



Apache Beam 编程指南
**Beam 编程指南** 面向想要使用 Beam SDK 创建数据处理管道的 Beam 用户。它提供了使用 Beam SDK 类构建和测试管道的指南。编程指南并非旨在作为详尽的参考,而是作为一种与语言无关的、高级的编程构建 Beam 管道的指南。随着编程指南的完善,文本将包含多种语言的代码示例,以帮助说明如何在管道中实现 Beam 概念。
如果您想在阅读编程指南之前简要介绍 Beam 的基本概念,请查看Beam 模型基础页面。
Python SDK 支持 Python 3.8、3.9、3.10、3.11 和 3.12。
The Go SDK 支持 Go v1.20+。
Typescript SDK 支持 Node v16+,目前仍处于实验阶段。
YAML 从 Beam 2.52 开始支持,但仍在积极开发中,建议使用最新版本的 SDK。
1. 概述
要使用 Beam,您需要首先使用 Beam SDK 中的类创建一个驱动程序程序。您的驱动程序程序定义您的管道,包括所有输入、变换和输出;它还为您的管道设置执行选项(通常使用命令行选项传递)。这些选项包括 Pipeline Runner,它反过来决定您的管道将在哪个后端运行。
Beam SDK 提供了许多抽象,简化了大规模分布式数据处理的机制。相同的 Beam 抽象适用于批处理和流数据源。创建 Beam 管道时,您可以从这些抽象的角度考虑数据处理任务。它们包括
Pipeline:Pipeline封装了从头到尾的整个数据处理任务。这包括读取输入数据、转换该数据以及写入输出数据。所有 Beam 驱动程序程序都必须创建一个Pipeline。创建Pipeline时,您还必须指定执行选项,这些选项告诉Pipeline在哪里以及如何运行。PCollection:PCollection表示 Beam 管道操作的分布式数据集。数据集可以是有界的,这意味着它来自固定源(如文件),也可以是无界的,这意味着它来自通过订阅或其他机制不断更新的源。您的管道通常通过从外部数据源读取数据来创建初始PCollection,但您也可以从驱动程序程序中的内存数据创建PCollection。从那里开始,PCollection是管道中每个步骤的输入和输出。PTransform:PTransform表示数据处理操作或管道中的一个步骤。每个PTransform都会接受一个或多个PCollection对象作为输入,对该PCollection元素执行您提供的处理函数,并产生零个或多个输出PCollection对象。
Scope:Go SDK 有一个显式的作用域变量,用于构建Pipeline。Pipeline可以使用Root()方法返回其根作用域。作用域变量传递给PTransform函数,以将其放置在拥有Scope的Pipeline中。
- I/O 变换:Beam 带有许多“IO” - 库
PTransform,用于读取或写入各种外部存储系统的数据。
PCollection 是隐式的(例如,在使用 chain 时),或者由其生成 PTransform 引用。典型的 Beam 驱动程序程序的工作方式如下
- **创建**一个
Pipeline对象并设置管道执行选项,包括 Pipeline Runner。 - 为管道数据创建一个初始
PCollection,方法是使用 IO 从外部存储系统读取数据,或者使用Create变换从内存数据构建PCollection。 - 将
PTransform**应用**于每个PCollection。变换可以更改、筛选、分组、分析或以其他方式处理PCollection中的元素。变换会创建一个新的输出PCollection,不会修改输入集合。典型的管道依次将后续变换应用于每个新的输出PCollection,直到处理完成。但是,请注意,管道不必是依次应用的一系列变换的直线:将PCollection视为变量,将PTransform视为应用于这些变量的函数:管道的形状可以是任意复杂的处理图。 - 使用 IO 将最终的、转换后的
PCollection写入外部源。 - 使用指定的 Pipeline Runner **运行**管道。
运行 Beam 驱动程序程序时,您指定的 Pipeline Runner 会根据您创建的 PCollection 对象和应用的变换,构建您管道的工作流图。然后,该图使用适当的分布式处理后端执行,成为该后端的异步“作业”(或等效项)。
2. 创建管道
Pipeline 抽象封装了数据处理任务中的所有数据和步骤。Beam 驱动程序程序通常从构建一个Pipeline Pipeline Pipeline 对象开始,然后使用该对象作为创建管道的 PCollection 数据集和 Transform 操作的基础。
要使用 Beam,您的驱动程序程序必须首先创建一个 Beam SDK 类 Pipeline 的实例(通常在 main() 函数中)。创建 Pipeline 时,还需要设置一些配置选项。您可以以编程方式设置管道的配置选项,但通常通过提前设置选项(或从命令行读取)并在创建对象时将它们传递给 Pipeline 对象会更容易。
// Start by defining the options for the pipeline.
PipelineOptions options = PipelineOptionsFactory.create();
// Then create the pipeline.
Pipeline p = Pipeline.create(options);import apache_beam as beam
with beam.Pipeline() as pipeline:
pass # build your pipeline here// beam.Init() is an initialization hook that must be called
// near the beginning of main(), before creating a pipeline.
beam.Init()
// Create the Pipeline object and root scope.
pipeline, scope := beam.NewPipelineWithRoot()await beam.createRunner().run(function pipeline(root) {
// Use root to build a pipeline.
});pipeline:
...
options:
...有关在 Python SDK 中创建基本管道的更深入教程,请阅读和完成此 colab 笔记本。
2.1. 配置管道选项
使用管道选项配置管道的不同方面,例如执行管道的管道运行程序以及所选运行程序所需的任何运行程序特定配置。您的管道选项可能会包含项目 ID 或用于存储文件的位置等信息。
在您选择的运行程序上运行管道时,PipelineOptions 的副本将可用于您的代码。例如,如果您将 PipelineOptions 参数添加到 DoFn 的 @ProcessElement 方法中,它将由系统填充。
2.1.1. 从命令行参数设置 PipelineOptions
虽然您可以通过创建 PipelineOptions 对象并直接设置字段来配置管道,但 Beam SDK 包含一个命令行解析器,您可以使用它通过命令行参数在 PipelineOptions 中设置字段。
要从命令行读取选项,请按照以下示例代码中的演示构建 PipelineOptions 对象
使用 Go 标志解析命令行参数以配置您的管道。在调用 beam.Init() 之前必须解析标志。
任何 Javascript 对象都可以用作管道选项。可以手动构建一个,但通常也传递从命令行选项创建的对象,例如 yargs.argv。
管道选项只是与管道定义本身处于同级关系的可选 YAML 映射属性。它将与在命令行上传递的任何选项合并。
PipelineOptions options =
PipelineOptionsFactory.fromArgs(args).withValidation().create();from apache_beam.options.pipeline_options import PipelineOptions
beam_options = PipelineOptions()// If beamx or Go flags are used, flags must be parsed first,
// before beam.Init() is called.
flag.Parse()const pipeline_options = {
runner: "default",
project: "my_project",
};
const runner = beam.createRunner(pipeline_options);
const runnerFromCommandLineOptions = beam.createRunner(yargs.argv);pipeline:
...
options:
my_pipeline_option: my_value
...这将解释遵循以下格式的命令行参数
--<option>=<value>
附加方法
.withValidation将检查必需的命令行参数并验证参数值。
通过这种方式构建 PipelineOptions 使您可以将任何选项指定为命令行参数。
通过这种方式定义标志变量使您可以将任何选项指定为命令行参数。
注意:WordCount 示例管道演示了如何通过使用命令行选项在运行时设置管道选项。
2.1.2. 创建自定义选项
除了标准 PipelineOptions 之外,您还可以添加自己的自定义选项。
要添加自己的选项,请为每个选项定义一个带有 getter 和 setter 方法的接口。
以下示例展示了如何添加input 和 output 自定义选项public interface MyOptions extends PipelineOptions {
String getInput();
void setInput(String input);
String getOutput();
void setOutput(String output);
}from apache_beam.options.pipeline_options import PipelineOptions
class MyOptions(PipelineOptions):
@classmethod
def _add_argparse_args(cls, parser):
parser.add_argument('--input')
parser.add_argument('--output')// Use standard Go flags to define pipeline options.
var (
input = flag.String("input", "", "")
output = flag.String("output", "", "")
)const options = yargs.argv; // Or an alternative command-line parsing library.
// Use options.input and options.output during pipeline construction.
您还可以指定说明,该说明会在用户传递 --help 作为命令行参数时出现,以及默认值。
您可以使用注释设置说明和默认值,如下所示
public interface MyOptions extends PipelineOptions {
@Description("Input for the pipeline")
@Default.String("gs://my-bucket/input")
String getInput();
void setInput(String input);
@Description("Output for the pipeline")
@Default.String("gs://my-bucket/output")
String getOutput();
void setOutput(String output);
}from apache_beam.options.pipeline_options import PipelineOptions
class MyOptions(PipelineOptions):
@classmethod
def _add_argparse_args(cls, parser):
parser.add_argument(
'--input',
default='gs://dataflow-samples/shakespeare/kinglear.txt',
help='The file path for the input text to process.')
parser.add_argument(
'--output', required=True, help='The path prefix for output files.')var (
input = flag.String("input", "gs://my-bucket/input", "Input for the pipeline")
output = flag.String("output", "gs://my-bucket/output", "Output for the pipeline")
)对于 Python,您也可以简单地使用 argparse 解析自定义选项;无需创建单独的 PipelineOptions 子类。
建议您使用 PipelineOptionsFactory 注册接口,然后在创建 PipelineOptions 对象时传递接口。使用 PipelineOptionsFactory 注册接口时,--help 可以找到您的自定义选项接口并将其添加到 --help 命令的输出中。PipelineOptionsFactory 还将验证您的自定义选项是否与所有其他已注册选项兼容。
以下示例代码展示了如何使用 PipelineOptionsFactory 注册自定义选项接口
PipelineOptionsFactory.register(MyOptions.class);
MyOptions options = PipelineOptionsFactory.fromArgs(args)
.withValidation()
.as(MyOptions.class);现在,您的管道可以接受 --input=value 和 --output=value 作为命令行参数。
3. PCollections
The PCollection PCollection PCollection 抽象表示一个可能分布式、多元素的数据集。您可以将 PCollection 视为“管道”数据;Beam 变换使用 PCollection 对象作为输入和输出。因此,如果您想在管道中使用数据,则它必须采用 PCollection 的形式。
创建 Pipeline 后,您需要通过某种方式开始创建至少一个 PCollection。您创建的 PCollection 作为管道中第一个操作的输入。
3.1. 创建 PCollection
您可以通过以下两种方式创建 PCollection:使用 Beam 的 Source API 从外部数据源读取数据,或者在您的驱动程序中创建包含内存中集合类数据的 PCollection。前者通常是生产管道摄取数据的方式;Beam 的 Source API 包含适配器,可以帮助您从外部数据源(如大型基于云的文件、数据库或订阅服务)读取数据。后者主要用于测试和调试目的。
3.1.1. 从外部来源读取
要从外部数据源读取数据,您需要使用一个 Beam 提供的 I/O 适配器。适配器在具体用法上有所不同,但它们都会从某个外部数据源读取数据,并返回一个 PCollection,其元素代表该数据源中的数据记录。
每个数据源适配器都有一个 Read 变换;要读取数据,您必须将该变换应用于 Pipeline 对象本身。 将此变换放在管道的 source 或 transforms 部分。 TextIO.Read io.TextFileSource textio.Read textio.ReadFromText,ReadFromText,例如,从外部文本文件读取数据,并返回一个 PCollection,其元素 的类型为 String,其中每个 String 代表文本文件中的一个行。以下是如何将 TextIO.Read io.TextFileSource textio.Read textio.ReadFromText ReadFromText 应用于您的 Pipeline root 以创建 PCollection 的示例:
public static void main(String[] args) {
// Create the pipeline.
PipelineOptions options =
PipelineOptionsFactory.fromArgs(args).create();
Pipeline p = Pipeline.create(options);
// Create the PCollection 'lines' by applying a 'Read' transform.
PCollection<String> lines = p.apply(
"ReadMyFile", TextIO.read().from("gs://some/inputData.txt"));
}lines = pipeline | 'ReadMyFile' >> beam.io.ReadFromText(
'gs://some/inputData.txt')// Read the file at the URI 'gs://some/inputData.txt' and return
// the lines as a PCollection<string>.
// Notice the scope as the first variable when calling
// the method as is needed when calling all transforms.
lines := textio.Read(scope, "gs://some/inputData.txt")async function pipeline(root: beam.Root) {
// Note that textio.ReadFromText is an AsyncPTransform.
const pcoll: PCollection<string> = await root.applyAsync(
textio.ReadFromText("path/to/text_pattern")
);
}pipeline:
source:
type: ReadFromText
config:
path: ...请参阅 有关 I/O 的部分,以了解有关如何从 Beam SDK 支持的各种数据源读取数据的更多信息。
3.1.2. 从内存数据创建 PCollection
要从内存中的 Java Collection 创建 PCollection,您需要使用 Beam 提供的 Create 变换。与数据适配器的 Read 非常相似,您将 Create 直接应用于 Pipeline 对象本身。
作为参数,Create 接受 Java Collection 和 Coder 对象。Coder 指定了如何 编码 Collection 中的元素。
要从内存中的 list 创建 PCollection,您需要使用 Beam 提供的 Create 变换。将此变换直接应用于 Pipeline 对象本身。
要从内存中的 slice 创建 PCollection,您需要使用 Beam 提供的 beam.CreateList 变换。将管道 scope 和 slice 传递给此变换。
要从内存中的 array 创建 PCollection,您需要使用 Beam 提供的 Create 变换。将此变换直接应用于 Root 对象。
要从内存中的 array 创建 PCollection,您需要使用 Beam 提供的 Create 变换。在管道本身中指定元素。
以下代码示例展示了如何从内存中的 List list slice array 创建 PCollection。
public static void main(String[] args) {
// Create a Java Collection, in this case a List of Strings.
final List<String> LINES = Arrays.asList(
"To be, or not to be: that is the question: ",
"Whether 'tis nobler in the mind to suffer ",
"The slings and arrows of outrageous fortune, ",
"Or to take arms against a sea of troubles, ");
// Create the pipeline.
PipelineOptions options =
PipelineOptionsFactory.fromArgs(args).create();
Pipeline p = Pipeline.create(options);
// Apply Create, passing the list and the coder, to create the PCollection.
p.apply(Create.of(LINES)).setCoder(StringUtf8Coder.of());
}import apache_beam as beam
with beam.Pipeline() as pipeline:
lines = (
pipeline
| beam.Create([
'To be, or not to be: that is the question: ',
"Whether 'tis nobler in the mind to suffer ",
'The slings and arrows of outrageous fortune, ',
'Or to take arms against a sea of troubles, ',
]))lines := []string{
"To be, or not to be: that is the question: ",
"Whether 'tis nobler in the mind to suffer ",
"The slings and arrows of outrageous fortune, ",
"Or to take arms against a sea of troubles, ",
}
// Create the Pipeline object and root scope.
// It's conventional to use p as the Pipeline variable and
// s as the scope variable.
p, s := beam.NewPipelineWithRoot()
// Pass the slice to beam.CreateList, to create the pcollection.
// The scope variable s is used to add the CreateList transform
// to the pipeline.
linesPCol := beam.CreateList(s, lines)function pipeline(root: beam.Root) {
const pcoll = root.apply(
beam.create([
"To be, or not to be: that is the question: ",
"Whether 'tis nobler in the mind to suffer ",
"The slings and arrows of outrageous fortune, ",
"Or to take arms against a sea of troubles, ",
])
);
}pipeline:
transforms:
- type: Create
config:
elements:
- A
- B
- ...3.2. PCollection 特性
PCollection 由其创建的特定 Pipeline 对象拥有;多个管道不能共享一个 PCollection。 在某种程度上,PCollection 的功能类似于 Collection 类。但是,PCollection 在几个关键方面有所不同:
3.2.1. 元素类型
PCollection 的元素可以是任何类型,但必须都是相同的类型。但是,为了支持分布式处理,Beam 需要能够将每个单独的元素编码为字节字符串(以便可以将元素传递到分布式工作器)。Beam SDK 提供了数据编码机制,其中包含对常用类型的内置编码以及对根据需要指定自定义编码的支持。
3.2.2. 元素模式
在许多情况下,PCollection 中的元素类型具有可以内省的结构。例如 JSON、Protocol Buffer、Avro 和数据库记录。模式提供了一种将类型表示为一组命名字段的方式,从而允许进行更具表达性的聚合。
3.2.3. 不可变性
PCollection 是不可变的。创建后,您不能添加、删除或更改单个元素。Beam 变换可能会处理 PCollection 的每个元素并生成新的管道数据(作为新的 PCollection),但它不会使用或修改原始输入集合。
注意: Beam SDK 避免了对元素的不必要复制,因此
PCollection的内容在逻辑上是不可变的,而不是物理上不可变的。对输入元素的更改可能对在同一捆绑包中执行的其他 DoFns 可见,并且可能会导致正确性问题。通常,修改提供给 DoFns 的值是不安全的。
3.2.4. 随机访问
PCollection 不支持对单个元素的随机访问。相反,Beam 变换会单独考虑 PCollection 中的每个元素。
3.2.5. 大小和有界性
PCollection 是一个大型的、不可变的元素“集合”。PCollection 可以包含的元素数量没有上限;任何给定的 PCollection 都可能适合在一台机器上的内存中,或者它可能代表一个非常大的分布式数据集,该数据集由持久性数据存储支持。
PCollection 的大小可以是有界的,也可以是无界的。有界 PCollection 代表一个已知固定大小的数据集,而无界 PCollection 代表一个无限大小的数据集。PCollection 是有界还是无界取决于它代表的数据集的来源。从批处理数据源(如文件或数据库)读取数据会创建有界 PCollection。从流式数据源或持续更新的数据源(如 Pub/Sub 或 Kafka)读取数据会创建无界 PCollection(除非您明确告诉它不要这样做)。
PCollection 的有界(或无界)性质会影响 Beam 处理数据的方式。有界 PCollection 可以使用批处理作业进行处理,该作业可能会读取整个数据集一次,并在有限长度的作业中执行处理。无界 PCollection 必须使用持续运行的流式作业进行处理,因为整个集合永远不可能在任何时间点都可用以进行处理。
Beam 使用 窗口化 将持续更新的无界 PCollection 分为有限大小的逻辑窗口。这些逻辑窗口由与数据元素相关联的某些特征确定,例如时间戳。聚合变换(如 GroupByKey 和 Combine)按窗口为单位工作——随着数据集的生成,它们将每个 PCollection 处理为这些有限窗口的连续序列。
3.2.6. 元素时间戳
PCollection 中的每个元素都具有关联的内在时间戳。每个元素的时间戳最初由创建 PCollection 的 Source 分配。创建无界 PCollection 的源通常会为每个新元素分配一个时间戳,该时间戳对应于读取或添加元素的时间。
注意:为固定数据集创建有界
PCollection的源也会自动分配时间戳,但最常见的行为是为每个元素分配相同的时间戳(Long.MIN_VALUE)。
时间戳对于包含具有固有时序概念的元素的 PCollection 非常有用。如果您的管道正在读取事件流,例如推文或其他社交媒体消息,则每个元素可能使用事件发布的时间作为元素时间戳。
如果源没有为您分配时间戳,您可以手动将时间戳分配给 PCollection 的元素。如果您需要这样做,则元素本身具有固有的时间戳,但时间戳位于元素结构中的某个地方(例如服务器日志条目中的“时间”字段)。Beam 有 变换,它们以 PCollection 作为输入,并输出具有附加时间戳的相同 PCollection;有关如何执行此操作的更多信息,请参阅 添加时间戳。
4. 转换
变换是管道中的操作,并提供了一个通用的处理框架。您以函数对象的形式提供处理逻辑(俗称“用户代码”),并且您的用户代码将应用于输入 PCollection(或多个 PCollection)的每个元素。根据您选择的管道运行器和后端,集群中的许多不同的工作器可能会并行执行用户代码的实例。在每个工作器上运行的用户代码将生成最终添加到变换生成的最终输出 PCollection 中的输出元素。
在学习 Beam 的变换时,聚合是一个重要的概念。有关聚合的介绍,请参阅 Beam 模型基础知识 聚合部分。
Beam SDK 包含许多不同的变换,您可以将它们应用于管道的 PCollection。这些变换包括通用核心变换,例如 ParDo 或 Combine。SDK 中还包含预先编写的 组合变换,它们将一个或多个核心变换组合在有用的处理模式中,例如计算集合中的元素或将它们组合在一起。您还可以定义自己的更复杂的组合变换,以满足您的管道的确切用例。
有关在 Python SDK 中应用各种变换的更深入教程,请阅读并完成 此 Colab 笔记本。
4.1. 应用转换
要调用变换,您必须将其应用于输入 PCollection。Beam SDK 中的每个变换都有一个通用的 apply 方法(或管道运算符 |)。调用多个 Beam 变换类似于方法链接,但有一个细微的差别:您将变换应用于输入 PCollection,并将变换本身作为参数传递,操作将返回输出 PCollection。 array 在 YAML 中,通过列出变换的输入来应用变换。这采用以下一般形式:
[Output PCollection] = [Input PCollection].apply([Transform])[Output PCollection] = [Input PCollection] | [Transform][Output PCollection] := beam.ParDo(scope, [Transform], [Input PCollection])[Output PCollection] = [Input PCollection].apply([Transform])
[Output PCollection] = await [Input PCollection].applyAsync([AsyncTransform])pipeline:
transforms:
...
