展示了 LeaderBoard 如何设置处理时间触发器以输出用户分数的数据。
/**
* Extract user/score pairs from the event stream using processing time, via global windowing. Get
* periodic updates on all users' running scores.
*/
@VisibleForTesting
static class CalculateUserScores
extends PTransform<PCollection<GameActionInfo>, PCollection<KV<String, Integer>>> {
private final Duration allowedLateness;
CalculateUserScores(Duration allowedLateness) {
this.allowedLateness = allowedLateness;
}
@Override
public PCollection<KV<String, Integer>> expand(PCollection<GameActionInfo> input) {
return input
.apply(
"LeaderboardUserGlobalWindow",
Window.<GameActionInfo>into(new GlobalWindows())
// Get periodic results every ten minutes.
.triggering(
Repeatedly.forever(
AfterProcessingTime.pastFirstElementInPane().plusDelayOf(TEN_MINUTES)))
.accumulatingFiredPanes()
.withAllowedLateness(allowedLateness))
// Extract and sum username/score pairs from the event data.
.apply("ExtractUserScore", new ExtractAndSumScore("user"));
}
}class CalculateUserScores(beam.PTransform):
"""Extract user/score pairs from the event stream using processing time, via
global windowing. Get periodic updates on all users' running scores.
"""
def __init__(self, allowed_lateness):
# TODO(BEAM-6158): Revert the workaround once we can pickle super() on py3.
# super().__init__()
beam.PTransform.__init__(self)
self.allowed_lateness_seconds = allowed_lateness * 60
def expand(self, pcoll):
# NOTE: the behavior does not exactly match the Java example
# TODO: allowed_lateness not implemented yet in FixedWindows
# TODO: AfterProcessingTime not implemented yet, replace AfterCount
return (
pcoll
# Get periodic results every ten events.
| 'LeaderboardUserGlobalWindows' >> beam.WindowInto(
beam.window.GlobalWindows(),
trigger=trigger.Repeatedly(trigger.AfterCount(10)),
accumulation_mode=trigger.AccumulationMode.ACCUMULATING)
# Extract and sum username/score pairs from the event data.
| 'ExtractAndSumScore' >> ExtractAndSumScore('user'))LeaderBoard 将窗口累积模式设置为在触发器触发时累积窗口窗格。这种累积模式是通过调用 .accumulatingFiredPanes 使用 accumulation_mode=trigger.AccumulationMode.ACCUMULATING 在设置触发器时设置的,它会导致管道将先前发出的数据与自上次触发器触发以来到达的任何新数据一起累积。这确保了 LeaderBoard 是用户分数的累计总和,而不是单个总和的集合。
