



Apache Beam 概述
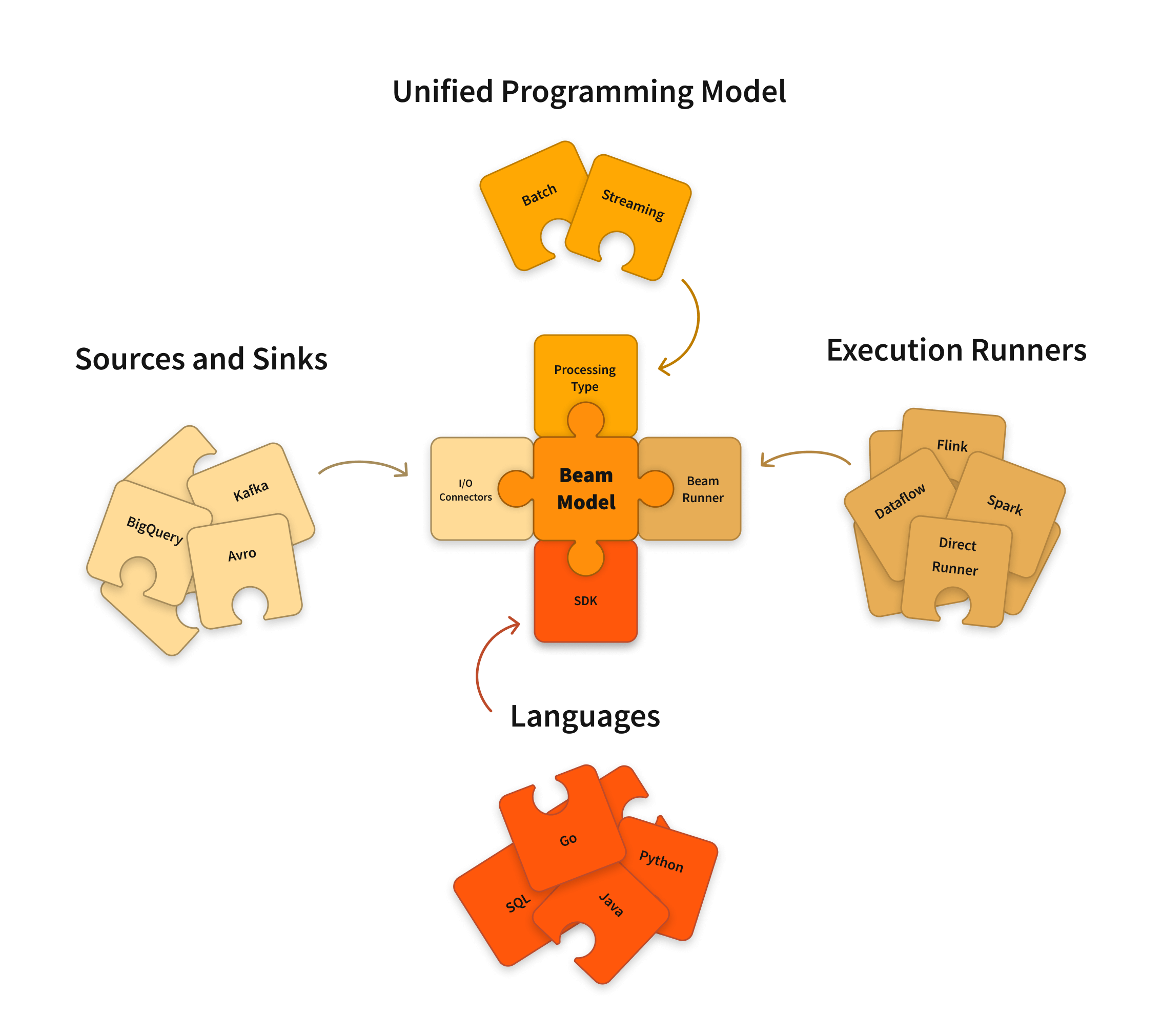
Apache Beam 是一款开源的、统一的模型,用于定义批处理和流式数据并行处理管道。使用一个开源 Beam SDK,您可以构建一个定义管道的程序。然后,管道由 Beam 支持的 分布式处理后端之一执行,包括 Apache Flink、Apache Spark 和 Google Cloud Dataflow。
Beam 特别适用于 容易并行化 的数据处理任务,其中问题可以分解成许多可以独立并行处理的较小数据包。您还可以使用 Beam 进行提取、转换和加载 (ETL) 任务以及纯数据集成。这些任务对于在不同存储介质和数据源之间移动数据、将数据转换为更理想的格式或将数据加载到新系统非常有用。
Apache Beam SDK
Beam SDK 提供了一个统一的编程模型,可以表示和转换任何大小的数据集,无论输入是来自批处理数据源的有限数据集,还是来自流式数据源的无限数据集。Beam SDK 使用相同的类来表示有界和无界数据,以及相同的转换来对这些数据进行操作。您可以使用您选择的 Beam SDK 来构建一个定义数据处理管道的程序。
Beam 目前支持以下语言特定的 SDK



Scala  接口也作为 Scio 提供。
接口也作为 Scio 提供。
Apache Beam Pipeline 运行器
Beam Pipeline 运行器将您使用 Beam 程序定义的数据处理管道转换为与您选择的分布式处理后端兼容的 API。当您运行 Beam 程序时,您需要为要在其中执行管道的后端指定一个 合适的运行器。
Beam 目前支持以下运行器
- Direct Runner
- Apache Flink Runner

- Apache Nemo Runner
- Apache Samza Runner

- Apache Spark Runner

- Google Cloud Dataflow Runner

- Hazelcast Jet Runner

- Twister2 Runner

注意:您始终可以在本地执行管道以进行测试和调试。
开始使用
开始使用 Beam 执行数据处理任务。
如果您已经了解 Apache Spark,请查看我们的 从 Apache Spark 开始使用 页面。
参加 Beam 导览,进行在线交互式学习体验。
按照 Java SDK、Python SDK 或 Go SDK 的快速入门指南操作。
查看 WordCount 示例演练,了解介绍 SDK 各种功能的示例。
通过我们的 学习资源 进行自定进度的导览。
深入 文档 部分,了解有关 Beam 模型、SDK 和运行器的深入概念和参考材料。
深入 cookbook 示例,了解如何在 Dataflow 上运行 Beam。
贡献
Beam 是一个 Apache 软件基金会 项目,根据 Apache v2 许可证提供。Beam 是一个开源社区,非常欢迎贡献!如果您想贡献,请参阅 贡献 部分。
最后更新时间:2024 年 10 月 31 日
您是否找到了您要找的内容?
所有内容都实用且清晰吗?您想更改什么内容?请告诉我们!