- name: ProducingTransform
type: ProducingTransformType
...
- name: MyTransform
type: MyTransformType
input: ProducingTransform
...如果变换有多个 (非错误) 输出,则可以通过明确给出输出名称来标识各个输出。
pipeline:
transforms:
...
- name: ProducingTransform
type: ProducingTransformType
...
- name: MyTransform
type: MyTransformType
input: ProducingTransform.output_name
...
- name: MyTransform
type: MyTransformType
input: ProducingTransform.another_output_name
...对于线性管道,可以通过根据变换的顺序隐式确定输入(通过指定类型为 chain)来进一步简化此操作。例如:
pipeline:
type: chain
transforms:
- name: ProducingTransform
type: ReadTransform
config: ...
- name: MyTransform
type: MyTransformType
config: ...
- name: ConsumingTransform
type: WriteTransform
config: ...由于 Beam 使用通用的 apply 方法用于 PCollection,因此您可以将变换按顺序链接在一起,也可以应用包含其他变换的嵌套变换(在 Beam SDK 中称为 组合变换)。
建议为每个新的 PCollection 创建一个新变量,以按顺序转换输入数据。Scope 可用于创建包含其他变换的函数(在 Beam SDK 中称为 组合变换)。
您应用管道变换的方式决定了管道的结构。将管道视为有向无环图是最好的方式,其中 PTransform 节点是子例程,它们接受 PCollection 节点作为输入,并发出 PCollection 节点作为输出。 例如,您可以将变换链接在一起以创建一个管道,该管道会依次修改输入数据: 例如,您可以依次对 PCollections 调用变换以修改输入数据:
[Final Output PCollection] = [Initial Input PCollection].apply([First Transform])
.apply([Second Transform])
.apply([Third Transform])[Final Output PCollection] = ([Initial Input PCollection] | [First Transform]
| [Second Transform]
| [Third Transform])[Second PCollection] := beam.ParDo(scope, [First Transform], [Initial Input PCollection])
[Third PCollection] := beam.ParDo(scope, [Second Transform], [Second PCollection])
[Final Output PCollection] := beam.ParDo(scope, [Third Transform], [Third PCollection])[Final Output PCollection] = [Initial Input PCollection].apply([First Transform])
.apply([Second Transform])
.apply([Third Transform])此管道的图形如下所示:

图 1:包含三个顺序转换的线性管道。
但是,请注意,转换*不会消耗或以其他方式改变*输入集合 - 请记住,根据定义,PCollection 是不可变的。这意味着您可以对同一个输入 PCollection 应用多个转换来创建一个分支管道,如下所示
[PCollection of database table rows] = [Database Table Reader].apply([Read Transform])
[PCollection of 'A' names] = [PCollection of database table rows].apply([Transform A])
[PCollection of 'B' names] = [PCollection of database table rows].apply([Transform B])[PCollection of database table rows] = [Database Table Reader] | [Read Transform]
[PCollection of 'A' names] = [PCollection of database table rows] | [Transform A]
[PCollection of 'B' names] = [PCollection of database table rows] | [Transform B][PCollection of database table rows] = beam.ParDo(scope, [Read Transform], [Database Table Reader])
[PCollection of 'A' names] = beam.ParDo(scope, [Transform A], [PCollection of database table rows])
[PCollection of 'B' names] = beam.ParDo(scope, [Transform B], [PCollection of database table rows])[PCollection of database table rows] = [Database Table Reader].apply([Read Transform])
[PCollection of 'A' names] = [PCollection of database table rows].apply([Transform A])
[PCollection of 'B' names] = [PCollection of database table rows].apply([Transform B])此分支管道的图形如下所示

图 2:分支管道。两个转换应用于单个包含数据库表行的 PCollection。
您还可以构建自己的复合转换,将多个转换嵌套在一个更大的转换中。复合转换对于构建可重用的一系列简单步骤特别有用,这些步骤在许多不同的地方使用。
管道语法允许将 PTransform 应用于 tuple 和 dict 的 PCollection,以用于接受多个输入的那些转换(例如 Flatten 和 CoGroupByKey)。
PTransform 也可以应用于任何 PValue,其中包括 Root 对象、PCollection、PValue 数组以及具有 PValue 值的对象。可以通过用 beam.P 包装它们来将转换应用于这些复合类型,例如 beam.P({left: pcollA, right: pcollB}).apply(transformExpectingTwoPCollections)。
PTransform 有两种类型,同步和异步,具体取决于其应用*是否涉及异步调用。AsyncTransform 必须使用 applyAsync 应用,并返回一个 Promise,该 Promise 必须在进一步的管道构建之前等待。
4.2. 核心 Beam 转换
Beam 提供以下核心转换,每个转换代表不同的处理范式
ParDoGroupByKeyCoGroupByKeyCombineFlattenPartition
Typescript SDK 提供了其中一些最基本的转换,作为 PCollection 本身的函数。
4.2.1. ParDo
ParDo 是 Beam 转换,用于通用并行处理。ParDo 处理范式类似于 Map/Shuffle/Reduce 风格算法的“Map”阶段:ParDo 转换会考虑输入 PCollection 中的每个元素,对该元素执行一些处理函数(您的用户代码),并向输出 PCollection 发射零个、一个或多个元素。
ParDo 可用于各种常见的 数据处理操作,包括
- 过滤数据集。您可以使用
ParDo来考虑PCollection中的每个元素,并将该元素输出到一个新的集合中或将其丢弃。 - 格式化或类型转换数据集中的每个元素。如果您的输入
PCollection包含类型或格式与您想要的不同的元素,您可以使用ParDo对每个元素执行转换并将结果输出到一个新的PCollection。 - 从数据集中的每个元素中提取部分。例如,如果您有一个包含多个字段的记录的
PCollection,您可以使用ParDo将您要考虑的字段解析到一个新的PCollection中。 - 对数据集中的每个元素执行计算。您可以使用
ParDo对PCollection的每个元素或某些元素执行简单或复杂的计算,并将结果输出为新的PCollection。
在这样的角色中,ParDo 是管道中常见的中间步骤。您可能会使用它从一组原始输入记录中提取特定字段,或将原始输入转换为不同的格式;您也可以使用 ParDo 将处理后的数据转换为适合输出的格式,例如数据库表行或可打印的字符串。
当您应用 ParDo 转换时,您需要以 DoFn 对象的形式提供用户代码。DoFn 是一个 Beam SDK 类,用于定义分布式处理函数。
在 Beam YAML 中,ParDo 操作由 MapToFields、Filter 和 Explode 转换类型表示。这些类型可以接受您选择的语言中的 UDF,而不是引入 DoFn 的概念。有关更多详细信息,请参阅关于映射函数的页面。
当您创建
DoFn的子类时,请注意,您的子类应遵守编写 Beam 转换用户代码的要求。
所有 DoFns 应使用通用 register.DoFnXxY[...] 函数注册。这允许 Go SDK 从任何输入/输出推断编码,注册 DoFn 以在远程运行器上执行,并通过反射优化 DoFns 的运行时执行。
// ComputeWordLengthFn is a DoFn that computes the word length of string elements.
type ComputeWordLengthFn struct{}
// ProcessElement computes the length of word and emits the result.
// When creating structs as a DoFn, the ProcessElement method performs the
// work of this step in the pipeline.
func (fn *ComputeWordLengthFn) ProcessElement(ctx context.Context, word string) int {
...
}
func init() {
// 2 inputs and 1 output => DoFn2x1
// Input/output types are included in order in the brackets
register.DoFn2x1[context.Context, string, int](&ComputeWordLengthFn{})
}4.2.1.1. 应用 ParDo
与所有 Beam 转换一样,您可以通过在输入 PCollection 上调用 apply 方法并将 ParDo 作为参数传递来应用 ParDo,如以下示例代码所示
与所有 Beam 转换一样,您可以通过在输入 PCollection 上调用 beam.ParDo 并将 DoFn 作为参数传递来应用 ParDo,如以下示例代码所示
beam.ParDo 将传入的 DoFn 参数应用于输入 PCollection,如以下示例代码所示
// The input PCollection of Strings.
PCollection<String> words = ...;
// The DoFn to perform on each element in the input PCollection.
static class ComputeWordLengthFn extends DoFn<String, Integer> { ... }
// Apply a ParDo to the PCollection "words" to compute lengths for each word.
PCollection<Integer> wordLengths = words.apply(
ParDo
.of(new ComputeWordLengthFn())); // The DoFn to perform on each element, which
// we define above.
# The input PCollection of Strings.
words = ...
# The DoFn to perform on each element in the input PCollection.
class ComputeWordLengthFn(beam.DoFn):
def process(self, element):
return [len(element)]
# Apply a ParDo to the PCollection "words" to compute lengths for each word.
word_lengths = words | beam.ParDo(ComputeWordLengthFn())// ComputeWordLengthFn is the DoFn to perform on each element in the input PCollection.
type ComputeWordLengthFn struct{}
// ProcessElement is the method to execute for each element.
func (fn *ComputeWordLengthFn) ProcessElement(word string, emit func(int)) {
emit(len(word))
}
// DoFns must be registered with beam.
func init() {
beam.RegisterType(reflect.TypeOf((*ComputeWordLengthFn)(nil)))
// 2 inputs and 0 outputs => DoFn2x0
// 1 input => Emitter1
// Input/output types are included in order in the brackets
register.DoFn2x0[string, func(int)](&ComputeWordLengthFn{})
register.Emitter1[int]()
}
// words is an input PCollection of strings
var words beam.PCollection = ...
wordLengths := beam.ParDo(s, &ComputeWordLengthFn{}, words)# The input PCollection of Strings.
const words : PCollection<string> = ...
# The DoFn to perform on each element in the input PCollection.
function computeWordLengthFn(): beam.DoFn<string, number> {
return {
process: function* (element) {
yield element.length;
},
};
}
const result = words.apply(beam.parDo(computeWordLengthFn()));在本例中,我们的输入 PCollection 包含 String string 值。我们应用了一个 ParDo 转换,该转换指定一个函数(ComputeWordLengthFn)来计算每个字符串的长度,并将结果输出到一个新的 PCollection,其中包含 Integer int 值,用于存储每个单词的长度。
4.2.1.2. 创建 DoFn
您传递给 ParDo 的 DoFn 对象包含应用于输入集合中元素的处理逻辑。当您使用 Beam 时,您编写的最重要的代码通常是这些 DoFn - 它们定义了管道的精确数据处理任务。
注意:当您创建
DoFn时,请注意编写 Beam 转换用户代码的要求,并确保您的代码遵循这些要求。您应该避免在DoFn.Setup中进行耗时的操作,例如读取大型文件。
DoFn 从输入 PCollection 中一次处理一个元素。当您创建 DoFn 的子类时,您需要提供与输入和输出元素类型匹配的类型参数。如果您的 DoFn 处理传入的 String 元素并为输出集合生成 Integer 元素(例如我们之前的示例 ComputeWordLengthFn),您的类声明将如下所示
DoFn 从输入 PCollection 中一次处理一个元素。当您创建 DoFn 结构时,您需要提供与 ProcessElement 方法中输入和输出元素类型匹配的类型参数。如果您的 DoFn 处理传入的 string 元素并为输出集合生成 int 元素(例如我们之前的示例 ComputeWordLengthFn),您的 dofn 可能如下所示
static class ComputeWordLengthFn extends DoFn<String, Integer> { ... }// ComputeWordLengthFn is a DoFn that computes the word length of string elements.
type ComputeWordLengthFn struct{}
// ProcessElement computes the length of word and emits the result.
// When creating structs as a DoFn, the ProcessElement method performs the
// work of this step in the pipeline.
func (fn *ComputeWordLengthFn) ProcessElement(word string, emit func(int)) {
...
}
func init() {
// 2 inputs and 0 outputs => DoFn2x0
// 1 input => Emitter1
// Input/output types are included in order in the brackets
register.Function2x0(&ComputeWordLengthFn{})
register.Emitter1[int]()
}在您的 DoFn 子类中,您将编写一个用 @ProcessElement 注释的方法,您将在其中提供实际的处理逻辑。您无需手动从输入集合中提取元素;Beam SDK 会为您处理。您的 @ProcessElement 方法应接受一个用 @Element 标记的参数,该参数将用输入元素填充。为了输出元素,该方法还可以接受一个类型为 OutputReceiver 的参数,该参数提供一个用于发射元素的方法。参数类型必须与您的 DoFn 的输入和输出类型匹配,否则框架将引发错误。注意:@Element 和 OutputReceiver 是在 Beam 2.5.0 中引入的;如果使用早期版本的 Beam,应改用 ProcessContext 参数。
在您的 DoFn 子类中,您将编写一个 process 方法,您将在其中提供实际的处理逻辑。您无需手动从输入集合中提取元素;Beam SDK 会为您处理。您的 process 方法应接受一个参数 element,它是输入元素,并返回一个包含其输出值的迭代器。您可以通过使用 yield 语句发射单个元素来实现这一点,并使用 yield from 来发射来自迭代器(例如列表或生成器)的所有元素。使用包含迭代器的 return 语句也是可以接受的,只要您不要在同一个 process 方法中混合 yield 和 return 语句,因为这会导致不正确行为。
对于您的 DoFn 类型,您将编写一个 ProcessElement 方法,您将在其中提供实际的处理逻辑。您无需手动从输入集合中提取元素;Beam SDK 会为您处理。您的 ProcessElement 方法应接受一个参数 element,它是输入元素。为了输出元素,该方法还可以接受一个函数参数,该参数可以被调用以发射元素。参数类型必须与您的 DoFn 的输入和输出类型匹配,否则框架将引发错误。
static class ComputeWordLengthFn extends DoFn<String, Integer> {
@ProcessElement
public void processElement(@Element String word, OutputReceiver<Integer> out) {
// Use OutputReceiver.output to emit the output element.
out.output(word.length());
}
}class ComputeWordLengthFn(beam.DoFn):
def process(self, element):
return [len(element)]// ComputeWordLengthFn is the DoFn to perform on each element in the input PCollection.
type ComputeWordLengthFn struct{}
// ProcessElement is the method to execute for each element.
func (fn *ComputeWordLengthFn) ProcessElement(word string, emit func(int)) {
emit(len(word))
}
// DoFns must be registered with beam.
func init() {
beam.RegisterType(reflect.TypeOf((*ComputeWordLengthFn)(nil)))
// 2 inputs and 0 outputs => DoFn2x0
// 1 input => Emitter1
// Input/output types are included in order in the brackets
register.DoFn2x0[string, func(int)](&ComputeWordLengthFn{})
register.Emitter1[int]()
}function computeWordLengthFn(): beam.DoFn<string, number> {
return {
process: function* (element) {
yield element.length;
},
};
}简单的 DoFns 也可以编写为函数。
func ComputeWordLengthFn(word string, emit func(int)) { ... }
func init() {
// 2 inputs and 0 outputs => DoFn2x0
// 1 input => Emitter1
// Input/output types are included in order in the brackets
register.DoFn2x0[string, func(int)](&ComputeWordLengthFn{})
register.Emitter1[int]()
}注意:无论使用结构化
DoFn类型还是函数式DoFn,都应在init块中向 beam 注册它们。否则它们可能无法在分布式运行器上执行。
注意:如果输入
PCollection中的元素是键值对,您可以分别使用element.getKey()或element.getValue()来访问键或值。
注意:如果输入
PCollection中的元素是键值对,您的 process element 方法必须分别有两个参数,用于每个键和值。类似地,键值对也作为单独的参数输出到单个发射器函数。
给定的 DoFn 实例通常会被调用一次或多次以处理一些任意元素包。但是,Beam 并不保证确切的调用次数;它可能会在给定的工作节点上多次调用它,以解决故障和重试问题。因此,您可以跨多个调用缓存信息到您的处理方法,但如果这样做,请确保实现不依赖于调用次数。
在您的处理方法中,您还需要满足一些不变性要求,以确保 Beam 和处理后端可以安全地序列化和缓存管道中的值。您的方法应满足以下要求
- 您不应该以任何方式修改
@Element注释或ProcessContext.sideInput()(来自输入集合的传入元素)返回的元素。 - 一旦您使用
OutputReceiver.output()输出了一个值,您就不应该以任何方式修改该值。
- 您不应该以任何方式修改提供给
process方法的element参数,或任何侧输入。 - 一旦您使用
yield或return输出了一个值,您就不应该以任何方式修改该值。
- 您不应该以任何方式修改提供给
ProcessElement方法的参数,或任何侧输入。 - 一旦您使用
发射器函数输出了一个值,您就不应该以任何方式修改该值。
4.2.1.3. 轻量级 DoFns 和其他抽象
如果您的函数相对简单,您可以通过提供一个轻量级的ParDo来简化您的使用DoFn,就像匿名内部类实例 一个 lambda 函数 一个匿名函数 传递给PCollection.map或PCollection.flatMap的函数。
以下是之前的示例,ParDo使用ComputeLengthWordsFn,其中DoFn指定为匿名内部类实例 一个 lambda 函数 一个匿名函数 一个函数
// The input PCollection.