根据事件时间计算团队得分
我们还希望管道在每个小时的游戏过程中输出每个团队的总得分。与用户得分计算不同,对于团队得分,我们关心的是每个得分实际发生的事件时间,因为我们希望单独考虑每个小时的游戏。我们还希望在每个小时进行时提供推测性更新,并允许任何延迟数据的实例 - 在考虑某个小时的数据完成后到达的数据 - 包含在我们的计算中。
由于我们单独考虑每个小时,因此可以对输入数据应用固定时间窗口,就像在 HourlyTeamScore 中一样。为了提供推测性更新和延迟数据的更新,我们将指定额外的触发参数。触发器将导致每个窗口以我们指定的间隔(在本例中为每五分钟)计算并发出结果,并且在窗口被认为“完成”后继续触发以考虑延迟数据。就像用户分数计算一样,我们将触发器设置为累积模式以确保我们获得每个小时窗口的运行总和。
推测性更新和延迟数据的触发器有助于解决 时间偏差 问题。管道中的事件不一定按其时间戳实际发生的时间顺序进行处理;它们可能会在管道中无序到达,或者延迟(在本例中,由于它们是在用户的手机与网络断开连接时生成的)。Beam 需要一种方法来确定何时可以合理地假设它拥有给定窗口中的“所有”数据:这称为水印。
在理想情况下,所有数据都将在发生时立即处理,因此处理时间将等于(或至少与事件时间呈线性关系)。但是,由于分布式系统包含一些固有的不准确性(例如我们延迟报告的手机),Beam 通常使用启发式水印。
下图显示了两个团队的持续处理时间和每个分数的事件时间之间的关系
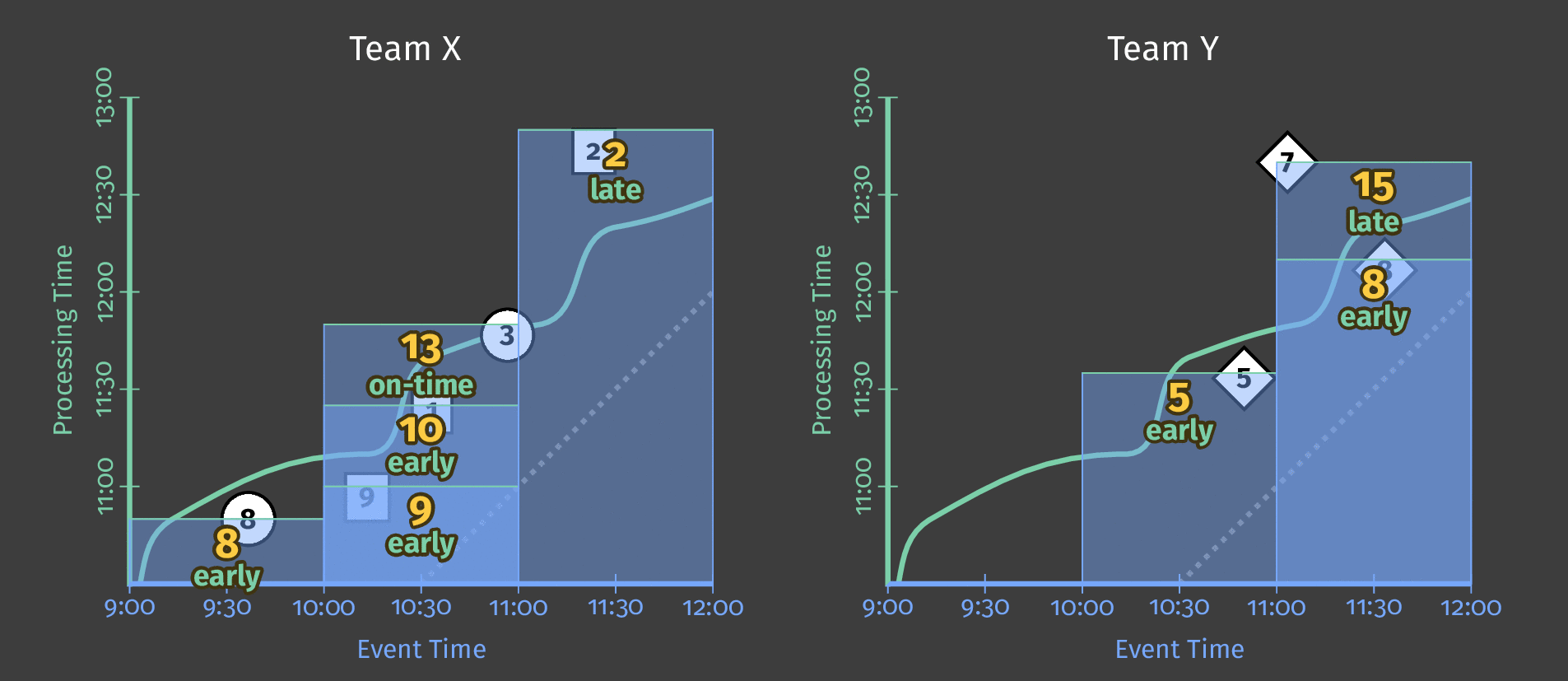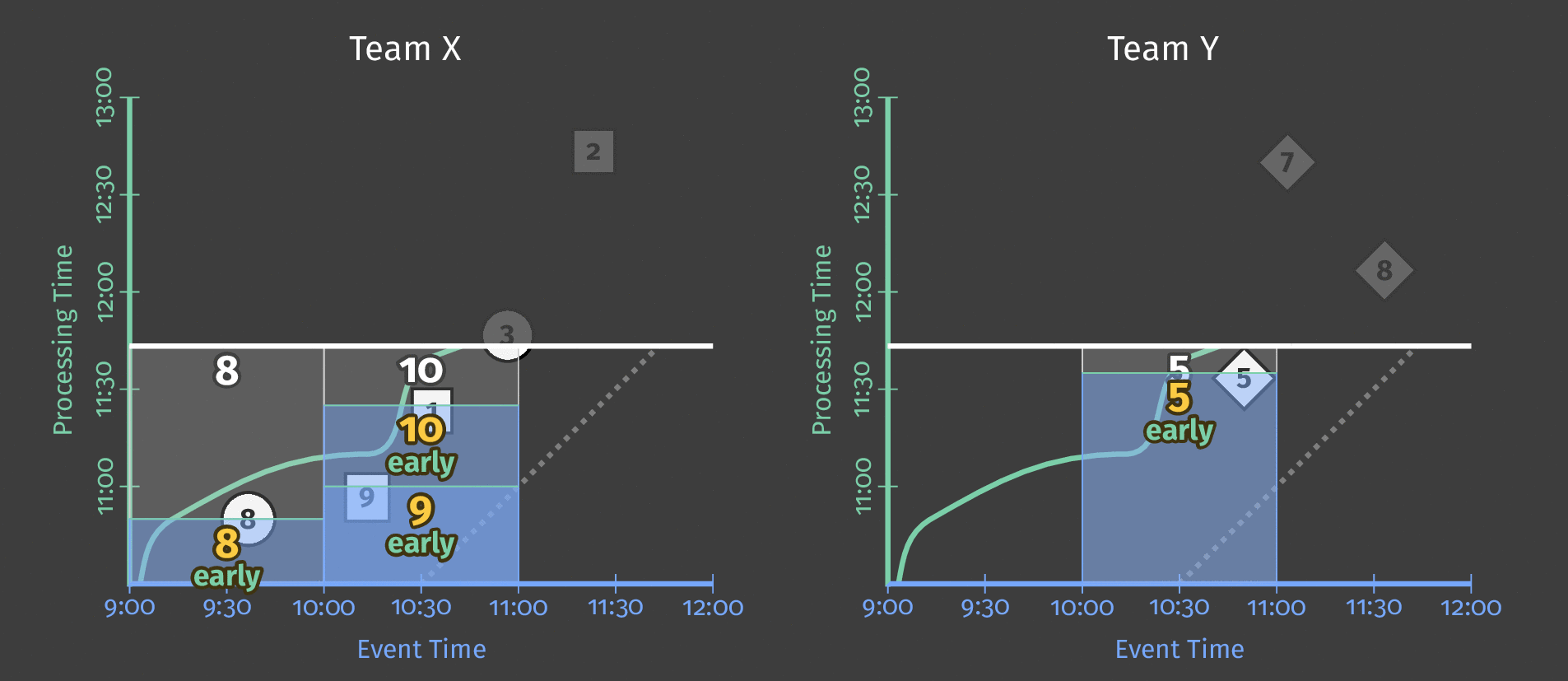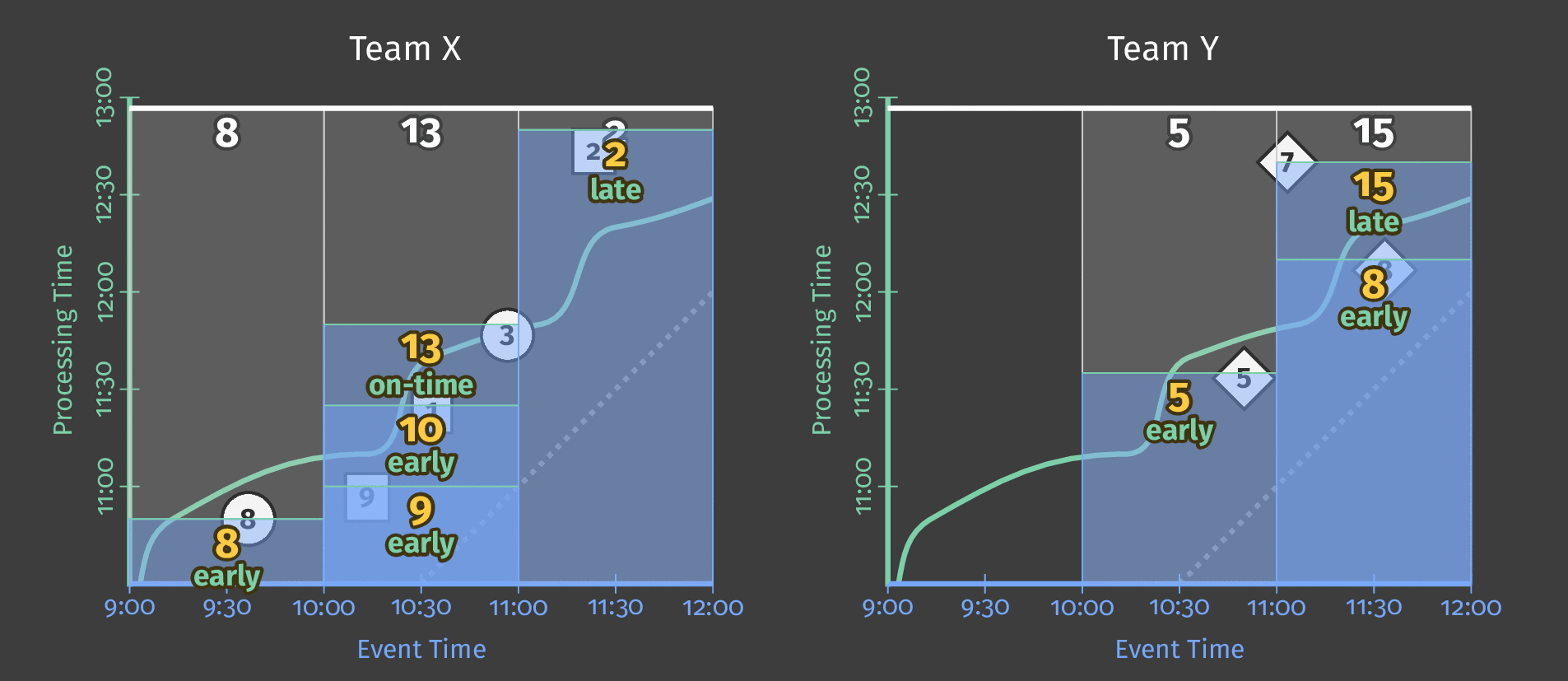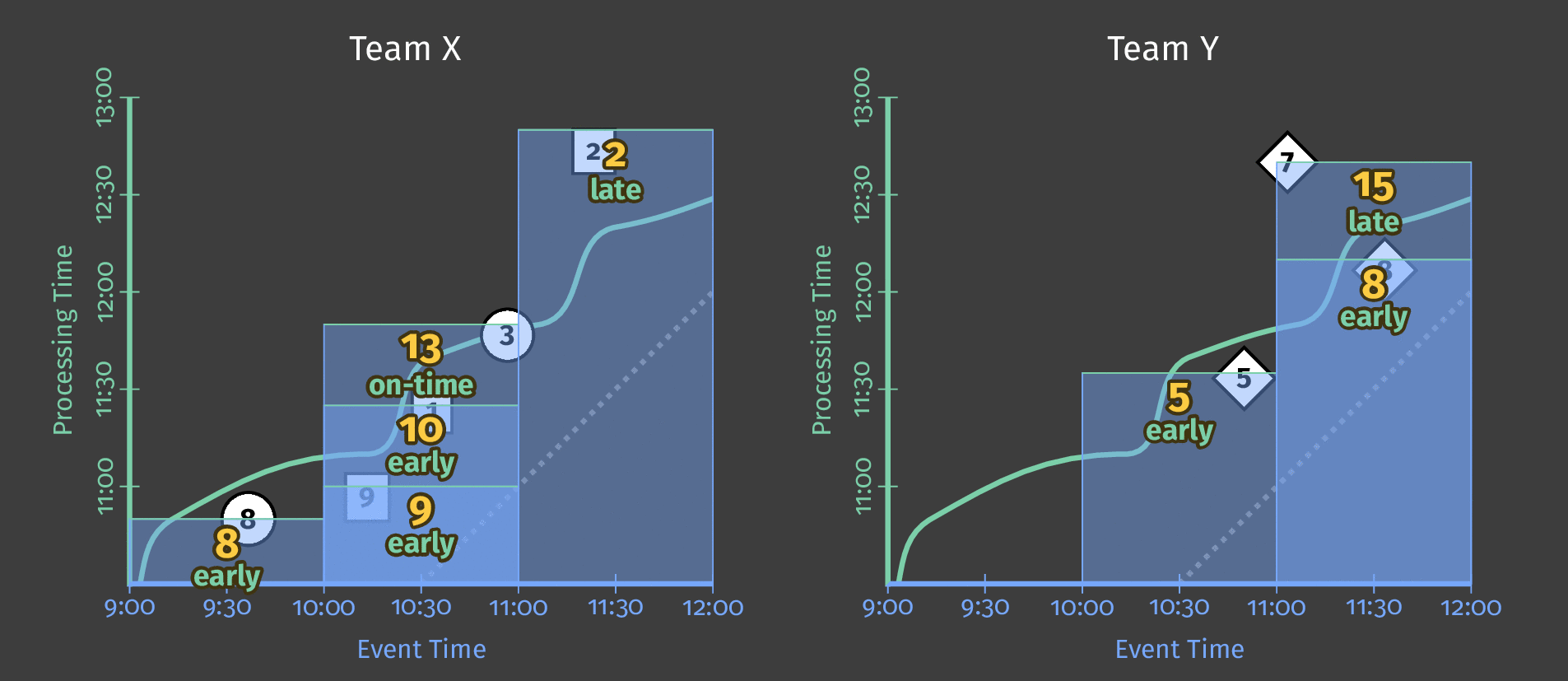
图 5:按团队划分的得分数据,按事件时间分窗。基于处理时间的触发器会导致窗口发出推测性的早期结果并包含延迟结果。
图中的虚线是“理想”的水印:Beam 对给定窗口中所有数据何时可以合理地认为已到达的看法。不规则的实线表示实际水印,由数据源确定。
到达实线水印线以上的数据是延迟数据——这是一个延迟(可能是在离线生成)并在其所属窗口关闭后到达的得分事件。我们管道的延迟触发确保此延迟数据仍包含在总和中。
以下代码示例展示了 LeaderBoard 如何应用固定时间窗口以及相应的触发器,使我们的管道执行我们想要计算
// Extract team/score pairs from the event stream, using hour-long windows by default.