PCollection<String> words = ...;
// Apply a ParDo with an anonymous DoFn to the PCollection words.
// Save the result as the PCollection wordLengths.
PCollection<Integer> wordLengths = words.apply(
"ComputeWordLengths", // the transform name
ParDo.of(new DoFn<String, Integer>() { // a DoFn as an anonymous inner class instance
@ProcessElement
public void processElement(@Element String word, OutputReceiver<Integer> out) {
out.output(word.length());
}
}));# The input PCollection of strings.
words = ...
# Apply a lambda function to the PCollection words.
# Save the result as the PCollection word_lengths.
word_lengths = words | beam.FlatMap(lambda word: [len(word)])The Go SDK cannot support anonymous functions outside of the deprecated Go Direct runner.
// words is the input PCollection of strings
var words beam.PCollection = ...
lengths := beam.ParDo(s, func (word string, emit func(int)) {
emit(len(word))
}, words)// The input PCollection of strings.
words = ...
const result = words.flatMap((word) => [word.length]);如果您的ParDo对输入元素进行一对一映射到输出元素 - 也就是说,对于每个输入元素,它应用一个产生正好一个输出元素的函数,您可以直接返回该元素。您可以使用更高级的MapElementsMap转换。MapElements可以接受一个匿名的 Java 8 lambda 函数,以获得更简洁的代码。
以下是使用MapElements Map直接返回的先前示例。
// The input PCollection.
PCollection<String> words = ...;
// Apply a MapElements with an anonymous lambda function to the PCollection words.
// Save the result as the PCollection wordLengths.
PCollection<Integer> wordLengths = words.apply(
MapElements.into(TypeDescriptors.integers())
.via((String word) -> word.length()));# The input PCollection of string.
words = ...
# Apply a Map with a lambda function to the PCollection words.
# Save the result as the PCollection word_lengths.
word_lengths = words | beam.Map(len)The Go SDK cannot support anonymous functions outside of the deprecated Go Direct runner.
func wordLengths(word string) int { return len(word) }
func init() { register.Function1x1(wordLengths) }
func applyWordLenAnon(s beam.Scope, words beam.PCollection) beam.PCollection {
return beam.ParDo(s, wordLengths, words)
}// The input PCollection of string.
words = ...
const result = words.map((word) => word.length);注意: 您可以将 Java 8 lambda 函数与其他几个 Beam 转换一起使用,包括
Filter、FlatMapElements和Partition。
注意: 匿名函数 DoFn 不适用于分布式运行器。建议使用命名函数并在
init()块中使用register.FunctionXxY注册它们。
4.2.1.4. DoFn 生命周期
这是一个序列图,它显示了 DoFn 在执行 ParDo 转换期间的生命周期。注释为管道开发人员提供了有用的信息,例如适用于对象的约束或特定情况,例如故障转移或实例重用。它们还提供了实例化用例。需要注意的三个关键点是
- 拆卸是尽力而为的,因此不能保证。
- 在运行时创建的 DoFn 实例数量取决于运行器。
- 对于 Python SDK,管道内容(如 DoFn 用户代码)被序列化为字节码。因此,
DoFn不应该引用不可序列化的对象,例如锁。要在同一进程中的多个DoFn实例之间管理对象的单个实例,请使用shared.py模块中的实用程序。

4.2.2. GroupByKey
GroupByKey 是一个 Beam 转换,用于处理键值对集合。它是一个并行归约操作,类似于 Map/Shuffle/Reduce 样式算法的 Shuffle 阶段。GroupByKey的输入是键值对的集合,表示一个多映射,其中集合包含多个具有相同键但值不同的对。给定这样一个集合,您可以使用GroupByKey收集与每个唯一键关联的所有值。
GroupByKey是聚合具有共同特征数据的良好方法。例如,如果您有一个存储客户订单记录的集合,您可能希望将来自同一邮政编码的所有订单分组在一起(其中键值对的“键”是邮政编码字段,“值”是记录的其余部分)。
让我们通过一个简单的示例用例来检查GroupByKey的机制,其中我们的数据集包含来自文本文件中的单词及其出现的行号。我们希望将共享相同单词(键)的所有行号(值)分组在一起,让我们可以看到文本中特定单词出现的所有位置。
我们的输入是一个键值对的PCollection,其中每个单词都是一个键,值是在文件中单词出现的那一行号。以下是输入集合中键值对的列表
cat, 1
dog, 5
and, 1
jump, 3
tree, 2
cat, 5
dog, 2
and, 2
cat, 9
and, 6
...
GroupByKey收集具有相同键的所有值,并输出一个新的对,该对包含唯一的键和与输入集合中该键关联的所有值的集合。如果我们将GroupByKey应用于我们上面的输入集合,输出集合将如下所示
cat, [1,5,9]
dog, [5,2]
and, [1,2,6]
jump, [3]
tree, [2]
...
因此,GroupByKey表示从多映射(多个键到单个值)到单映射(唯一键到值集合)的转换。
使用GroupByKey很简单
虽然所有 SDK 都具有GroupByKey转换,但使用GroupBy通常更自然。GroupBy转换可以通过对PCollection元素进行分组的属性名称参数化,或者通过一个函数来参数化,该函数将每个元素作为输入并映射到要进行分组的键。
// The input PCollection.
PCollection<KV<String, String>> mapped = ...;
// Apply GroupByKey to the PCollection mapped.
// Save the result as the PCollection reduced.
PCollection<KV<String, Iterable<String>>> reduced =
mapped.apply(GroupByKey.<String, String>create());# The input PCollection of (`string`, `int`) tuples.
words_and_counts = ...
grouped_words = words_and_counts | beam.GroupByKey()// CreateAndSplit creates and returns a PCollection with <K,V>
// from an input slice of stringPair (struct with K, V string fields).
pairs := CreateAndSplit(s, input)
keyed := beam.GroupByKey(s, pairs)// A PCollection of elements like
// {word: "cat", score: 1}, {word: "dog", score: 5}, {word: "cat", score: 5}, ...
const scores : PCollection<{word: string, score: number}> = ...
// This will produce a PCollection with elements like
// {key: "cat", value: [{ word: "cat", score: 1 },
// { word: "cat", score: 5 }, ...]}
// {key: "dog", value: [{ word: "dog", score: 5 }, ...]}
const grouped_by_word = scores.apply(beam.groupBy("word"));
// This will produce a PCollection with elements like
// {key: 3, value: [{ word: "cat", score: 1 },
// { word: "dog", score: 5 },
// { word: "cat", score: 5 }, ...]}
const by_word_length = scores.apply(beam.groupBy((x) => x.word.length));type: Combine
config:
group_by: animal
combine:
weight: group4.2.2.1 GroupByKey 和无界 PCollection
如果您使用的是无界PCollection,则必须使用非全局窗口或聚合触发器才能执行GroupByKey或CoGroupByKey。这是因为无界GroupByKey或CoGroupByKey必须等待所有具有特定键的数据被收集,但是对于无界集合,数据是无限的。窗口和/或触发器允许分组在无界数据流中的逻辑有限数据包上操作。
如果您确实将GroupByKey或CoGroupByKey应用于一组无界PCollection,而没有为每个集合设置非全局窗口策略、触发策略或两者,Beam 将在管道构建时生成 IllegalStateException 错误。
当使用GroupByKey或CoGroupByKey对应用了窗口策略的PCollection进行分组时,您要分组的所有PCollection必须使用相同的窗口策略和窗口大小。例如,您要合并的所有集合必须使用(假设)相同的 5 分钟固定窗口或每 30 秒开始的 4 分钟滑动窗口。
如果您的管道试图使用GroupByKey或CoGroupByKey合并具有不兼容窗口的PCollection,Beam 将在管道构建时生成 IllegalStateException 错误。
4.2.3. CoGroupByKey
CoGroupByKey对两个或多个具有相同键类型的键值PCollection执行关系连接。设计您的管道展示了一个使用连接的示例管道。
如果您有多个数据集提供了有关相关事物的的信息,请考虑使用CoGroupByKey。例如,假设您有两个不同的文件包含用户数据:一个文件包含姓名和电子邮件地址;另一个文件包含姓名和电话号码。您可以使用用户名作为公共键,将其他数据作为关联值来连接这两个数据集。连接后,您将拥有一个包含与每个姓名关联的所有信息(电子邮件地址和电话号码)的数据集。
也可以考虑使用 SqlTransform 执行连接。
如果您使用的是无界PCollection,则必须使用非全局窗口或聚合触发器才能执行CoGroupByKey。有关更多详细信息,请参阅GroupByKey 和无界 PCollection。
在 Beam SDK for Java 中,CoGroupByKey接受键控PCollection(PCollection<KV<K, V>>)元组作为输入。为了类型安全,SDK 要求您将每个PCollection作为KeyedPCollectionTuple的一部分传递。您必须为要传递给CoGroupByKey的KeyedPCollectionTuple中的每个输入PCollection声明一个TupleTag。作为输出,CoGroupByKey返回一个PCollection<KV<K, CoGbkResult>>,它按其公共键对来自所有输入PCollection的值进行分组。每个键(所有类型为K)将具有不同的CoGbkResult,它是一个从TupleTag<T>到Iterable<T>的映射。您可以使用在初始集合中提供的TupleTag访问CoGbkResult对象中的特定集合。
在 Beam SDK for Python 中,CoGroupByKey接受一个键控PCollection字典作为输入。作为输出,CoGroupByKey创建一个包含一个键值元组的单个输出PCollection,对应于输入PCollection中的每个键。每个键的值是一个字典,它将每个标签映射到对应PCollection中键下值的迭代器。
在 Beam Go SDK 中,CoGroupByKey接受任意数量的PCollection作为输入。作为输出,CoGroupByKey创建一个包含每个键的单个输出PCollection,以及每个输入PCollection的值迭代器函数。迭代器函数按它们提供给CoGroupByKey的顺序映射到输入PCollections。
以下概念示例使用两个输入集合来展示CoGroupByKey的机制。
第一组数据有一个名为emailsTag的TupleTag<String>,包含姓名和电子邮件地址。第二组数据有一个名为phonesTag的TupleTag<String>,包含姓名和电话号码。
第一组数据包含姓名和电子邮件地址。第二组数据包含姓名和电话号码。
final List<KV<String, String>> emailsList =
Arrays.asList(
KV.of("amy", "amy@example.com"),
KV.of("carl", "carl@example.com"),
KV.of("julia", "julia@example.com"),
KV.of("carl", "carl@email.com"));
final List<KV<String, String>> phonesList =
Arrays.asList(
KV.of("amy", "111-222-3333"),
KV.of("james", "222-333-4444"),
KV.of("amy", "333-444-5555"),
KV.of("carl", "444-555-6666"));
PCollection<KV<String, String>> emails = p.apply("CreateEmails", Create.of(emailsList));
PCollection<KV<String, String>> phones = p.apply("CreatePhones", Create.of(phonesList));emails_list = [
('amy', 'amy@example.com'),
('carl', 'carl@example.com'),
('julia', 'julia@example.com'),
('carl', 'carl@email.com'),
]
phones_list = [
('amy', '111-222-3333'),
('james', '222-333-4444'),
('amy', '333-444-5555'),
('carl', '444-555-6666'),
]
emails = p | 'CreateEmails' >> beam.Create(emails_list)
phones = p | 'CreatePhones' >> beam.Create(phones_list)type stringPair struct {
K, V string
}
func splitStringPair(e stringPair) (string, string) {
return e.K, e.V
}
func init() {
// Register DoFn.
register.Function1x2(splitStringPair)
}
// CreateAndSplit is a helper function that creates
func CreateAndSplit(s beam.Scope, input []stringPair) beam.PCollection {
initial := beam.CreateList(s, input)
return beam.ParDo(s, splitStringPair, initial)
}
var emailSlice = []stringPair{
{"amy", "amy@example.com"},
{"carl", "carl@example.com"},
{"julia", "julia@example.com"},
{"carl", "carl@email.com"},
}
var phoneSlice = []stringPair{
{"amy", "111-222-3333"},
{"james", "222-333-4444"},
{"amy", "333-444-5555"},
{"carl", "444-555-6666"},
}
emails := CreateAndSplit(s.Scope("CreateEmails"), emailSlice)
phones := CreateAndSplit(s.Scope("CreatePhones"), phoneSlice)const emails_list = [
{ name: "amy", email: "amy@example.com" },
{ name: "carl", email: "carl@example.com" },
{ name: "julia", email: "julia@example.com" },
{ name: "carl", email: "carl@email.com" },
];
const phones_list = [
{ name: "amy", phone: "111-222-3333" },
{ name: "james", phone: "222-333-4444" },
{ name: "amy", phone: "333-444-5555" },
{ name: "carl", phone: "444-555-6666" },
];
const emails = root.apply(
beam.withName("createEmails", beam.create(emails_list))
);
const phones = root.apply(
beam.withName("createPhones", beam.create(phones_list))
);- type: Create
name: CreateEmails
config:
elements:
- { name: "amy", email: "amy@example.com" }
- { name: "carl", email: "carl@example.com" }
- { name: "julia", email: "julia@example.com" }
- { name: "carl", email: "carl@email.com" }
- type: Create
name: CreatePhones
config:
elements:
- { name: "amy", phone: "111-222-3333" }
- { name: "james", phone: "222-333-4444" }
- { name: "amy", phone: "333-444-5555" }
- { name: "carl", phone: "444-555-6666" }CoGroupByKey之后,结果数据将包含与来自任何输入集合的每个唯一键关联的所有数据。
final TupleTag<String> emailsTag = new TupleTag<>();
final TupleTag<String> phonesTag = new TupleTag<>();
final List<KV<String, CoGbkResult>> expectedResults =
Arrays.asList(
KV.of(
"amy",
CoGbkResult.of(emailsTag, Arrays.asList("amy@example.com"))
.and(phonesTag, Arrays.asList("111-222-3333", "333-444-5555"))),
KV.of(
"carl",
CoGbkResult.of(emailsTag, Arrays.asList("carl@email.com", "carl@example.com"))
.and(phonesTag, Arrays.asList("444-555-6666"))),
KV.of(
"james",
CoGbkResult.of(emailsTag, Arrays.asList())
.and(phonesTag, Arrays.asList("222-333-4444"))),
KV.of(
"julia",
CoGbkResult.of(emailsTag, Arrays.asList("julia@example.com"))
.and(phonesTag, Arrays.asList())));results = [
(
'amy',
{
'emails': ['amy@example.com'],
'phones': ['111-222-3333', '333-444-5555']
}),
(
'carl',
{
'emails': ['carl@email.com', 'carl@example.com'],
'phones': ['444-555-6666']
}),
('james', {
'emails': [], 'phones': ['222-333-4444']
}),
('julia', {
'emails': ['julia@example.com'], 'phones': []
}),
]results := beam.CoGroupByKey(s, emails, phones)
contactLines := beam.ParDo(s, formatCoGBKResults, results)
// Synthetic example results of a cogbk.
results := []struct {
Key string
Emails, Phones []string
}{
{
Key: "amy",
Emails: []string{"amy@example.com"},
Phones: []string{"111-222-3333", "333-444-5555"},
}, {
Key: "carl",
Emails: []string{"carl@email.com", "carl@example.com"},
Phones: []string{"444-555-6666"},
}, {
Key: "james",
Emails: []string{},
Phones: []string{"222-333-4444"},
}, {
Key: "julia",
Emails: []string{"julia@example.com"},
Phones: []string{},
},
}const results = [
{
name: "amy",
values: {
emails: [{ name: "amy", email: "amy@example.com" }],
phones: [
{ name: "amy", phone: "111-222-3333" },
{ name: "amy", phone: "333-444-5555" },
],
},
},
{
name: "carl",
values: {
emails: [
{ name: "carl", email: "carl@example.com" },
{ name: "carl", email: "carl@email.com" },
],
phones: [{ name: "carl", phone: "444-555-6666" }],
},
},
{
name: "james",
values: {
emails: [],
phones: [{ name: "james", phone: "222-333-4444" }],
},
},
{
name: "julia",
values: {
emails: [{ name: "julia", email: "julia@example.com" }],
phones: [],
},
},
];以下代码示例使用CoGroupByKey连接两个PCollection,然后使用ParDo来使用结果。然后,代码使用标签来查找和格式化来自每个集合的数据。
以下代码示例使用CoGroupByKey连接两个PCollection,然后使用ParDo来使用结果。DoFn迭代器参数的顺序映射到CoGroupByKey输入的顺序。
PCollection<KV<String, CoGbkResult>> results =
KeyedPCollectionTuple.of(emailsTag, emails)
.and(phonesTag, phones)
.apply(CoGroupByKey.create());
PCollection<String> contactLines =
results.apply(
ParDo.of(
new DoFn<KV<String, CoGbkResult>, String>() {
@ProcessElement
public void processElement(ProcessContext c) {
KV<String, CoGbkResult> e = c.element();
String name = e.getKey();
Iterable<String> emailsIter = e.getValue().getAll(emailsTag);
Iterable<String> phonesIter = e.getValue().getAll(phonesTag);
String formattedResult =
Snippets.formatCoGbkResults(name, emailsIter, phonesIter);
c.output(formattedResult);
}
}));# The result PCollection contains one key-value element for each key in the
# input PCollections. The key of the pair will be the key from the input and
# the value will be a dictionary with two entries: 'emails' - an iterable of
# all values for the current key in the emails PCollection and 'phones': an
# iterable of all values for the current key in the phones PCollection.
results = ({'emails': emails, 'phones': phones} | beam.CoGroupByKey())
def join_info(name_info):
(name, info) = name_info
return '%s; %s; %s' %\
(name, sorted(info['emails']), sorted(info['phones']))
contact_lines = results | beam.Map(join_info)func formatCoGBKResults(key string, emailIter, phoneIter func(*string) bool) string {
var s string
var emails, phones []string
for emailIter(&s) {
emails = append(emails, s)
}
for phoneIter(&s) {
phones = append(phones, s)
}
// Values have no guaranteed order, sort for deterministic output.