@VisibleForTesting
static class CalculateTeamScores
extends PTransform<PCollection<GameActionInfo>, PCollection<KV<String, Integer>>> {
private final Duration teamWindowDuration;
private final Duration allowedLateness;
CalculateTeamScores(Duration teamWindowDuration, Duration allowedLateness) {
this.teamWindowDuration = teamWindowDuration;
this.allowedLateness = allowedLateness;
}
@Override
public PCollection<KV<String, Integer>> expand(PCollection<GameActionInfo> infos) {
return infos
.apply(
"LeaderboardTeamFixedWindows",
Window.<GameActionInfo>into(FixedWindows.of(teamWindowDuration))
// We will get early (speculative) results as well as cumulative
// processing of late data.
.triggering(
AfterWatermark.pastEndOfWindow()
.withEarlyFirings(
AfterProcessingTime.pastFirstElementInPane()
.plusDelayOf(FIVE_MINUTES))
.withLateFirings(
AfterProcessingTime.pastFirstElementInPane()
.plusDelayOf(TEN_MINUTES)))
.withAllowedLateness(allowedLateness)
.accumulatingFiredPanes())
// Extract and sum teamname/score pairs from the event data.
.apply("ExtractTeamScore", new ExtractAndSumScore("team"));
}
}class CalculateTeamScores(beam.PTransform):
"""Calculates scores for each team within the configured window duration.
Extract team/score pairs from the event stream, using hour-long windows by
default.
"""
def __init__(self, team_window_duration, allowed_lateness):
# TODO(BEAM-6158): Revert the workaround once we can pickle super() on py3.
# super().__init__()
beam.PTransform.__init__(self)
self.team_window_duration = team_window_duration * 60
self.allowed_lateness_seconds = allowed_lateness * 60
def expand(self, pcoll):
# NOTE: the behavior does not exactly match the Java example
# TODO: allowed_lateness not implemented yet in FixedWindows
# TODO: AfterProcessingTime not implemented yet, replace AfterCount
return (
pcoll
# We will get early (speculative) results as well as cumulative
# processing of late data.
| 'LeaderboardTeamFixedWindows' >> beam.WindowInto(
beam.window.FixedWindows(self.team_window_duration),
trigger=trigger.AfterWatermark(
trigger.AfterCount(10), trigger.AfterCount(20)),
accumulation_mode=trigger.AccumulationMode.ACCUMULATING)