sort.Strings(emails)
sort.Strings(phones)
return fmt.Sprintf("%s; %s; %s", key, formatStringIter(emails), formatStringIter(phones))
}
func init() {
register.Function3x1(formatCoGBKResults)
// 1 input of type string => Iter1[string]
register.Iter1[string]()
}
// Synthetic example results of a cogbk.
results := []struct {
Key string
Emails, Phones []string
}{
{
Key: "amy",
Emails: []string{"amy@example.com"},
Phones: []string{"111-222-3333", "333-444-5555"},
}, {
Key: "carl",
Emails: []string{"carl@email.com", "carl@example.com"},
Phones: []string{"444-555-6666"},
}, {
Key: "james",
Emails: []string{},
Phones: []string{"222-333-4444"},
}, {
Key: "julia",
Emails: []string{"julia@example.com"},
Phones: []string{},
},
}const formatted_results_pcoll = beam
.P({ emails, phones })
.apply(beam.coGroupBy("name"))
.map(function formatResults({ key, values }) {
const emails = values.emails.map((x) => x.email).sort();
const phones = values.phones.map((x) => x.phone).sort();
return `${key}; [${emails}]; [${phones}]`;
});- type: MapToFields
name: PrepareEmails
input: CreateEmails
config:
language: python
fields:
name: name
email: "[email]"
phone: "[]"
- type: MapToFields
name: PreparePhones
input: CreatePhones
config:
language: python
fields:
name: name
email: "[]"
phone: "[phone]"
- type: Combine
name: CoGropuBy
input: [PrepareEmails, PreparePhones]
config:
group_by: [name]
combine:
email: concat
phone: concat
- type: MapToFields
name: FormatResults
input: CoGropuBy
config:
language: python
fields:
formatted:
"'%s; %s; %s' % (name, sorted(email), sorted(phone))"格式化后的数据如下所示
final List<String> formattedResults =
Arrays.asList(
"amy; ['amy@example.com']; ['111-222-3333', '333-444-5555']",
"carl; ['carl@email.com', 'carl@example.com']; ['444-555-6666']",
"james; []; ['222-333-4444']",
"julia; ['julia@example.com']; []");formatted_results = [
"amy; ['amy@example.com']; ['111-222-3333', '333-444-5555']",
"carl; ['carl@email.com', 'carl@example.com']; ['444-555-6666']",
"james; []; ['222-333-4444']",
"julia; ['julia@example.com']; []",
]formattedResults := []string{
"amy; ['amy@example.com']; ['111-222-3333', '333-444-5555']",
"carl; ['carl@email.com', 'carl@example.com']; ['444-555-6666']",
"james; []; ['222-333-4444']",
"julia; ['julia@example.com']; []",
}const formatted_results = [
"amy; [amy@example.com]; [111-222-3333,333-444-5555]",
"carl; [carl@email.com,carl@example.com]; [444-555-6666]",
"james; []; [222-333-4444]",
"julia; [julia@example.com]; []",
];"amy; ['amy@example.com']; ['111-222-3333', '333-444-5555']",
"carl; ['carl@email.com', 'carl@example.com']; ['444-555-6666']",
"james; []; ['222-333-4444']",
"julia; ['julia@example.com']; []",4.2.4. Combine
Combine Combine Combine Combine 是一个 Beam 转换,用于组合数据中的元素或值的集合。Combine有一些变体可以在整个PCollection上工作,还有一些变体可以组合键值对PCollection中每个键的值。
当您应用Combine转换时,您必须提供包含组合元素或值的逻辑的函数。组合函数应该是可交换的和可结合的,因为该函数不一定在具有给定键的所有值上恰好调用一次。由于输入数据(包括值集合)可能分布在多个工作器上,因此组合函数可能会被多次调用,以对值集合的子集执行部分组合。Beam SDK 还提供了一些用于常见数字组合操作的预构建组合函数,例如求和、最小值和最大值。
简单的组合操作,例如求和,通常可以实现为一个简单的函数。更复杂的组合操作可能需要您创建一个CombineFn的子类,该子类具有与输入/输出类型不同的累积类型。
CombineFn的结合性和可交换性允许运行器自动应用一些优化
- 组合器提升:这是最重要的优化。输入元素在每个键和窗口内组合,然后进行混洗,因此混洗的数据量可能会减少许多数量级。这种优化的另一个术语是“mapper 端组合”。
- 增量组合:当您的
CombineFn大幅减少数据大小时,在流式混洗时组合元素非常有用。这会将进行组合的成本分散到您的流式计算可能处于空闲状态的时间内。增量组合还会减少中间累积器的存储。
4.2.4.1. 使用简单函数的简单组合
Beam YAML 包含以下内置的 CombineFns:count、sum、min、max、mean、any、all、group 和 concat。来自其他语言的 CombineFns 也可以参考 (完整聚合文档) [https://beam.apache.org/documentation/sdks/yaml-combine/] 中的描述。 以下示例代码展示了一个简单的组合函数。 组合是通过使用 `combining` 方法修改分组转换来完成的。此方法需要三个参数:要组合的值(可以是输入元素的命名属性,也可以是整个输入的函数)、组合操作(可以是二元函数或 `CombineFn`),最后是输出对象中组合值的名称。// Sum a collection of Integer values. The function SumInts implements the interface SerializableFunction.
public static class SumInts implements SerializableFunction<Iterable<Integer>, Integer> {
@Override
public Integer apply(Iterable<Integer> input) {
int sum = 0;
for (int item : input) {
sum += item;
}
return sum;
}
}pc = [1, 10, 100, 1000]
def bounded_sum(values, bound=500):
return min(sum(values), bound)
small_sum = pc | beam.CombineGlobally(bounded_sum) # [500]
large_sum = pc | beam.CombineGlobally(bounded_sum, bound=5000) # [1111]func sumInts(a, v int) int {
return a + v
}
func init() {
register.Function2x1(sumInts)
}
func globallySumInts(s beam.Scope, ints beam.PCollection) beam.PCollection {
return beam.Combine(s, sumInts, ints)
}
type boundedSum struct {
Bound int
}
func (fn *boundedSum) MergeAccumulators(a, v int) int {
sum := a + v
if fn.Bound > 0 && sum > fn.Bound {
return fn.Bound
}
return sum
}
func init() {
register.Combiner1[int](&boundedSum{})
}
func globallyBoundedSumInts(s beam.Scope, bound int, ints beam.PCollection) beam.PCollection {
return beam.Combine(s, &boundedSum{Bound: bound}, ints)
}const pcoll = root.apply(beam.create([1, 10, 100, 1000]));
const result = pcoll.apply(
beam
.groupGlobally()
.combining((c) => c, (x, y) => x + y, "sum")
.combining((c) => c, (x, y) => x * y, "product")
);
const expected = { sum: 1111, product: 1000000 }type: Combine
config:
language: python
group_by: animal
combine:
biggest:
fn:
type: 'apache_beam.transforms.combiners.TopCombineFn'
config:
n: 2
value: weight所有 Combiners 应使用通用的 register.CombinerX[...] 函数进行注册。这使 Go SDK 能够从任何输入/输出推断出编码,注册 Combiner 以在远程运行器上执行,并通过反射优化 Combiner 的运行时执行。
当您的累加器、输入和输出都是相同类型时,应使用 Combiner1。它可以通过 register.Combiner1[T](&CustomCombiner{}) 调用,其中 T 是输入/累加器/输出的类型。
当您的累加器、输入和输出是 2 种不同类型时,应使用 Combiner2。它可以通过 register.Combiner2[T1, T2](&CustomCombiner{}) 调用,其中 T1 是累加器的类型,T2 是另一种类型。
当您的累加器、输入和输出是 3 种不同类型时,应使用 Combiner3。它可以通过 register.Combiner3[T1, T2, T3](&CustomCombiner{}) 调用,其中 T1 是累加器的类型,T2 是输入的类型,T3 是输出的类型。
4.2.4.2. 使用 CombineFn 进行高级组合
对于更复杂的组合函数,您可以定义一个 CombineFn 的子类。如果组合函数需要更复杂的累加器、必须执行额外的预处理或后处理、可能更改输出类型或考虑键,则应使用 CombineFn。
一个通用的组合操作包括五个操作。当您创建 CombineFn 的子类 时,您必须通过覆盖相应的方法提供五个操作。只有 MergeAccumulators 是必需的方法。其他方法将根据累加器类型具有默认解释。生命周期方法如下:
创建累加器 创建一个新的“本地”累加器。在示例情况下,取平均值,本地累加器跟踪值的运行总和(我们最终平均除法的分子值)和迄今为止累加的值的数量(分母值)。它可以在分布式环境中被调用任意次。
添加输入 将输入元素添加到累加器中,返回累加器值。在我们的示例中,它将更新总和并将计数加 1。它也可以并行调用。
合并累加器 将多个累加器合并为一个累加器;这是在最终计算之前组合多个累加器中数据的机制。在计算平均值的情况下,合并了代表除法每个部分的累加器。它可以多次在其输出上被调用。
提取输出 执行最终计算。在计算平均值的情况下,这意味着将所有值的组合总和除以累加的值的数量。它在最终合并的累加器上调用一次。
压缩 返回累加器的更紧凑的表示形式。在累加器跨网络发送之前调用此方法,并且在将值缓冲或以其他方式在添加到累加器时惰性地保留未处理的情况下很有用。Compact 应返回一个等效的累加器,但可能已修改。在大多数情况下,Compact 不是必需的。有关使用 Compact 的现实世界示例,请参阅 TopCombineFn 的 Python SDK 实现
以下示例代码展示了如何定义一个计算平均值的 CombineFn
public class AverageFn extends CombineFn<Integer, AverageFn.Accum, Double> {
public static class Accum {
int sum = 0;
int count = 0;
}
@Override
public Accum createAccumulator() { return new Accum(); }
@Override
public Accum addInput(Accum accum, Integer input) {
accum.sum += input;
accum.count++;
return accum;
}
@Override
public Accum mergeAccumulators(Iterable<Accum> accums) {
Accum merged = createAccumulator();
for (Accum accum : accums) {
merged.sum += accum.sum;
merged.count += accum.count;
}
return merged;
}
@Override
public Double extractOutput(Accum accum) {
return ((double) accum.sum) / accum.count;
}
// No-op
@Override
public Accum compact(Accum accum) { return accum; }
}pc = ...
class AverageFn(beam.CombineFn):
def create_accumulator(self):
return (0.0, 0)
def add_input(self, sum_count, input):
(sum, count) = sum_count
return sum + input, count + 1
def merge_accumulators(self, accumulators):
sums, counts = zip(*accumulators)
return sum(sums), sum(counts)
def extract_output(self, sum_count):
(sum, count) = sum_count
return sum / count if count else float('NaN')
def compact(self, accumulator):
# No-op
return accumulatortype averageFn struct{}
type averageAccum struct {
Count, Sum int
}
func (fn *averageFn) CreateAccumulator() averageAccum {
return averageAccum{0, 0}
}
func (fn *averageFn) AddInput(a averageAccum, v int) averageAccum {
return averageAccum{Count: a.Count + 1, Sum: a.Sum + v}
}
func (fn *averageFn) MergeAccumulators(a, v averageAccum) averageAccum {
return averageAccum{Count: a.Count + v.Count, Sum: a.Sum + v.Sum}
}
func (fn *averageFn) ExtractOutput(a averageAccum) float64 {
if a.Count == 0 {
return math.NaN()
}
return float64(a.Sum) / float64(a.Count)
}
func (fn *averageFn) Compact(a averageAccum) averageAccum {
// No-op
return a
}
func init() {
register.Combiner3[averageAccum, int, float64](&averageFn{})
}const meanCombineFn: beam.CombineFn<number, [number, number], number> =
{
createAccumulator: () => [0, 0],
addInput: ([sum, count]: [number, number], i: number) => [
sum + i,
count + 1,
],
mergeAccumulators: (accumulators: [number, number][]) =>
accumulators.reduce(([sum0, count0], [sum1, count1]) => [
sum0 + sum1,
count0 + count1,
]),
extractOutput: ([sum, count]: [number, number]) => sum / count,
};4.2.4.3. 将 PCollection 组合成单个值
使用全局组合将给定 PCollection 中的所有元素转换为单个值,在您的管道中表示为包含一个元素的新 PCollection。以下示例代码展示了如何应用 Beam 提供的 sum 组合函数来为 PCollection 的整数生成单个总和值。
// Sum.SumIntegerFn() combines the elements in the input PCollection. The resulting PCollection, called sum,
// contains one value: the sum of all the elements in the input PCollection.
PCollection<Integer> pc = ...;
PCollection<Integer> sum = pc.apply(
Combine.globally(new Sum.SumIntegerFn()));# sum combines the elements in the input PCollection.
# The resulting PCollection, called result, contains one value: the sum of all
# the elements in the input PCollection.
pc = ...
average = pc | beam.CombineGlobally(AverageFn())average := beam.Combine(s, &averageFn{}, ints)const pcoll = root.apply(beam.create([4, 5, 6]));
const result = pcoll.apply(
beam.groupGlobally().combining((c) => c, meanCombineFn, "mean")
);type: Combine
config:
group_by: []
combine:
weight: sum4.2.4.4. 组合和全局窗口
如果您的输入 PCollection 使用默认的全局窗口,则默认行为是返回包含一个项目的 PCollection。该项目的价值来自您在应用 Combine 时指定的组合函数中的累加器。例如,Beam 提供的 sum 组合函数返回零值(空输入的总和),而 min 组合函数返回最大值或无限值。
要使 Combine 在输入为空时返回空的 PCollection,请在应用 Combine 转换时指定 .withoutDefaults,如以下代码示例所示
PCollection<Integer> pc = ...;
PCollection<Integer> sum = pc.apply(
Combine.globally(new Sum.SumIntegerFn()).withoutDefaults());pc = ...
sum = pc | beam.CombineGlobally(sum).without_defaults()func returnSideOrDefault(d float64, iter func(*float64) bool) float64 {
var c float64
if iter(&c) {
// Side input has a value, so return it.
return c
}
// Otherwise, return the default
return d
}
func init() { register.Function2x1(returnSideOrDefault) }
func globallyAverageWithDefault(s beam.Scope, ints beam.PCollection) beam.PCollection {
// Setting combine defaults has requires no helper function in the Go SDK.
average := beam.Combine(s, &averageFn{}, ints)
// To add a default value:
defaultValue := beam.Create(s, float64(0))
return beam.ParDo(s, returnSideOrDefault, defaultValue, beam.SideInput{Input: average})
}const pcoll = root.apply(
beam.create([
{ player: "alice", accuracy: 1.0 },
{ player: "bob", accuracy: 0.99 },
{ player: "eve", accuracy: 0.5 },
{ player: "eve", accuracy: 0.25 },
])
);
const result = pcoll.apply(
beam
.groupGlobally()
.combining("accuracy", combiners.mean, "mean")
.combining("accuracy", combiners.max, "max")
);
const expected = [{ max: 1.0, mean: 0.685 }];4.2.4.5. 组合和非全局窗口
如果您的 PCollection 使用任何非全局窗口函数,则 Beam 不会提供默认行为。在应用 Combine 时,您必须指定以下选项之一
- 指定
.withoutDefaults,其中输入PCollection中为空的窗口在输出集合中也将为空。 - 指定
.asSingletonView,其中输出将立即转换为PCollectionView,这将为每个空窗口提供一个默认值,在用作侧面输入时使用。通常只有在您的管道Combine的结果稍后在管道中用作侧面输入时才需要使用此选项。
如果您的 PCollection 使用任何非全局窗口函数,则 Beam Go SDK 的行为与全局窗口相同。输入 PCollection 中为空的窗口在输出集合中也将为空。
4.2.4.6. 组合键控 PCollection 中的值
在创建键控 PCollection 后(例如,通过使用 GroupByKey 转换),一个常见的模式是将与每个键关联的值集合组合成一个合并的单一值。借鉴 GroupByKey 的先前示例,名为 groupedWords 的键分组 PCollection 如下所示
cat, [1,5,9]
dog, [5,2]
and, [1,2,6]
jump, [3]
tree, [2]
...
在上面的 PCollection 中,每个元素都具有一个字符串键(例如,“cat”)及其值的整数可迭代对象(在第一个元素中,包含 [1, 5, 9])。如果您的管道下一处理步骤组合了值(而不是单独考虑它们),您可以组合整数的可迭代对象以创建单个合并值,与每个键配对。这种 GroupByKey 后跟合并值集合的模式等效于 Beam 的 Combine PerKey 转换。您提供给 Combine PerKey 的组合函数必须是关联的归约函数或 CombineFn 的子类。
// PCollection is grouped by key and the Double values associated with each key are combined into a Double.
PCollection<KV<String, Double>> salesRecords = ...;
PCollection<KV<String, Double>> totalSalesPerPerson =
salesRecords.apply(Combine.<String, Double, Double>perKey(
new Sum.SumDoubleFn()));
// The combined value is of a different type than the original collection of values per key. PCollection has
// keys of type String and values of type Integer, and the combined value is a Double.
PCollection<KV<String, Integer>> playerAccuracy = ...;
PCollection<KV<String, Double>> avgAccuracyPerPlayer =
playerAccuracy.apply(Combine.<String, Integer, Double>perKey(
new MeanInts())));# PCollection is grouped by key and the numeric values associated with each key
# are averaged into a float.
player_accuracies = ...
avg_accuracy_per_player = (
player_accuracies
| beam.CombinePerKey(beam.combiners.MeanCombineFn()))// PCollection is grouped by key and the numeric values associated with each key
// are averaged into a float64.
playerAccuracies := ... // PCollection<string,int>
avgAccuracyPerPlayer := stats.MeanPerKey(s, playerAccuracies)
// avgAccuracyPerPlayer is a PCollection<string,float64>
const pcoll = root.apply(
beam.create([
{ player: "alice", accuracy: 1.0 },
{ player: "bob", accuracy: 0.99 },
{ player: "eve", accuracy: 0.5 },
{ player: "eve", accuracy: 0.25 },
])
);
const result = pcoll.apply(
beam
.groupBy("player")
.combining("accuracy", combiners.mean, "mean")
.combining("accuracy", combiners.max, "max")
);
const expected = [
{ player: "alice", mean: 1.0, max: 1.0 },
{ player: "bob", mean: 0.99, max: 0.99 },
{ player: "eve", mean: 0.375, max: 0.5 },
];type: Combine
config:
group_by: [animal]
combine:
total_weight:
fn: sum
value: weight
average_weight:
fn: mean
value: weight4.2.5. Flatten
Flatten Flatten Flatten Flatten 是 Beam 转换,适用于存储相同数据类型的 PCollection 对象。Flatten 将多个 PCollection 对象合并为单个逻辑 PCollection。
以下示例展示了如何应用 Flatten 转换来合并多个 PCollection 对象。
// Flatten takes a PCollectionList of PCollection objects of a given type.
// Returns a single PCollection that contains all of the elements in the PCollection objects in that list.