# Extract and sum teamname/score pairs from the event data.
| 'ExtractAndSumScore' >> ExtractAndSumScore('team'))总而言之,这些处理策略使我们能够解决 UserScore 和 HourlyTeamScore 管道中存在的延迟和完整性问题,同时仍然使用相同的基本转换来处理数据——事实上,这两个计算仍然使用相同的 ExtractAndSumScore 转换,我们在 UserScore 和 HourlyTeamScore 管道中都使用过它。
GameStats:滥用检测和使用情况分析
虽然 LeaderBoard 演示了如何使用基本的窗口和触发器来执行低延迟和灵活的数据分析,但我们可以使用更高级的窗口技术来执行更全面的分析。这可能包括一些旨在检测系统滥用(如垃圾邮件)或深入了解用户行为的计算。GameStats 管道建立在 LeaderBoard 中的低延迟功能的基础上,展示了如何使用 Beam 执行这种高级分析。
与 LeaderBoard 一样,GameStats 从无界源读取数据。最好将其视为一项持续作业,它为用户玩游戏提供见解。
注意:请参阅 GitHub 上的 GameStats,了解完整的示例管道程序。
注意:请参阅 GitHub 上的 GameStats,了解完整的示例管道程序。
GameStats 的作用是什么?
与 LeaderBoard 一样,GameStats 计算每个小时每个团队的总得分。但是,该管道还执行两种更复杂的分析
GameStats执行滥用检测系统,它对得分数据进行一些简单的统计分析,以确定哪些用户(如果有)可能是垃圾邮件发送者或机器人。然后,它使用可疑垃圾邮件/机器人用户的列表从每小时团队得分计算中过滤掉机器人。GameStats通过将具有相似事件时间的游戏数据分组在一起使用会话窗口来分析使用模式。这使我们能够了解用户倾向于玩游戏的时间,以及游戏长度如何随时间变化。
下面,我们将更详细地介绍这些功能。
滥用检测
假设我们游戏中得分取决于用户在手机上“点击”的速度。GameStats 的滥用检测分析每个用户的得分数据以检测用户是否具有异常高的“点击率”,从而导致异常高的得分。这可能表明游戏正在由一个比人类玩游戏快得多的机器人玩。
为了确定分数是否“异常”高,GameStats 计算该固定时间窗口中每个分数的平均值,然后将每个单独的分数与平均分数乘以任意权重因子(在本例中为 2.5)进行比较。因此,任何超过平均值 2.5 倍的分数都被视为垃圾邮件的结果。GameStats 管道跟踪“垃圾邮件”用户的列表,并在计算团队排行榜的团队得分时过滤掉这些用户。
由于平均值取决于管道数据,因此我们需要计算它,然后在随后的 ParDo 转换中使用该计算数据,该转换过滤掉超过加权值的得分。为此,我们可以将计算出的平均值作为 侧输入 传递给过滤 ParDo。
以下代码示例展示了处理滥用检测的复合转换。该转换使用 Sum.integersPerKey 转换对每个用户的全部分数求和,然后使用 Mean.globally 转换确定所有用户的平均分数。一旦计算出来(作为 PCollectionView 单例),我们就可以使用 .withSideInputs 将其传递给过滤 ParDo
public static class CalculateSpammyUsers
extends PTransform<PCollection<KV<String, Integer>>, PCollection<KV<String, Integer>>> {
private static final Logger LOG = LoggerFactory.getLogger(CalculateSpammyUsers.class);
private static final double SCORE_WEIGHT = 2.5;
@Override
public PCollection<KV<String, Integer>> expand(PCollection<KV<String, Integer>> userScores) {
// Get the sum of scores for each user.
PCollection<KV<String, Integer>> sumScores =
userScores.apply("UserSum", Sum.integersPerKey());
// Extract the score from each element, and use it to find the global mean.
final PCollectionView<Double> globalMeanScore =
sumScores.apply(Values.create()).apply(Mean.<Integer>globally().asSingletonView());
// Filter the user sums using the global mean.
PCollection<KV<String, Integer>> filtered =
sumScores.apply(
"ProcessAndFilter",
ParDo
// use the derived mean total score as a side input
.of(
new DoFn<KV<String, Integer>, KV<String, Integer>>() {
private final Counter numSpammerUsers =
Metrics.counter("main", "SpammerUsers");
@ProcessElement
public void processElement(ProcessContext c) {
Integer score = c.element().getValue();
Double gmc = c.sideInput(globalMeanScore);
if (score > (gmc * SCORE_WEIGHT)) {
LOG.info(
"user "
+ c.element().getKey()
+ " spammer score "
+ score
+ " with mean "
+ gmc);
numSpammerUsers.inc();
c.output(c.element());
}
}
})
.withSideInputs(globalMeanScore));
return filtered;
}
}class CalculateSpammyUsers(beam.PTransform):
"""Filter out all but those users with a high clickrate, which we will
consider as 'spammy' users.
We do this by finding the mean total score per user, then using that
information as a side input to filter out all but those user scores that are
larger than (mean * SCORE_WEIGHT).
"""
SCORE_WEIGHT = 2.5
def expand(self, user_scores):
# Get the sum of scores for each user.
sum_scores = (user_scores | 'SumUsersScores' >> beam.CombinePerKey(sum))
# Extract the score from each element, and use it to find the global mean.
global_mean_score = (
sum_scores
| beam.Values()
| beam.CombineGlobally(beam.combiners.MeanCombineFn())\
.as_singleton_view())
# Filter the user sums using the global mean.
filtered = (
sum_scores
# Use the derived mean total score (global_mean_score) as a side input.
| 'ProcessAndFilter' >> beam.Filter(
lambda key_score, global_mean:\
key_score[1] > global_mean * self.SCORE_WEIGHT,
global_mean_score))
return filtered滥用检测转换生成一个可疑垃圾邮件机器人的用户视图。在管道的后面,我们在将分数窗口化到固定窗口并提取团队得分之间使用该视图来过滤掉任何此类用户,同样是通过使用侧输入机制。以下代码示例显示了我们在哪里插入垃圾邮件过滤器,在将分数窗口化到固定窗口并提取团队得分之间
// Calculate the total score per team over fixed windows,
// and emit cumulative updates for late data. Uses the side input derived above-- the set of
// suspected robots-- to filter out scores from those users from the sum.
// Write the results to BigQuery.
rawEvents
.apply(
"WindowIntoFixedWindows",
Window.into(
FixedWindows.of(Duration.standardMinutes(options.getFixedWindowDuration()))))
// Filter out the detected spammer users, using the side input derived above.
.apply(
"FilterOutSpammers",
ParDo.of(
new DoFn<GameActionInfo, GameActionInfo>() {
@ProcessElement
public void processElement(ProcessContext c) {
// If the user is not in the spammers Map, output the data element.
if (c.sideInput(spammersView).get(c.element().getUser().trim()) == null) {
c.output(c.element());
}
}
})
.withSideInputs(spammersView))
// Extract and sum teamname/score pairs from the event data.
.apply("ExtractTeamScore", new ExtractAndSumScore("team"))# Calculate the total score per team over fixed windows, and emit cumulative
# updates for late data. Uses the side input derived above --the set of
# suspected robots-- to filter out scores from those users from the sum.
# Write the results to BigQuery.
( # pylint: disable=expression-not-assigned
raw_events
| 'WindowIntoFixedWindows' >> beam.WindowInto(
beam.window.FixedWindows(fixed_window_duration))
# Filter out the detected spammer users, using the side input derived
# above
| 'FilterOutSpammers' >> beam.Filter(
lambda elem, spammers: elem['user'] not in spammers, spammers_view)
# Extract and sum teamname/score pairs from the event data.
| 'ExtractAndSumScore' >> ExtractAndSumScore('team')分析使用模式
通过检查每个游戏得分的事件时间并将具有相似事件时间的得分分组到会话中,我们可以了解用户何时玩游戏以及玩了多长时间。GameStats 使用 Beam 的内置 会话窗口 函数根据事件发生的时间将用户得分分组到会话中。
设置会话窗口时,您指定事件之间的最小间隔时间。所有到达时间比最小间隔时间更接近的事件都将被分组到同一个窗口中。到达时间差大于间隔的事件将被分组到不同的窗口中。根据我们设置的最小间隔时间,我们可以安全地假设同一个会话窗口中的分数属于相同的(相对)不间断的游戏时间段。不同窗口中的分数表示用户在返回游戏之前至少停止玩游戏了最短间隔时间。
下图展示了数据在分组到会话窗口时可能是什么样子。与固定窗口不同,会话窗口对每个用户来说都是不同的,并且依赖于每个用户的个人游戏模式
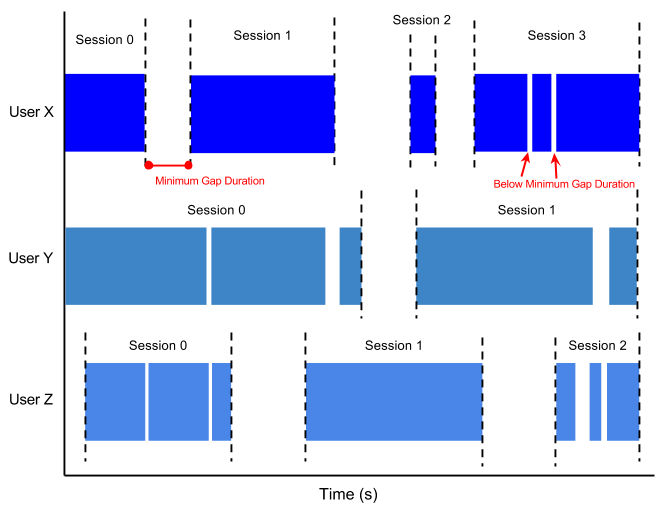
图 6:具有最小间隔时间的用户会话。每个用户都有不同的会话,这取决于他们玩游戏的次数以及他们两次游戏之间的休息时间。
我们可以使用会话窗口数据来确定所有用户的平均不间断游戏时间长度,以及他们在每个会话中取得的总得分。我们可以在代码中通过首先应用会话窗口,对每个用户和会话的得分求和,然后使用转换来计算每个单独会话的长度来做到这一点
// Detect user sessions-- that is, a burst of activity separated by a gap from further
// activity. Find and record the mean session lengths.