PCollection<String> pc1 = ...;
PCollection<String> pc2 = ...;
PCollection<String> pc3 = ...;
PCollectionList<String> collections = PCollectionList.of(pc1).and(pc2).and(pc3);
PCollection<String> merged = collections.apply(Flatten.<String>pCollections());也可以使用 FlattenWith 转换以更兼容链接的方式将 PCollection 合并到输出 PCollection 中。
PCollection<String> merged = pc1
.apply(...)
// Merges the elements of pc2 in at this point...
.apply(FlattenWith.of(pc2))
.apply(...)
// and the elements of pc3 at this point.
.apply(FlattenWith.of(pc3))
.apply(...);# Flatten takes a tuple of PCollection objects.
# Returns a single PCollection that contains all of the elements in the PCollection objects in that tuple.
merged = (
(pcoll1, pcoll2, pcoll3)
# A list of tuples can be "piped" directly into a Flatten transform.
| beam.Flatten())也可以使用 FlattenWith 转换以更兼容链接的方式将 PCollection 合并到输出 PCollection 中。
merged = (
pcoll1
| SomeTransform()
| beam.FlattenWith(pcoll2, pcoll3)
| SomeOtherTransform())FlattenWith 可以接受根 PCollection 生成转换(例如 Create 和 Read)以及已经构建的 PCollection,并将应用它们并将它们的输出扁平化为生成的输出 PCollection 中。
merged = (
pcoll
| SomeTransform()
| beam.FlattenWith(beam.Create(['x', 'y', 'z']))
| SomeOtherTransform())// Flatten accepts any number of PCollections of the same element type.
// Returns a single PCollection that contains all of the elements in input PCollections.
merged := beam.Flatten(s, pcol1, pcol2, pcol3)// Flatten taken an array of PCollection objects, wrapped in beam.P(...)
// Returns a single PCollection that contains a union of all of the elements in all input PCollections.
const fib = root.apply(
beam.withName("createFib", beam.create([1, 1, 2, 3, 5, 8]))
);
const pow = root.apply(
beam.withName("createPow", beam.create([1, 2, 4, 8, 16, 32]))
);
const result = beam.P([fib, pow]).apply(beam.flatten());- type: Flatten
input: [SomeProducingTransform, AnotherProducingTransform]在 Beam YAML 中,通常不需要显式扁平化,因为可以为将被隐式扁平化的任何转换列出多个输入。
4.2.5.1. 合并集合中的数据编码
默认情况下,输出 PCollection 的编码器与输入 PCollectionList 中第一个 PCollection 的编码器相同。但是,输入 PCollection 对象可以分别使用不同的编码器,只要它们都包含您在选定语言中相同的数据类型即可。
4.2.5.2. 合并窗口集合
当使用 Flatten 合并应用了窗口策略的 PCollection 对象时,您要合并的所有 PCollection 对象必须使用兼容的窗口策略和窗口大小。例如,您要合并的所有集合都必须(假设)使用相同的 5 分钟固定窗口或以 30 秒为间隔开始的 4 分钟滑动窗口。
如果您的管道尝试使用 Flatten 来合并具有不兼容窗口的 PCollection 对象,则在构建管道时,Beam 将生成 IllegalStateException 错误。
4.2.6. Partition
Partition Partition Partition Partition 是 Beam 转换,适用于存储相同数据类型的 PCollection 对象。Partition 将单个 PCollection 拆分为固定数量的较小集合。
在 Typescript SDK 中,Split 转换通常更自然地使用。
Partition 根据您提供的划分函数划分 PCollection 的元素。划分函数包含确定如何将输入 PCollection 的元素拆分为每个生成的划分 PCollection 的逻辑。划分数量必须在图构造时确定。例如,您可以在运行时将划分数量作为命令行选项传递(这将用于构建管道图),但您不能在管道中间(例如,根据在构建管道图后计算的数据)确定划分数量。
以下示例将 PCollection 分割为百分位数组。
// Provide an int value with the desired number of result partitions, and a PartitionFn that represents the
// partitioning function. In this example, we define the PartitionFn in-line. Returns a PCollectionList
// containing each of the resulting partitions as individual PCollection objects.
PCollection<Student> students = ...;
// Split students up into 10 partitions, by percentile:
PCollectionList<Student> studentsByPercentile =
students.apply(Partition.of(10, new PartitionFn<Student>() {
public int partitionFor(Student student, int numPartitions) {
return student.getPercentile() // 0..99
* numPartitions / 100;
}}));
// You can extract each partition from the PCollectionList using the get method, as follows:
PCollection<Student> fortiethPercentile = studentsByPercentile.get(4);# Provide an int value with the desired number of result partitions, and a partitioning function (partition_fn in this example).
# Returns a tuple of PCollection objects containing each of the resulting partitions as individual PCollection objects.
students = ...
def partition_fn(student, num_partitions):
return int(get_percentile(student) * num_partitions / 100)
by_decile = students | beam.Partition(partition_fn, 10)
# You can extract each partition from the tuple of PCollection objects as follows:
fortieth_percentile = by_decile[4]func decileFn(student Student) int {
return int(float64(student.Percentile) / float64(10))
}
func init() {
register.Function1x1(decileFn)
}
// Partition returns a slice of PCollections
studentsByPercentile := beam.Partition(s, 10, decileFn, students)
// Each partition can be extracted by indexing into the slice.
fortiethPercentile := studentsByPercentile[4]const deciles: PCollection<Student>[] = students.apply(
beam.partition(
(student, numPartitions) =>
Math.floor((getPercentile(student) / 100) * numPartitions),
10
)
);
const topDecile: PCollection<Student> = deciles[9];type: Partition
config:
by: str(percentile // 10)
language: python
outputs: ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "10"]请注意,在 Beam YAML 中,PCollections 是通过字符串而不是整数值进行划分的。
4.3. 为 Beam 转换编写用户代码的要求
在构建 Beam 转换的用户代码时,您应该牢记执行的分布式性质。例如,您的函数可能在许多不同的机器上并行运行许多副本,并且这些副本独立运行,不与任何其他副本通信或共享状态。根据您为管道选择的 Pipeline Runner 和处理后端,您的用户代码函数的每个副本都可能被重试或多次运行。因此,您应该谨慎对待在用户代码中包含诸如状态依赖性之类的内容。
一般来说,您的用户代码必须至少满足以下要求
- 您的函数对象必须是可序列化的。
- 您的函数对象必须是线程兼容的,并且要意识到Beam SDK 不是线程安全的。
此外,建议您使您的函数对象幂等的。Beam 支持非幂等函数,但需要额外的思考才能确保在存在外部副作用时正确性。
注意:这些要求适用于
DoFn(用于 ParDo 转换的函数对象)、CombineFn(用于 Combine 转换的函数对象)和WindowFn(用于 Window 转换的函数对象)的子类。
注意:这些要求适用于
DoFn(用于 ParDo 转换的函数对象)、CombineFn(用于 Combine 转换的函数对象)和WindowFn(用于 Window 转换的函数对象)。
4.3.1. 可序列化
您提供给转换的任何函数对象必须是 **完全可序列化的**。这是因为需要对函数的副本进行序列化并传输到处理集群中的远程工作器。 用户代码的基本类(例如 DoFn、CombineFn 和 WindowFn)已经实现了 Serializable;但是,您的子类不能添加任何不可序列化的成员。 函数是可序列化的,只要它们已使用 register.FunctionXxY(对于简单函数)或 register.DoFnXxY(对于结构化 DoFn)注册,并且不是闭包。结构化 DoFn 将对其所有导出的字段进行序列化。未导出的字段无法序列化,将被静默忽略。 Typescript SDK 使用 ts-serialize-closures 来序列化函数(和其他对象)。对于非闭包函数,这开箱即用,并且也适用于闭包,只要所讨论的函数(及其引用的任何闭包)使用 ts-closure-transform 钩子(例如,使用 ttsc 代替 tsc)进行编译。或者,您可以调用 requireForSerialization("importableModuleDefiningFunc", {func}) 来 直接按名称注册函数,这样可能更不易出错。请注意,如果(通常在 Javascript 中)func 返回包含闭包的对象,仅注册 func 是不够的——如果使用,则必须注册其返回值。
您应该记住一些其他可序列化因素
- 瞬态未导出 函数对象中的字段 **不会** 传输到工作器实例,因为它们不会自动序列化。
- 避免在序列化之前加载包含大量数据的字段。
- 函数对象的各个实例不能共享数据。
- 在应用函数对象后对其进行变异将不会产生任何影响。
注意:使用匿名内部类实例在内联声明函数对象时要小心。在非静态上下文中,您的内部类实例将隐式包含指向封闭类的指针以及该类的状态。该封闭类也将被序列化,因此适用于函数对象本身的相同注意事项也适用于此外部类。
注意:无法检测函数是否为闭包。闭包会导致运行时错误和管道故障。尽可能避免使用匿名函数。
4.3.2. 线程兼容性
您的函数对象应该与线程兼容。函数对象的每个实例在工作器实例上一次由单个线程访问,除非您显式创建自己的线程。但是,请注意,**Beam SDK 不是线程安全的**。如果您在用户代码中创建自己的线程,则必须提供自己的同步。 请注意,函数对象中的静态成员不会传递到工作器实例,并且函数的多个实例可能从不同的线程访问。
4.3.3. 幂等性
建议您使您的函数对象幂等——也就是说,它可以根据需要重复或重试,而不会造成意外的副作用。支持非幂等函数,但是 Beam 模型不保证您的用户代码可能被调用或重试的次数;因此,保持您的函数对象幂等会使您的管道的输出确定性,并且您的转换的行为更可预测,也更易于调试。
4.4. 侧输入
除了主要的输入 PCollection 之外,您还可以以侧输入的形式向 ParDo 转换提供其他输入。侧输入是 DoFn 在每次处理输入 PCollection 中的元素时都可以访问的额外输入。当您指定侧输入时,您会创建一个其他数据的视图,该视图可以在处理每个元素时从 ParDo 转换的 DoFn 中读取。
如果您的 ParDo 需要在处理输入 PCollection 中的每个元素时注入其他数据,但其他数据需要在运行时确定(而不是硬编码),则侧输入很有用。此类值可能由输入数据确定,或者依赖于管道的不同分支。
所有侧输入可迭代对象应使用通用 register.IterX[...] 函数注册。这会优化可迭代对象的运行时执行。
4.4.1. 向 ParDo 传递侧输入
// Pass side inputs to your ParDo transform by invoking .withSideInputs.
// Inside your DoFn, access the side input by using the method DoFn.ProcessContext.sideInput.
// The input PCollection to ParDo.
PCollection<String> words = ...;
// A PCollection of word lengths that we'll combine into a single value.
PCollection<Integer> wordLengths = ...; // Singleton PCollection
// Create a singleton PCollectionView from wordLengths using Combine.globally and View.asSingleton.
final PCollectionView<Integer> maxWordLengthCutOffView =
wordLengths.apply(Combine.globally(new Max.MaxIntFn()).asSingletonView());
// Apply a ParDo that takes maxWordLengthCutOffView as a side input.
PCollection<String> wordsBelowCutOff =
words.apply(ParDo
.of(new DoFn<String, String>() {
@ProcessElement
public void processElement(@Element String word, OutputReceiver<String> out, ProcessContext c) {
// In our DoFn, access the side input.
int lengthCutOff = c.sideInput(maxWordLengthCutOffView);
if (word.length() <= lengthCutOff) {
out.output(word);
}
}
}).withSideInputs(maxWordLengthCutOffView)
);# Side inputs are available as extra arguments in the DoFn's process method or Map / FlatMap's callable.
# Optional, positional, and keyword arguments are all supported. Deferred arguments are unwrapped into their
# actual values. For example, using pvalue.AsIteor(pcoll) at pipeline construction time results in an iterable
# of the actual elements of pcoll being passed into each process invocation. In this example, side inputs are
# passed to a FlatMap transform as extra arguments and consumed by filter_using_length.
words = ...
# Callable takes additional arguments.
def filter_using_length(word, lower_bound, upper_bound=float('inf')):
if lower_bound <= len(word) <= upper_bound:
yield word
# Construct a deferred side input.
avg_word_len = (
words
| beam.Map(len)
| beam.CombineGlobally(beam.combiners.MeanCombineFn()))
# Call with explicit side inputs.
small_words = words | 'small' >> beam.FlatMap(filter_using_length, 0, 3)
# A single deferred side input.
larger_than_average = (
words | 'large' >> beam.FlatMap(
filter_using_length, lower_bound=pvalue.AsSingleton(avg_word_len))
)
# Mix and match.
small_but_nontrivial = words | beam.FlatMap(
filter_using_length,
lower_bound=2,
upper_bound=pvalue.AsSingleton(avg_word_len))
# We can also pass side inputs to a ParDo transform, which will get passed to its process method.
# The first two arguments for the process method would be self and element.
class FilterUsingLength(beam.DoFn):
def process(self, element, lower_bound, upper_bound=float('inf')):
if lower_bound <= len(element) <= upper_bound:
yield element
small_words = words | beam.ParDo(FilterUsingLength(), 0, 3)
...// Side inputs are provided using `beam.SideInput` in the DoFn's ProcessElement method.
// Side inputs can be arbitrary PCollections, which can then be iterated over per element
// in a DoFn.
// Side input parameters appear after main input elements, and before any output emitters.
words = ...
// avgWordLength is a PCollection containing a single element, a singleton.
avgWordLength := stats.Mean(s, wordLengths)
// Side inputs are added as with the beam.SideInput option to beam.ParDo.
wordsAboveCutOff := beam.ParDo(s, filterWordsAbove, words, beam.SideInput{Input: avgWordLength})
wordsBelowCutOff := beam.ParDo(s, filterWordsBelow, words, beam.SideInput{Input: avgWordLength})
// filterWordsAbove is a DoFn that takes in a word,
// and a singleton side input iterator as of a length cut off
// and only emits words that are beneath that cut off.
//
// If the iterator has no elements, an error is returned, aborting processing.
func filterWordsAbove(word string, lengthCutOffIter func(*float64) bool, emitAboveCutoff func(string)) error {
var cutOff float64
ok := lengthCutOffIter(&cutOff)
if !ok {
return fmt.Errorf("no length cutoff provided")
}
if float64(len(word)) > cutOff {
emitAboveCutoff(word)
}
return nil
}
// filterWordsBelow is a DoFn that takes in a word,
// and a singleton side input of a length cut off
// and only emits words that are beneath that cut off.
//
// If the side input isn't a singleton, a runtime panic will occur.
func filterWordsBelow(word string, lengthCutOff float64, emitBelowCutoff func(string)) {
if float64(len(word)) <= lengthCutOff {
emitBelowCutoff(word)
}
}
func init() {
register.Function3x1(filterWordsAbove)
register.Function3x0(filterWordsBelow)
// 1 input of type string => Emitter1[string]
register.Emitter1[string]()
// 1 input of type float64 => Iter1[float64]
register.Iter1[float64]()
}
// The Go SDK doesn't support custom ViewFns.
// See https://github.com/apache/beam/issues/18602 for details
// on how to contribute them!
// Side inputs are provided by passing an extra context object to
// `map`, `flatMap`, or `parDo` transforms. This object will get passed as an
// extra argument to the provided function (or `process` method of the `DoFn`).
// `SideInputParam` properties (generally created with `pardo.xxxSideInput(...)`)
// have a `lookup` method that can be invoked from within the process method.
// Let words be a PCollection of strings.
const words : PCollection<string> = ...
// meanLengthPColl will contain a single number whose value is the
// average length of the words
const meanLengthPColl: PCollection<number> = words
.apply(
beam
.groupGlobally<string>()
.combining((word) => word.length, combiners.mean, "mean")
)
.map(({ mean }) => mean);
// Now we use this as a side input to yield only words that are
// smaller than average.
const smallWords = words.flatMap(
// This is the function, taking context as a second argument.
function* keepSmall(word, context) {
if (word.length < context.meanLength.lookup()) {
yield word;
}
},
// This is the context that will be passed as a second argument.
{ meanLength: pardo.singletonSideInput(meanLengthPColl) }
);4.4.2. 侧输入和窗口
带窗口的 PCollection 可能是无限的,因此无法压缩成单个值(或单个集合类)。当您创建带窗口的 PCollection 的 PCollectionView 时,PCollectionView 表示每个窗口一个实体(每个窗口一个单例,每个窗口一个列表,等等)。
Beam 使用主输入元素的窗口来查找侧输入元素的相应窗口。Beam 将主输入元素的窗口投影到侧输入的窗口集中,然后使用来自结果窗口的侧输入。如果主输入和侧输入具有相同的窗口,则投影将提供完全对应的窗口。但是,如果输入具有不同的窗口,则 Beam 使用投影来选择最合适的侧输入窗口。
例如,如果主输入使用一分钟的固定时间窗口进行窗口化,而侧输入使用一小时的固定时间窗口进行窗口化,则 Beam 将主输入窗口投影到侧输入窗口集中,并从相应的长达一小时的侧输入窗口中选择侧输入值。
如果主输入元素存在于多个窗口中,则 processElement 会被多次调用,每个窗口调用一次。每次调用 processElement 都会投影主输入元素的“当前”窗口,因此每次可能提供不同的侧输入视图。
如果侧输入具有多个触发器触发,则 Beam 使用来自最新触发器触发的值。如果您使用具有单个全局窗口的侧输入并指定触发器,这将特别有用。
4.5. 附加输出
虽然 ParDo 始终生成一个主输出 PCollection(作为 apply 的返回值),但您也可以让 ParDo 生成任意数量的其他输出 PCollection。如果您选择具有多个输出,则 ParDo 会将所有输出 PCollection(包括主输出)捆绑在一起返回。
虽然 beam.ParDo 始终生成一个输出 PCollection,但您的 DoFn 可以生成任意数量的其他输出 PCollections,甚至根本不生成。如果您选择具有多个输出,则您的 DoFn 需要使用与输出数量匹配的 ParDo 函数调用。beam.ParDo2 用于两个输出 PCollection,beam.ParDo3 用于三个,依此类推,直到 beam.ParDo7。如果您需要更多,可以使用 beam.ParDoN,它将返回一个 []beam.PCollection。
虽然 ParDo 始终生成一个主输出 PCollection(作为 apply 的返回值)。如果您想具有多个输出,请在您的 ParDo 操作中发出具有不同属性的对象,然后使用 Split 将其拆分为多个 PCollection。
在 Beam YAML 中,通过将所有输出发出到单个 PCollection(可能带有额外的字段)来获得多个输出,然后使用 Partition 将此单个 PCollection 拆分为多个不同的 PCollection 输出。
4.5.1. 用于多个输出的标签
Split PTransform 将接受形式为 {tagA?: A, tagB?: B, ...} 的元素的 PCollection,并返回一个对象 {tagA: PCollection<A>, tagB: PCollection<B>, ...}。预期标签的集合将传递给操作;如何处理多个或未知标签可以通过传递非默认的 SplitOptions 实例来指定。
Go SDK 不使用输出标签,而是使用位置顺序来表示多个输出 PCollection。
// To emit elements to multiple output PCollections, create a TupleTag object to identify each collection
// that your ParDo produces. For example, if your ParDo produces three output PCollections (the main output
// and two additional outputs), you must create three TupleTags. The following example code shows how to
// create TupleTags for a ParDo with three output PCollections.