// This information could help the game designers track the changing user engagement
// as their set of games changes.
userEvents
.apply(
"WindowIntoSessions",
Window.<KV<String, Integer>>into(
Sessions.withGapDuration(Duration.standardMinutes(options.getSessionGap())))
.withTimestampCombiner(TimestampCombiner.END_OF_WINDOW))
// For this use, we care only about the existence of the session, not any particular
// information aggregated over it, so the following is an efficient way to do that.
.apply(Combine.perKey(x -> 0))
// Get the duration per session.
.apply("UserSessionActivity", ParDo.of(new UserSessionInfoFn()))# Detect user sessions-- that is, a burst of activity separated by a gap
# from further activity. Find and record the mean session lengths.
# This information could help the game designers track the changing user
# engagement as their set of game changes.
( # pylint: disable=expression-not-assigned
user_events
| 'WindowIntoSessions' >> beam.WindowInto(
beam.window.Sessions(session_gap),
timestamp_combiner=beam.window.TimestampCombiner.OUTPUT_AT_EOW)
# For this use, we care only about the existence of the session, not any
# particular information aggregated over it, so we can just group by key
# and assign a "dummy value" of None.
| beam.CombinePerKey(lambda _: None)
# Get the duration of the session
| 'UserSessionActivity' >> beam.ParDo(UserSessionActivity())这将给我们一组用户会话,每个会话都附加了一个持续时间。然后我们可以通过将数据重新窗口化到固定时间窗口,然后计算每个小时结束的所有会话的平均值来计算平均会话长度
// Re-window to process groups of session sums according to when the sessions complete.
.apply(
"WindowToExtractSessionMean",
Window.into(
FixedWindows.of(Duration.standardMinutes(options.getUserActivityWindowDuration()))))
// Find the mean session duration in each window.
.apply(Mean.<Integer>globally().withoutDefaults())
// Write this info to a BigQuery table.
.apply(
"WriteAvgSessionLength",
new WriteWindowedToBigQuery<>(
options.as(GcpOptions.class).getProject(),
options.getDataset(),
options.getGameStatsTablePrefix() + "_sessions",
configureSessionWindowWrite()));# Re-window to process groups of session sums according to when the
# sessions complete
| 'WindowToExtractSessionMean' >> beam.WindowInto(
beam.window.FixedWindows(user_activity_window_duration))
# Find the mean session duration in each window
| beam.CombineGlobally(
beam.combiners.MeanCombineFn()).without_defaults()
| 'FormatAvgSessionLength' >>
beam.Map(lambda elem: {'mean_duration': float(elem)})
| 'WriteAvgSessionLength' >> WriteToBigQuery(
args.table_name + '_sessions',
args.dataset, {
'mean_duration': 'FLOAT',
},
options.view_as(GoogleCloudOptions).project))我们可以使用结果信息来查找,例如,用户玩游戏时间最长的时间段,或者哪段时间更可能看到更短的游戏会话。
下一步
如果您遇到任何问题,请不要犹豫 联系我们!
最后更新时间:2024/10/31
您找到了您要找的所有内容吗?
所有内容是否有用且清晰?您想更改任何内容吗?请告诉我们!