// Input PCollection to our ParDo.
PCollection<String> words = ...;
// The ParDo will filter words whose length is below a cutoff and add them to
// the main output PCollection<String>.
// If a word is above the cutoff, the ParDo will add the word length to an
// output PCollection<Integer>.
// If a word starts with the string "MARKER", the ParDo will add that word to an
// output PCollection<String>.
final int wordLengthCutOff = 10;
// Create three TupleTags, one for each output PCollection.
// Output that contains words below the length cutoff.
final TupleTag<String> wordsBelowCutOffTag =
new TupleTag<String>(){};
// Output that contains word lengths.
final TupleTag<Integer> wordLengthsAboveCutOffTag =
new TupleTag<Integer>(){};
// Output that contains "MARKER" words.
final TupleTag<String> markedWordsTag =
new TupleTag<String>(){};
// Passing Output Tags to ParDo:
// After you specify the TupleTags for each of your ParDo outputs, pass the tags to your ParDo by invoking
// .withOutputTags. You pass the tag for the main output first, and then the tags for any additional outputs
// in a TupleTagList. Building on our previous example, we pass the three TupleTags for our three output
// PCollections to our ParDo. Note that all of the outputs (including the main output PCollection) are
// bundled into the returned PCollectionTuple.
PCollectionTuple results =
words.apply(ParDo
.of(new DoFn<String, String>() {
// DoFn continues here.
...
})
// Specify the tag for the main output.
.withOutputTags(wordsBelowCutOffTag,
// Specify the tags for the two additional outputs as a TupleTagList.
TupleTagList.of(wordLengthsAboveCutOffTag)
.and(markedWordsTag)));# To emit elements to multiple output PCollections, invoke with_outputs() on the ParDo, and specify the
# expected tags for the outputs. with_outputs() returns a DoOutputsTuple object. Tags specified in
# with_outputs are attributes on the returned DoOutputsTuple object. The tags give access to the
# corresponding output PCollections.
results = (
words
| beam.ParDo(ProcessWords(), cutoff_length=2, marker='x').with_outputs(
'above_cutoff_lengths',
'marked strings',
main='below_cutoff_strings'))
below = results.below_cutoff_strings
above = results.above_cutoff_lengths
marked = results['marked strings'] # indexing works as well
# The result is also iterable, ordered in the same order that the tags were passed to with_outputs(),
# the main tag (if specified) first.
below, above, marked = (words
| beam.ParDo(
ProcessWords(), cutoff_length=2, marker='x')
.with_outputs('above_cutoff_lengths',
'marked strings',
main='below_cutoff_strings'))// beam.ParDo3 returns PCollections in the same order as
// the emit function parameters in processWords.
below, above, marked := beam.ParDo3(s, processWords, words)
// processWordsMixed uses both a standard return and an emitter function.
// The standard return produces the first PCollection from beam.ParDo2,
// and the emitter produces the second PCollection.
length, mixedMarked := beam.ParDo2(s, processWordsMixed, words)# Create three PCollections from a single input PCollection.
const { below, above, marked } = to_split.apply(
beam.split(["below", "above", "marked"])
);4.5.2. 在您的 DoFn 中发射到多个输出
根据需要调用发射器函数以生成与其匹配的 PCollection 的 0 个或多个元素。相同的值可以用多个发射器发出。像往常一样,在从任何发射器发出值后,不要对其进行变异。
所有发射器应使用通用 register.EmitterX[...] 函数注册。这会优化发射器的运行时执行。
DoFn 也可以通过标准返回来返回单个元素。标准返回始终是 beam.ParDo 返回的第一个 PCollection。其他发射器将其输出发送到其定义的参数顺序中的自己的 PCollection。
MapToFields 始终是一对一。要执行一对多映射,可以先将字段映射到可迭代类型,然后将此转换与 Explode 转换结合使用,该转换将发出多个值,每个值对应于已展开字段的值。
// Inside your ParDo's DoFn, you can emit an element to a specific output PCollection by providing a
// MultiOutputReceiver to your process method, and passing in the appropriate TupleTag to obtain an OutputReceiver.
// After your ParDo, extract the resulting output PCollections from the returned PCollectionTuple.
// Based on the previous example, this shows the DoFn emitting to the main output and two additional outputs.
.of(new DoFn<String, String>() {
public void processElement(@Element String word, MultiOutputReceiver out) {
if (word.length() <= wordLengthCutOff) {
// Emit short word to the main output.
// In this example, it is the output with tag wordsBelowCutOffTag.
out.get(wordsBelowCutOffTag).output(word);
} else {
// Emit long word length to the output with tag wordLengthsAboveCutOffTag.
out.get(wordLengthsAboveCutOffTag).output(word.length());
}
if (word.startsWith("MARKER")) {
// Emit word to the output with tag markedWordsTag.
out.get(markedWordsTag).output(word);
}
}}));# Inside your ParDo's DoFn, you can emit an element to a specific output by wrapping the value and the output tag (str).
# using the pvalue.OutputValue wrapper class.
# Based on the previous example, this shows the DoFn emitting to the main output and two additional outputs.
class ProcessWords(beam.DoFn):
def process(self, element, cutoff_length, marker):
if len(element) <= cutoff_length:
# Emit this short word to the main output.
yield element
else:
# Emit this word's long length to the 'above_cutoff_lengths' output.
yield pvalue.TaggedOutput('above_cutoff_lengths', len(element))
if element.startswith(marker):
# Emit this word to a different output with the 'marked strings' tag.
yield pvalue.TaggedOutput('marked strings', element)
# Producing multiple outputs is also available in Map and FlatMap.
# Here is an example that uses FlatMap and shows that the tags do not need to be specified ahead of time.
def even_odd(x):
yield pvalue.TaggedOutput('odd' if x % 2 else 'even', x)
if x % 10 == 0:
yield x
results = numbers | beam.FlatMap(even_odd).with_outputs()
evens = results.even
odds = results.odd
tens = results[None] # the undeclared main output// processWords is a DoFn that has 3 output PCollections. The emitter functions
// are matched in positional order to the PCollections returned by beam.ParDo3.
func processWords(word string, emitBelowCutoff, emitAboveCutoff, emitMarked func(string)) {
const cutOff = 5
if len(word) < cutOff {
emitBelowCutoff(word)
} else {
emitAboveCutoff(word)
}
if isMarkedWord(word) {
emitMarked(word)
}
}
// processWordsMixed demonstrates mixing an emitter, with a standard return.
// If a standard return is used, it will always be the first returned PCollection,
// followed in positional order by the emitter functions.
func processWordsMixed(word string, emitMarked func(string)) int {
if isMarkedWord(word) {
emitMarked(word)
}
return len(word)
}
func init() {
register.Function4x0(processWords)
register.Function2x1(processWordsMixed)
// 1 input of type string => Emitter1[string]
register.Emitter1[string]()
}const to_split = words.flatMap(function* (word) {
if (word.length < 5) {
yield { below: word };
} else {
yield { above: word };
}
if (isMarkedWord(word)) {
yield { marked: word };
}
});- type: MapToFields
input: SomeProducingTransform
config:
language: python
fields:
word: "line.split()"
- type: Explode
input: MapToFields
config:
fields: word4.5.3. 在您的 DoFn 中访问附加参数
除了元素和 OutputReceiver 之外,Beam 还将为您的 DoFn 的 @ProcessElement 方法填充其他参数。这些参数的任何组合都可以按任何顺序添加到您的处理方法中。
除了元素之外,Beam 还将为您的 DoFn 的 process 方法填充其他参数。这些参数可以通过将访问器放在上下文参数中获得,就像侧输入一样。
除了元素之外,Beam 还将为您的 DoFn 的 process 方法填充其他参数。这些参数可以通过将访问器放在上下文参数中获得,就像侧输入一样。
除了元素之外,Beam 还将为您的 DoFn 的 ProcessElement 方法填充其他参数。这些参数的任何组合都可以按标准顺序添加到您的处理方法中。
context.Context:为了支持合并的日志记录和用户定义的指标,可以请求 context.Context 参数。根据 Go 惯例,如果存在,则必须是 DoFn 方法的第一个参数。
func MyDoFn(ctx context.Context, word string) string { ... }时间戳:要访问输入元素的时间戳,请添加一个使用 @Timestamp 注释并类型为 Instant 的参数。例如
时间戳:要访问输入元素的时间戳,请添加一个关键字参数,默认值为 DoFn.TimestampParam。例如
时间戳:要访问输入元素的时间戳,请在元素之前添加一个 beam.EventTime 参数。例如
时间戳:要访问输入元素所属的窗口,请将 pardo.windowParam() 添加到上下文参数中。
.of(new DoFn<String, String>() {
public void processElement(@Element String word, @Timestamp Instant timestamp) {
}})import apache_beam as beam
class ProcessRecord(beam.DoFn):
def process(self, element, timestamp=beam.DoFn.TimestampParam):
# access timestamp of element.
passfunc MyDoFn(ts beam.EventTime, word string) string { ... }function processFn(element, context) {
return context.timestamp.lookup();
}
pcoll.map(processFn, { timestamp: pardo.timestampParam() });窗口:要访问输入元素所属的窗口,请添加一个与输入 PCollection 使用的窗口类型相同的参数。如果参数是窗口类型(BoundedWindow 的子类),但不匹配输入 PCollection,则会引发错误。如果一个元素属于多个窗口(例如,这将在使用 SlidingWindows 时发生),则 @ProcessElement 方法将针对该元素被多次调用,每个窗口调用一次。例如,当使用固定窗口时,窗口的类型为 IntervalWindow。
窗口:要访问输入元素所属的窗口,请添加一个关键字参数,默认值为 DoFn.WindowParam。如果一个元素属于多个窗口(例如,这将在使用 SlidingWindows 时发生),则 process 方法将针对该元素被多次调用,每个窗口调用一次。
窗口: 要访问输入元素所在的窗口,请在元素之前添加 beam.Window 参数。如果一个元素落在多个窗口中(例如,当使用滑动窗口时会发生这种情况),那么 ProcessElement 方法将为该元素调用多次,每个窗口调用一次。由于 beam.Window 是一个接口,因此可以对窗口的具体实现进行类型断言。例如,当使用固定窗口时,窗口的类型为 window.IntervalWindow。
窗口: 要访问输入元素所在的窗口,请在上下文参数中添加 pardo.windowParam()。如果一个元素落在多个窗口中(例如,当使用 SlidingWindows 时会发生这种情况),那么该函数将为该元素调用多次,每个窗口调用一次。
.of(new DoFn<String, String>() {
public void processElement(@Element String word, IntervalWindow window) {
}})import apache_beam as beam
class ProcessRecord(beam.DoFn):
def process(self, element, window=beam.DoFn.WindowParam):
# access window e.g. window.end.micros
passfunc MyDoFn(w beam.Window, word string) string {
iw := w.(window.IntervalWindow)
...
}pcoll.map(processWithWindow, { timestamp: pardo.windowParam() });PaneInfo: 当使用触发器时,Beam 提供了一个 PaneInfo 对象,其中包含有关当前触发的信息。使用 PaneInfo,您可以确定这是否是早期触发或晚期触发,以及该窗口已经为该键触发了多少次。
PaneInfo: 当使用触发器时,Beam 提供了一个 DoFn.PaneInfoParam 对象,其中包含有关当前触发的信息。使用 DoFn.PaneInfoParam,您可以确定这是否是早期触发或晚期触发,以及该窗口已经为该键触发了多少次。Python SDK 中此功能的实现尚未完全完成;请参阅 问题 17821了解更多信息。
PaneInfo: 当使用触发器时,Beam 提供了 beam.PaneInfo 对象,其中包含有关当前触发的信息。使用 beam.PaneInfo,您可以确定这是否是早期触发或晚期触发,以及该窗口已经为该键触发了多少次。
窗口: 要访问输入元素所在的窗口,请在上下文参数中添加 pardo.paneInfoParam()。使用 beam.PaneInfo,您可以确定这是否是早期触发或晚期触发,以及该窗口已经为该键触发了多少次。
.of(new DoFn<String, String>() {
public void processElement(@Element String word, PaneInfo paneInfo) {
}})import apache_beam as beam
class ProcessRecord(beam.DoFn):
def process(self, element, pane_info=beam.DoFn.PaneInfoParam):
# access pane info, e.g. pane_info.is_first, pane_info.is_last, pane_info.timing
passfunc extractWordsFn(pn beam.PaneInfo, line string, emitWords func(string)) {
if pn.Timing == typex.PaneEarly || pn.Timing == typex.PaneOnTime {
// ... perform operation ...
}
if pn.Timing == typex.PaneLate {
// ... perform operation ...
}
if pn.IsFirst {
// ... perform operation ...
}
if pn.IsLast {
// ... perform operation ...
}
words := strings.Split(line, " ")
for _, w := range words {
emitWords(w)
}
}pcoll.map(processWithPaneInfo, { timestamp: pardo.paneInfoParam() });PipelineOptions: 始终可以通过将其作为参数添加到处理方法中来访问当前管道的 PipelineOptions。
.of(new DoFn<String, String>() {
public void processElement(@Element String word, PipelineOptions options) {
}})@OnTimer 方法也可以访问许多这些参数。Timestamp、Window、键、PipelineOptions、OutputReceiver 和 MultiOutputReceiver 参数都可以在 @OnTimer 方法中访问。此外,@OnTimer 方法可以接受类型为 TimeDomain 的参数,该参数表示计时器是基于事件时间还是处理时间。有关计时器的更多详细信息,请参阅 Apache Beam 的及时(和有状态)处理 博客文章。
计时器和状态: 除了上述参数之外,用户定义的计时器和状态参数也可以在有状态的 DoFn 中使用。有关计时器和状态的更多详细信息,请参阅 Apache Beam 的及时(和有状态)处理 博客文章。
计时器和状态: 用户定义的状态和计时器参数可以在有状态的 DoFn 中使用。有关计时器和状态的更多详细信息,请参阅 Apache Beam 的及时(和有状态)处理 博客文章。
计时器和状态: 此功能尚未在 Typescript SDK 中实现,但我们欢迎 贡献。在此期间,希望使用状态和计时器的 Typescript 管道可以使用 跨语言转换 来实现。
class StatefulDoFn(beam.DoFn):
"""An example stateful DoFn with state and timer"""
BUFFER_STATE_1 = BagStateSpec('buffer1', beam.BytesCoder())
BUFFER_STATE_2 = BagStateSpec('buffer2', beam.VarIntCoder())
WATERMARK_TIMER = TimerSpec('watermark_timer', TimeDomain.WATERMARK)
def process(self,
element,
timestamp=beam.DoFn.TimestampParam,
window=beam.DoFn.WindowParam,
buffer_1=beam.DoFn.StateParam(BUFFER_STATE_1),
buffer_2=beam.DoFn.StateParam(BUFFER_STATE_2),
watermark_timer=beam.DoFn.TimerParam(WATERMARK_TIMER)):
# Do your processing here
key, value = element
# Read all the data from buffer1
all_values_in_buffer_1 = [x for x in buffer_1.read()]
if StatefulDoFn._is_clear_buffer_1_required(all_values_in_buffer_1):
# clear the buffer data if required conditions are met.
buffer_1.clear()
# add the value to buffer 2
buffer_2.add(value)
if StatefulDoFn._all_condition_met():
# Clear the timer if certain condition met and you don't want to trigger
# the callback method.
watermark_timer.clear()
yield element
@on_timer(WATERMARK_TIMER)
def on_expiry_1(self,
timestamp=beam.DoFn.TimestampParam,
window=beam.DoFn.WindowParam,
key=beam.DoFn.KeyParam,
buffer_1=beam.DoFn.StateParam(BUFFER_STATE_1),
buffer_2=beam.DoFn.StateParam(BUFFER_STATE_2)):
# Window and key parameters are really useful especially for debugging issues.
yield 'expired1'
@staticmethod
def _all_condition_met():
# some logic
return True
@staticmethod
def _is_clear_buffer_1_required(buffer_1_data):
# Some business logic
return True// stateAndTimersFn is an example stateful DoFn with state and a timer.
type stateAndTimersFn struct {
Buffer1 state.Bag[string]
Buffer2 state.Bag[int64]
Watermark timers.EventTime
}
func (s *stateAndTimersFn) ProcessElement(sp state.Provider, tp timers.Provider, w beam.Window, key string, value int64, emit func(string, int64)) error {
// ... handle processing elements here, set a callback timer...
// Read all the data from Buffer1 in this window.
vals, ok, err := s.Buffer1.Read(sp)
if err != nil {
return err
}
if ok && s.shouldClearBuffer(vals) {
// clear the buffer data if required conditions are met.
s.Buffer1.Clear(sp)
}
// Add the value to Buffer2.
s.Buffer2.Add(sp, value)
if s.allConditionsMet() {
// Clear the timer if certain condition met and you don't want to trigger
// the callback method.
s.Watermark.Clear(tp)
}
emit(key, value)
return nil
}
func (s *stateAndTimersFn) OnTimer(sp state.Provider, tp timers.Provider, w beam.Window, key string, timer timers.Context, emit func(string, int64)) error {
// Window and key parameters are really useful especially for debugging issues.
switch timer.Family {
case s.Watermark.Family:
// timer expired, emit a different signal
emit(key, -1)
}
return nil
}
func (s *stateAndTimersFn) shouldClearBuffer([]string) bool {
// some business logic
return false
}
func (s *stateAndTimersFn) allConditionsMet() bool {
// other business logic
return true
}// Not yet implemented.
4.6. 复合转换
转换可以具有嵌套结构,其中复杂转换执行多个更简单的转换(例如,多个 ParDo、Combine、GroupByKey 甚至其他复合转换)。这些转换称为复合转换。将多个转换嵌套到单个复合转换中可以使您的代码更模块化,更易于理解。
Beam SDK 附带了许多有用的复合转换。有关转换列表,请参阅 API 参考页面。
4.6.1. 复合转换示例
CountWords 转换是 WordCount 示例程序 中的复合转换示例。CountWords 是一个 PTransform 子类,它包含多个嵌套转换。
在其 expand 方法中, 该 CountWords 转换应用以下转换操作
- 它对输入文本行
PCollection应用ParDo,生成一个包含单个单词的输出PCollection。 - 它对包含单词的
PCollection应用 Beam SDK 库转换Count,生成一个包含键值对的PCollection。每个键代表文本中的一个单词,每个值代表该单词在原始数据中出现的次数。
public static class CountWords extends PTransform<PCollection<String>,
PCollection<KV<String, Long>>> {
@Override
public PCollection<KV<String, Long>> expand(PCollection<String> lines) {
// Convert lines of text into individual words.
PCollection<String> words = lines.apply(
ParDo.of(new ExtractWordsFn()));
// Count the number of times each word occurs.
PCollection<KV<String, Long>> wordCounts =
words.apply(Count.<String>perElement());
return wordCounts;
}
}# The CountWords Composite Transform inside the WordCount pipeline.
@beam.ptransform_fn
def CountWords(pcoll):
return (
pcoll
# Convert lines of text into individual words.
| 'ExtractWords' >> beam.ParDo(ExtractWordsFn())
# Count the number of times each word occurs.
| beam.combiners.Count.PerElement()
# Format each word and count into a printable string.
| 'FormatCounts' >> beam.ParDo(FormatCountsFn()))// CountWords is a function that builds a composite PTransform
// to count the number of times each word appears.
func CountWords(s beam.Scope, lines beam.PCollection) beam.PCollection {
// A subscope is required for a function to become a composite transform.
// We assign it to the original scope variable s to shadow the original
// for the rest of the CountWords function.
s = s.Scope("CountWords")
// Since the same subscope is used for the following transforms,
// they are in the same composite PTransform.
// Convert lines of text into individual words.
words := beam.ParDo(s, extractWordsFn, lines)
// Count the number of times each word occurs.
wordCounts := stats.Count(s, words)
// Return any PCollections that should be available after
// the composite transform.
return wordCounts
}function countWords(lines: PCollection<string>) {
return lines //
.map((s: string) => s.toLowerCase())
.flatMap(function* splitWords(line: string) {
yield* line.split(/[^a-z]+/);
})
.apply(beam.countPerElement());
}
const counted = lines.apply(countWords);注意: 由于
Count本身就是一个复合转换,因此CountWords也是一个嵌套复合转换。
4.6.2. 创建复合转换
Typescript SDK 中的 PTransform 只是一个接受并返回 PValue(例如 PCollection)的函数。
要创建自己的复合转换,请创建 PTransform 类的子类并覆盖 expand 方法以指定实际的处理逻辑。然后,您可以像使用 Beam SDK 中的内置转换一样使用此转换。
对于 PTransform 类类型参数,您将传递转换作为输入接受的 PCollection 类型,以及转换作为输出生成的类型。要将多个 PCollection 作为输入,或生成多个 PCollection 作为输出,请对相关类型参数使用其中一个多集合类型。
要创建自己的复合 PTransform,请在当前管道作用域变量上调用 Scope 方法。传递给此新子 Scope 的转换将成为同一复合 PTransform 的一部分。
为了能够重复使用您的复合体,请在正常的 Go 函数或方法中构建它。此函数接受一个作用域和输入 PCollections,并返回它生成的任何输出 PCollections。注意: 这样的函数不能直接传递给 ParDo 函数。
以下代码示例展示了如何声明一个 PTransform,它接受一个包含 String 的 PCollection 作为输入,并输出一个包含 Integer 的 PCollection
static class ComputeWordLengths
extends PTransform<PCollection<String>, PCollection<Integer>> {
...
}class ComputeWordLengths(beam.PTransform):
def expand(self, pcoll):
# Transform logic goes here.
return pcoll | beam.Map(lambda x: len(x))// CountWords is a function that builds a composite PTransform
// to count the number of times each word appears.
func CountWords(s beam.Scope, lines beam.PCollection) beam.PCollection {
// A subscope is required for a function to become a composite transform.
// We assign it to the original scope variable s to shadow the original
// for the rest of the CountWords function.
s = s.Scope("CountWords")
// Since the same subscope is used for the following transforms,
// they are in the same composite PTransform.
// Convert lines of text into individual words.
words := beam.ParDo(s, extractWordsFn, lines)
// Count the number of times each word occurs.
wordCounts := stats.Count(s, words)
// Return any PCollections that should be available after
// the composite transform.
return wordCounts
}在您的 PTransform 子类中,您需要覆盖 expand 方法。expand 方法是您添加 PTransform 的处理逻辑的地方。您的 expand 覆盖必须接受适当类型的输入 PCollection 作为参数,并指定输出 PCollection 作为返回值。
以下代码示例展示了如何覆盖上一个示例中声明的 ComputeWordLengths 类的 expand 方法
以下代码示例展示了如何调用 CountWords 复合 PTransform,并将其添加到您的管道中
static class ComputeWordLengths
extends PTransform<PCollection<String>, PCollection<Integer>> {
@Override
public PCollection<Integer> expand(PCollection<String>) {
...
// transform logic goes here
...
}class ComputeWordLengths(beam.PTransform):
def expand(self, pcoll):
# Transform logic goes here.
return pcoll | beam.Map(lambda x: len(x))lines := ... // a PCollection of strings.
// A Composite PTransform function is called like any other function.
wordCounts := CountWords(s, lines) // returns a PCollection<KV<string,int>>
只要您覆盖 PTransform 子类中的 expand 方法以接受适当的输入 PCollection(s)并返回相应的输出 PCollection(s),您就可以包含任意数量的转换。这些转换可以包括核心转换、复合转换或 Beam SDK 库中包含的转换。
您的复合 PTransform 可以包含任意数量的转换。这些转换可以包括核心转换、其他复合转换或 Beam SDK 库中包含的转换。它们还可以使用和返回任意数量的 PCollection,只要需要即可。
您的复合转换的参数和返回值必须与整个转换的初始输入类型和最终返回类型匹配,即使转换的中间数据类型发生了多次变化。
注意: PTransform 的 expand 方法不应由转换的用户直接调用。相反,您应该在 PCollection 本身上调用 apply 方法,并使用转换作为参数。这允许转换嵌套在管道结构中。
4.6.3. PTransform 样式指南
该 PTransform 样式指南 包含此处未包含的其他信息,例如样式指南、日志记录和测试指南以及特定于语言的注意事项。当您要编写新的复合 PTransforms 时,该指南是一个有用的起点。
5. 管道 I/O
当您创建管道时,您通常需要从某个外部来源读取数据,例如文件或数据库。同样,您可能希望您的管道将其结果数据输出到外部存储系统。Beam 为 许多常见的數據存储类型 提供了读写转换。如果您希望您的管道读取或写入内置转换不支持的數據存储格式,您可以 实现自己的读写转换。
5.1. 读取输入数据
读取转换从外部来源读取数据,并返回数据的 PCollection 表示,供您的管道使用。您可以在构建管道时使用读取转换来创建新的 PCollection,尽管在管道的开始处这样做最为常见。
PCollection<String> lines = p.apply(TextIO.read().from("gs://some/inputData.txt"));lines = pipeline | beam.io.ReadFromText('gs://some/inputData.txt')lines := textio.Read(scope, 'gs://some/inputData.txt')
5.2. 编写输出数据
写入转换将 PCollection 中的数据写入外部數據源。您通常在管道的末尾使用写入转换来输出管道的最终结果。但是,您可以在管道中的任何位置使用写入转换来输出 PCollection 的数据。
output.apply(TextIO.write().to("gs://some/outputData"));output | beam.io.WriteToText('gs://some/outputData')textio.Write(scope, 'gs://some/inputData.txt', output)
5.3. 基于文件的输入和输出数据
5.3.1. 从多个位置读取
许多读取转换支持从匹配您提供的 glob 运算符的多个输入文件读取数据。请注意,glob 运算符是特定于文件系统的,并且遵循特定于文件系统的 一致性模型。以下 TextIO 示例使用 glob 运算符(*)来读取给定位置中所有具有前缀“input-”和后缀“.csv”的匹配输入文件
p.apply("ReadFromText",
TextIO.read().from("protocol://my_bucket/path/to/input-*.csv"));lines = pipeline | 'ReadFromText' >> beam.io.ReadFromText(
'path/to/input-*.csv')lines := textio.Read(scope, "path/to/input-*.csv")要将来自不同来源的数据读取到单个 PCollection 中,请分别读取每个来源,然后使用 Flatten 转换创建一个单个 PCollection。
5.3.2. 写入多个输出文件
对于基于文件输出数据,写入转换默认情况下写入多个输出文件。当您将输出文件名传递给写入转换时,文件名将用作写入转换生成的全部输出文件的名称前缀。您可以通过指定后缀将后缀追加到每个输出文件。
以下写入转换示例将多个输出文件写入一个位置。每个文件都有前缀“numbers”,一个数字标记和后缀“.csv”。
records.apply("WriteToText",
TextIO.write().to("protocol://my_bucket/path/to/numbers")
.withSuffix(".csv"));filtered_words | 'WriteToText' >> beam.io.WriteToText(
'/path/to/numbers', file_name_suffix='.csv')// The Go SDK textio doesn't support sharding on writes yet.
// See https://github.com/apache/beam/issues/21031 for ways
// to contribute a solution.
5.4. Beam 提供的 I/O 转换
有关当前可用的 I/O 转换的列表,请参阅 Beam 提供的 I/O 转换 页面。
6. 模式
通常,正在处理的记录类型具有明显的结构。常见的 Beam 源生成 JSON、Avro、协议缓冲区或数据库行对象;所有这些类型都具有明确定义的结构,这些结构通常可以通过检查类型来确定。即使在 SDK 管道中,简单的 Java POJOs(或其他语言中的等效结构)也经常用作中间类型,它们也具有可以通过检查类推断出的清晰结构。通过理解管道记录的结构,我们可以为数据处理提供更加简洁的 API。
6.1. 什么是模式?
大多数结构化记录共享一些共同特征
- 它们可以细分为单独的命名字段。字段通常具有字符串名称,但有时(例如,在索引元组的情况下)具有数字索引而不是名称。
- 字段可以具有的原始类型列表有限。这些类型通常与大多数编程语言中的原始类型匹配:int、long、string 等。
- 通常,字段类型可以标记为可选(有时称为可空)或必需。
通常,记录具有嵌套结构。当字段本身具有子字段时,就会出现嵌套结构,因此字段本身的类型具有模式。字段是数组或映射类型也是这些结构化记录的常见特征。
例如,考虑以下模式,它代表一家虚构的电子商务公司的操作
Purchase
| 字段名称 | 字段类型 |
|---|---|
| userId | STRING |
| itemId | INT64 |
| shippingAddress | ROW(ShippingAddress) |
| cost | INT64 |
| transactions | ARRAY[ROW(Transaction)] |
ShippingAddress
| 字段名称 | 字段类型 |
|---|---|
| streetAddress | STRING |
| city | STRING |
| state | 可空字符串 |
| country | STRING |
| postCode | STRING |
Transaction
| 字段名称 | 字段类型 |
|---|---|
| bank | STRING |
| purchaseAmount | 双精度浮点数 |
购买事件记录由上述购买模式表示。每个购买事件包含一个送货地址,它是一个嵌套行,包含其自己的模式。每个购买也包含一个信用卡交易数组(一个列表,因为购买可能跨多个信用卡拆分);交易列表中的每个项目都是一个具有自己模式的行。
这提供了一种抽象的类型描述,该描述独立于任何特定的编程语言。
模式为我们提供了一种 Beam 记录的类型系统,该系统独立于任何特定的编程语言类型。可能存在多个 Java 类,它们都具有相同的模式(例如 Protocol-Buffer 类或 POJO 类),并且 Beam 将允许我们无缝地在这些类型之间进行转换。模式还提供了一种简单的方法来推断跨不同编程语言 API 的类型。
具有模式的 PCollection 不需要指定 Coder,因为 Beam 知道如何对模式行进行编码和解码;Beam 使用一个特殊的编码器来对模式类型进行编码。
6.2. 编程语言类型的模式
虽然模式本身是独立于语言的,但它们被设计成自然地嵌入到正在使用的 Beam SDK 的编程语言中。这允许 Beam 用户继续使用本机类型,同时获得 Beam 了解其元素模式的优势。
在 Java 中,您可以使用以下类集来表示购买模式。Beam 将根据类的成员自动推断出正确的模式。
在 Python 中,您可以使用以下类集来表示购买模式。Beam 将根据类的成员自动推断出正确的模式。
在 Go 中,模式编码默认用于结构类型,导出的字段成为模式的一部分。Beam 将根据结构的字段和字段标签及其顺序自动推断模式。
在 Typescript 中,JSON 对象用于表示模式化的数据。不幸的是,Typescript 中的类型信息不会传播到运行时层,因此需要在某些地方手动指定(例如,在使用跨语言管道时)。
在 Beam YAML 中,所有转换都生成并接受模式化数据,用于验证管道。
在某些情况下,Beam 无法弄清楚映射函数的输出类型。在这种情况下,您可以使用 JSON 模式语法 手动指定它。
@DefaultSchema(JavaBeanSchema.class)
public class Purchase {
public String getUserId(); // Returns the id of the user who made the purchase.
public long getItemId(); // Returns the identifier of the item that was purchased.
public ShippingAddress getShippingAddress(); // Returns the shipping address, a nested type.
public long getCostCents(); // Returns the cost of the item.
public List<Transaction> getTransactions(); // Returns the transactions that paid for this purchase (returns a list, since the purchase might be spread out over multiple credit cards).
@SchemaCreate
public Purchase(String userId, long itemId, ShippingAddress shippingAddress, long costCents,
List<Transaction> transactions) {
...
}
}
@DefaultSchema(JavaBeanSchema.class)
public class ShippingAddress {
public String getStreetAddress();
public String getCity();
@Nullable public String getState();
public String getCountry();
public String getPostCode();
@SchemaCreate
public ShippingAddress(String streetAddress, String city, @Nullable String state, String country,
String postCode) {
...
}
}
@DefaultSchema(JavaBeanSchema.class)
public class Transaction {
public String getBank();
public double getPurchaseAmount();
@SchemaCreate
public Transaction(String bank, double purchaseAmount) {
...
}
}import typing
class Purchase(typing.NamedTuple):
user_id: str # The id of the user who made the purchase.
item_id: int # The identifier of the item that was purchased.
shipping_address: ShippingAddress # The shipping address, a nested type.
cost_cents: int # The cost of the item
transactions: typing.Sequence[Transaction] # The transactions that paid for this purchase (a list, since the purchase might be spread out over multiple credit cards).
class ShippingAddress(typing.NamedTuple):
street_address: str
city: str
state: typing.Optional[str]
country: str
postal_code: str
class Transaction(typing.NamedTuple):
bank: str
purchase_amount: floattype Purchase struct {
// ID of the user who made the purchase.
UserID string `beam:"userId"`
// Identifier of the item that was purchased.
ItemID int64 `beam:"itemId"`
// The shipping address, a nested type.
ShippingAddress ShippingAddress `beam:"shippingAddress"`
// The cost of the item in cents.
Cost int64 `beam:"cost"`
// The transactions that paid for this purchase.
// A slice since the purchase might be spread out over multiple
// credit cards.
Transactions []Transaction `beam:"transactions"`
}
type ShippingAddress struct {
StreetAddress string `beam:"streetAddress"`
City string `beam:"city"`
State *string `beam:"state"`
Country string `beam:"country"`
PostCode string `beam:"postCode"`
}
type Transaction struct {
Bank string `beam:"bank"`
PurchaseAmount float64 `beam:"purchaseAmount"`
}const pcoll = root
.apply(
beam.create([
{ intField: 1, stringField: "a" },
{ intField: 2, stringField: "b" },
])
)
// Let beam know the type of the elements by providing an exemplar.
.apply(beam.withRowCoder({ intField: 0, stringField: "" }));type: MapToFields
config:
language: python
fields:
new_field:
expression: "hex(weight)"
output_type: { "type": "string" }使用 JavaBean 类如上所述是将模式映射到 Java 类的一种方法。但是,多个 Java 类可能具有相同的模式,在这种情况下,不同的 Java 类型通常可以互换使用。Beam 将在具有匹配模式的类型之间添加隐式转换。例如,上面的 Transaction 类与以下类具有相同的模式
@DefaultSchema(JavaFieldSchema.class)
public class TransactionPojo {
public String bank;
public double purchaseAmount;
}因此,如果我们有两个 PCollection 如下
PCollection<Transaction> transactionBeans = readTransactionsAsJavaBean();
PCollection<TransactionPojos> transactionPojos = readTransactionsAsPojo();那么这两个 PCollection 将具有相同的模式,即使它们的 Java 类型不同。这意味着例如以下两个代码片段是有效的
transactionBeans.apply(ParDo.of(new DoFn<...>() {
@ProcessElement public void process(@Element TransactionPojo pojo) {
...
}
}));和
transactionPojos.apply(ParDo.of(new DoFn<...>() {
@ProcessElement public void process(@Element Transaction row) {
}
}));即使在两种情况下,@Element 参数都与 PCollection 的 Java 类型不同,但由于模式相同,Beam 将自动进行转换。内置的 Convert 转换也可以用于在具有等效模式的 Java 类型之间进行转换,如下文所述。
6.3. 模式定义
PCollection 的模式将该 PCollection 的元素定义为命名字段的有序列表。每个字段都有一个名称、一个类型以及可能的一组用户选项。字段的类型可以是原始类型或复合类型。以下是 Beam 目前支持的原始类型
| 类型 | 描述 |
|---|---|
| 字节 | 一个 8 位有符号值 |
| INT16 | 一个 16 位有符号值 |
| INT32 | 一个 32 位有符号值 |
| INT64 | 一个 64 位有符号值 |
| 十进制 | 任意精度的十进制类型 |
| 浮点数 | 一个 32 位 IEEE 754 浮点数 |
| 双精度浮点数 | 一个 64 位 IEEE 754 浮点数 |
| STRING | 一个字符串 |
| 日期时间 | 一个时间戳,表示为自纪元以来的毫秒数 |
| 布尔值 | 一个布尔值 |
| 字节 | 一个原始字节数组 |
一个字段也可以引用一个嵌套模式。在这种情况下,字段将具有类型 ROW,嵌套模式将是此字段类型的属性。
三种集合类型支持作为字段类型:ARRAY、ITERABLE 和 MAP
- **数组** 这表示一个重复的值类型,其中重复的元素可以具有任何支持的类型。支持嵌套行的数组,以及数组的数组。
- **可迭代** 这与数组类型非常相似,它表示一个重复的值,但其中所有项目的完整列表只有在迭代时才能知道。这适用于可迭代对象可能大于可用内存并由外部存储支持的情况(例如,这可能发生在由
GroupByKey返回的可迭代对象中)。重复的元素可以具有任何支持的类型。 - **地图** 这表示从键到值的关联映射。所有模式类型都支持键和值。包含映射类型的值不能用作任何分组操作中的键。
6.4. 逻辑类型
用户可以扩展模式类型系统以添加可以作为字段使用的自定义逻辑类型。逻辑类型由一个唯一标识符和一个参数标识。逻辑类型还指定一个用于存储的底层模式类型,以及与该类型的转换。例如,逻辑联合始终可以表示为具有可空字段的行,其中用户确保这些字段中只有一个在任何时候都被设置。但是,这可能很繁琐且难以管理。OneOf 逻辑类型提供了一个值类,它使管理类型作为联合变得更加容易,同时仍然使用具有可空字段的行作为其底层存储。每个逻辑类型还有一个唯一的标识符,以便它们可以被其他语言解释。下面列出了逻辑类型的更多示例。
6.4.1. 定义逻辑类型
要定义逻辑类型,您必须指定一个 Schema 类型来表示底层类型,以及该类型的唯一标识符。逻辑类型在模式类型之上强加了额外的语义。例如,表示纳秒时间戳的逻辑类型表示为包含 INT64 和 INT32 字段的模式。此模式本身并没有说明如何解释此类型,但是逻辑类型告诉您这表示纳秒时间戳,其中 INT64 字段表示秒,INT32 字段表示纳秒。
逻辑类型也由一个参数指定,该参数允许创建一类相关类型。例如,有限精度的十进制类型将有一个整数参数,指示表示多少位精度。参数由模式类型表示,因此它本身可以是一个复杂类型。
在 Java 中,逻辑类型指定为 LogicalType 类的子类。可以指定一个自定义 Java 类来表示逻辑类型,并且必须提供转换函数来在该 Java 类和底层 Schema 类型表示之间进行转换。例如,表示纳秒时间戳的逻辑类型可以按如下方式实现
在 Go 中,逻辑类型使用 beam.SchemaProvider 接口的自定义实现来指定。例如,表示纳秒时间戳的逻辑类型提供者可以按如下方式实现
在 Typescript 中,逻辑类型由 LogicalTypeInfo 接口定义,该接口将逻辑类型的 URN 与其表示形式以及它与该表示形式之间的转换相关联。
// A Logical type using java.time.Instant to represent the logical type.
public class TimestampNanos implements LogicalType<Instant, Row> {
// The underlying schema used to represent rows.
private final Schema SCHEMA = Schema.builder().addInt64Field("seconds").addInt32Field("nanos").build();
@Override public String getIdentifier() { return "timestampNanos"; }
@Override public FieldType getBaseType() { return schema; }
// Convert the representation type to the underlying Row type. Called by Beam when necessary.
@Override public Row toBaseType(Instant instant) {
return Row.withSchema(schema).addValues(instant.getEpochSecond(), instant.getNano()).build();
}
// Convert the underlying Row type to an Instant. Called by Beam when necessary.
@Override public Instant toInputType(Row base) {
return Instant.of(row.getInt64("seconds"), row.getInt32("nanos"));
}
...
}// Define a logical provider like so:
// TimestampNanos is a logical type using time.Time, but
// encodes as a schema type.
type TimestampNanos time.Time
func (tn TimestampNanos) Seconds() int64 {
return time.Time(tn).Unix()
}
func (tn TimestampNanos) Nanos() int32 {
return int32(time.Time(tn).UnixNano() % 1000000000)
}
// tnStorage is the storage schema for TimestampNanos.
type tnStorage struct {
Seconds int64 `beam:"seconds"`
Nanos int32 `beam:"nanos"`
}
var (
// reflect.Type of the Value type of TimestampNanos
tnType = reflect.TypeOf((*TimestampNanos)(nil)).Elem()
tnStorageType = reflect.TypeOf((*tnStorage)(nil)).Elem()
)
// TimestampNanosProvider implements the beam.SchemaProvider interface.
type TimestampNanosProvider struct{}
// FromLogicalType converts checks if the given type is TimestampNanos, and if so
// returns the storage type.
func (p *TimestampNanosProvider) FromLogicalType(rt reflect.Type) (reflect.Type, error) {
if rt != tnType {
return nil, fmt.Errorf("unable to provide schema.LogicalType for type %v, want %v", rt, tnType)
}
return tnStorageType, nil
}
// BuildEncoder builds a Beam schema encoder for the TimestampNanos type.
func (p *TimestampNanosProvider) BuildEncoder(rt reflect.Type) (func(any, io.Writer) error, error) {
if _, err := p.FromLogicalType(rt); err != nil {
return nil, err
}
enc, err := coder.RowEncoderForStruct(tnStorageType)
if err != nil {
return nil, err
}
return func(iface any, w io.Writer) error {
v := iface.(TimestampNanos)
return enc(tnStorage{
Seconds: v.Seconds(),
Nanos: v.Nanos(),
}, w)
}, nil
}
// BuildDecoder builds a Beam schema decoder for the TimestampNanos type.
func (p *TimestampNanosProvider) BuildDecoder(rt reflect.Type) (func(io.Reader) (any, error), error) {
if _, err := p.FromLogicalType(rt); err != nil {
return nil, err
}
dec, err := coder.RowDecoderForStruct(tnStorageType)
if err != nil {
return nil, err
}
return func(r io.Reader) (any, error) {
s, err := dec(r)
if err != nil {
return nil, err
}
tn := s.(tnStorage)
return TimestampNanos(time.Unix(tn.Seconds, int64(tn.Nanos))), nil
}, nil
}
// Register it like so:
beam.RegisterSchemaProvider(tnType, &TimestampNanosProvider{})// Register a logical type:
class Foo {
constructor(public value: string) {}
}
requireForSerialization("apache-beam", { Foo });
row_coder.registerLogicalType({
urn: "beam:logical_type:typescript_foo:v1",
reprType: row_coder.RowCoder.inferTypeFromJSON("string", false),
toRepr: (foo) => foo.value,
fromRepr: (value) => new Foo(value),
});
// And use it as follows:
const pcoll = root
.apply(beam.create([new Foo("a"), new Foo("b")]))
// Use beamLogicalType in the exemplar to indicate its use.
.apply(
beam.withRowCoder({
beamLogicalType: "beam:logical_type:typescript_foo:v1",
} as any)
);6.4.2. 有用的逻辑类型
目前,Python SDK 提供了最小的便利逻辑类型,除了处理 MicrosInstant 之外。
目前,Go SDK 提供了最小的便利逻辑类型,除了处理其他整数基元和 time.Time 之外。
枚举类型
此便利构建器尚未在 Python SDK 中存在。
此便利构建器尚未在 Go SDK 中存在。
此逻辑类型允许创建由一组命名常量组成的枚举类型。
Schema schema = Schema.builder()
…
.addLogicalTypeField("color", EnumerationType.create("RED", "GREEN", "BLUE"))
.build();此字段的值存储在行中作为 INT32 类型,但是逻辑类型定义了一个值类型,它允许您以字符串或值的形式访问枚举。例如
EnumerationType.Value enumValue = enumType.valueOf("RED");
enumValue.getValue(); // Returns 0, the integer value of the constant.
enumValue.toString(); // Returns "RED", the string value of the constant
给定具有枚举字段的行对象,您也可以提取字段作为枚举值。
EnumerationType.Value enumValue = row.getLogicalTypeValue("color", EnumerationType.Value.class);从 Java POJO 和 JavaBean 自动推断模式会自动将 Java 枚举转换为 EnumerationType 逻辑类型。
OneOfType
此便利构建器尚未在 Python SDK 中存在。
此便利构建器尚未在 Go SDK 中存在。
OneOfType 允许在一组模式字段上创建不相交的联合类型。例如
Schema schema = Schema.builder()
…
.addLogicalTypeField("oneOfField",
OneOfType.create(Field.of("intField", FieldType.INT32),
Field.of("stringField", FieldType.STRING),
Field.of("bytesField", FieldType.BYTES)))
.build();此字段的值存储在行中作为另一个 Row 类型,其中所有字段都被标记为可空。但是,逻辑类型定义了一个 Value 对象,该对象包含一个枚举值,指示设置了哪个字段,并允许获取该字段
// Returns an enumeration indicating all possible case values for the enum.
// For the above example, this will be
// EnumerationType.create("intField", "stringField", "bytesField");
EnumerationType oneOfEnum = onOfType.getCaseEnumType();
// Creates an instance of the union with the string field set.
OneOfType.Value oneOfValue = oneOfType.createValue("stringField", "foobar");
// Handle the oneof
switch (oneOfValue.getCaseEnumType().toString()) {
case "intField":
return processInt(oneOfValue.getValue(Integer.class));
case "stringField":
return processString(oneOfValue.getValue(String.class));
case "bytesField":
return processBytes(oneOfValue.getValue(bytes[].class));
}在上面的示例中,我们在 switch 语句中使用了字段名称以供清晰起见,但是也可以使用枚举整数。
6.5. 创建模式
为了利用模式,您的 PCollection 必须附加一个模式。通常,源本身会将模式附加到 PCollection。例如,当使用 AvroIO 读取 Avro 文件时,源可以根据 Avro 模式自动推断 Beam 模式并将该模式附加到 Beam PCollection。但是,并非所有源都生成模式。此外,Beam 管道通常具有中间阶段和类型,这些阶段和类型也可以从模式的表达能力中获益。
6.5.1. 推断模式
不幸的是,Beam 无法在运行时访问 Typescript 的类型信息。必须使用 beam.withRowCoder 手动声明模式。另一方面,可以不显式声明模式的情况下使用 GroupBy 等模式感知操作。
Beam 能够从各种常见的 Java 类型中推断模式。@DefaultSchema 注释可用于告诉 Beam 从特定类型推断模式。注释采用 SchemaProvider 作为参数,并且对于常见的 Java 类型已经内置了 SchemaProvider 类。SchemaRegistry 也可以以编程方式调用,以用于无法对 Java 类型本身进行注释的情况。
Java POJO
POJO(普通旧 Java 对象)是一个 Java 对象,它不受任何限制,除了 Java 语言规范。POJO 可以包含作为基元、作为其他 POJO 或作为其集合映射或数组的成员变量。POJO 不必扩展预先指定的类或扩展任何特定接口。
如果 POJO 类使用 @DefaultSchema(JavaFieldSchema.class) 进行注释,Beam 将自动为此类推断模式。嵌套类受支持,以及具有 List、数组和 Map 字段的类。
例如,注释以下类会告诉 Beam 从此 POJO 类推断模式,并将其应用于任何 PCollection<TransactionPojo>。
@DefaultSchema(JavaFieldSchema.class)
public class TransactionPojo {
public final String bank;
public final double purchaseAmount;
@SchemaCreate
public TransactionPojo(String bank, double purchaseAmount) {
this.bank = bank;
this.purchaseAmount = purchaseAmount;
}
}
// Beam will automatically infer the correct schema for this PCollection. No coder is needed as a result.
PCollection<TransactionPojo> pojos = readPojos();@SchemaCreate 注解告诉 Beam 此构造函数可用于创建 TransactionPojo 的实例,假设构造函数参数与字段名相同。@SchemaCreate 也可用于注解类上的静态工厂方法,允许构造函数保持私有。如果没有 @SchemaCreate 注解,则所有字段必须是非最终的,并且类必须具有无参数构造函数。
还有几个其他有用的注解会影响 Beam 推断模式的方式。默认情况下,推断的模式字段名将与类字段名匹配。但是,@SchemaFieldName 可用于指定要用于模式字段的不同名称。@SchemaIgnore 可用于将特定类字段标记为从推断的模式中排除。例如,在一个类中通常会有短暂的字段,这些字段不应包含在模式中(例如,缓存哈希值以防止昂贵的哈希重新计算),并且可以使用 @SchemaIgnore 来排除这些字段。请注意,忽略的字段不会包含在这些记录的编码中。
在某些情况下,对 POJO 类进行注解并不方便,例如,如果 POJO 在管道作者不拥有的不同包中。在这些情况下,可以在管道的 main 函数中以编程方式触发模式推断,如下所示
pipeline.getSchemaRegistry().registerPOJO(TransactionPOJO.class);Java Bean
Java Bean 是在 Java 中创建可重用属性类的实际标准。虽然完整的标准具有许多特征,但关键特征是所有属性都通过 getter 和 setter 类访问,并且这些 getter 和 setter 的名称格式是标准化的。Java Bean 类可以使用 @DefaultSchema(JavaBeanSchema.class) 进行注解,Beam 将自动为此类推断模式。例如
@DefaultSchema(JavaBeanSchema.class)
public class TransactionBean {
public TransactionBean() { … }
public String getBank() { … }
public void setBank(String bank) { … }
public double getPurchaseAmount() { … }
public void setPurchaseAmount(double purchaseAmount) { … }
}
// Beam will automatically infer the correct schema for this PCollection. No coder is needed as a result.
PCollection<TransactionBean> beans = readBeans();@SchemaCreate 注解可用于指定构造函数或静态工厂方法,在这种情况下,setter 和无参数构造函数可以省略。
@DefaultSchema(JavaBeanSchema.class)
public class TransactionBean {
@SchemaCreate
Public TransactionBean(String bank, double purchaseAmount) { … }
public String getBank() { … }
public double getPurchaseAmount() { … }
}@SchemaFieldName 和 @SchemaIgnore 可用于更改推断的模式,就像使用 POJO 类一样。
AutoValue
Java 值类 notoriously 难以正确生成。为了正确实现值类,您必须创建很多样板代码。AutoValue 是一个流行的库,用于通过实现简单的抽象基类轻松生成此类类。
Beam 可以从 AutoValue 类推断模式。例如
@DefaultSchema(AutoValueSchema.class)
@AutoValue
public abstract class TransactionValue {
public abstract String getBank();
public abstract double getPurchaseAmount();
}这正是生成简单的 AutoValue 类所需的一切,上面的 @DefaultSchema 注解告诉 Beam 从中推断模式。这也允许 AutoValue 元素在 PCollection 中使用。
@SchemaFieldName 和 @SchemaIgnore 可用于更改推断的模式。
Beam 有一些不同的机制用于从 Python 代码推断模式。
NamedTuple 类
一个 NamedTuple 类是一个 Python 类,它包装一个 tuple,为每个元素分配一个名称并将其限制为特定类型。Beam 将自动推断具有 NamedTuple 输出类型的 PCollection 的模式。例如
class Transaction(typing.NamedTuple):
bank: str
purchase_amount: float
pc = input | beam.Map(lambda ...).with_output_types(Transaction)beam.Row 和 Select
还有一些方法可以创建 ad-hoc 模式声明。首先,您可以使用返回 beam.Row 实例的 lambda
input_pc = ... # {"bank": ..., "purchase_amount": ...}
output_pc = input_pc | beam.Map(lambda item: beam.Row(bank=item["bank"],
purchase_amount=item["purchase_amount"])有时,使用 Select 变换来表达相同的逻辑可能更简洁
input_pc = ... # {"bank": ..., "purchase_amount": ...}
output_pc = input_pc | beam.Select(bank=lambda item: item["bank"],
purchase_amount=lambda item: item["purchase_amount"])请注意,这些声明不包含关于 bank 和 purchase_amount 字段类型的任何特定信息,因此 Beam 将尝试推断类型信息。如果它无法做到,它将回退到通用类型 Any。有时这并不理想,您可以使用强制转换来确保 Beam 正确地推断 beam.Row 或 Select 中的类型
input_pc = ... # {"bank": ..., "purchase_amount": ...}
output_pc = input_pc | beam.Map(lambda item: beam.Row(bank=str(item["bank"]),
purchase_amount=float(item["purchase_amount"])))Beam 目前仅为 Go 结构体中的导出字段推断模式。
结构体
Beam 将自动推断用作 PCollection 元素的所有 Go 结构体的模式,并默认使用模式编码对它们进行编码。
type Transaction struct{
Bank string
PurchaseAmount float64
checksum []byte // ignored
}未导出的字段将被忽略,并且不能自动推断为模式的一部分。类型为 func、channel、unsafe.Pointer 或 uintptr 的字段将被推断忽略。接口类型的字段将被忽略,除非为它们注册了模式提供者。
默认情况下,模式字段名将与导出的结构体字段名匹配。在上面的示例中,“Bank” 和“PurchaseAmount” 是模式字段名。可以使用字段的结构体标记覆盖模式字段名。
type Transaction struct{
Bank string `beam:"bank"`
PurchaseAmount float64 `beam:"purchase_amount"`
}覆盖模式字段名对于跨语言变换的兼容性很有用,因为模式字段可能具有与 Go 导出字段不同的要求或限制。
6.6. 使用模式转换
PCollection 上的模式支持各种各样的关系变换。每个记录都是由命名字段组成的这一事实,使得可以进行简单且易于理解的聚合,这些聚合按名称引用字段,类似于 SQL 表达式中的聚合。
Beam 尚未在 Go 中原生支持模式变换。但是,它将使用以下行为实现。
6.6.1. 字段选择语法
模式的优势在于它们允许按名称引用元素字段。Beam 提供了一种用于引用字段的选择语法,包括嵌套字段和重复字段。这种语法在所有模式变换引用它们操作的字段时使用。这种语法也可以在 DoFn 中使用,以指定要处理的模式字段。
按名称寻址字段仍然保持类型安全,因为 Beam 会在构建管道图时检查模式是否匹配。如果指定了一个模式中不存在的字段,则管道将无法启动。此外,如果指定了一个与模式中该字段类型不匹配的类型的字段,则管道将无法启动。
字段名中不允许以下字符:. * [ ] { }
顶级字段
为了选择模式顶层的字段,请指定字段的名称。例如,要从购买的 PCollection 中选择用户的 id,您可以编写(使用 Select 变换)
purchases.apply(Select.fieldNames("userId"));input_pc = ... # {"user_id": ...,"bank": ..., "purchase_amount": ...}
output_pc = input_pc | beam.Select("user_id")嵌套字段
Python SDK 尚未开发对嵌套字段的支持。
Go SDK 尚未开发对嵌套字段的支持。
可以使用点运算符指定单个嵌套字段。例如,要仅选择邮寄地址的邮政编码,您可以编写
purchases.apply(Select.fieldNames("shippingAddress.postCode"));通配符
Python SDK 尚未开发对通配符的支持。
Go SDK 尚未开发对通配符的支持。
* 运算符可以在任何嵌套级别指定,以表示该级别上的所有字段。例如,要选择所有邮寄地址字段,您可以编写
purchases.apply(Select.fieldNames("shippingAddress.*"));数组
数组字段(其中数组元素类型为行)也可以访问元素类型的子字段。选择时,结果是一个包含所选子字段类型的数组。例如
Python SDK 尚未开发对数组字段的支持。
Go SDK 尚未开发对数组字段的支持。
purchases.apply(Select.fieldNames("transactions[].bank"));将导致包含具有元素类型字符串的数组字段的行,该字段包含每个交易的银行列表。
虽然建议在选择器中使用 [] 括号以清楚地表明正在选择数组元素,但为了简洁起见,可以省略它们。将来,将支持数组切片,允许选择数组的某些部分。
地图
地图字段(其中值类型为行)也可以访问值类型的子字段。选择时,结果是地图,其中键与原始地图中的键相同,但值是指定的类型。与数组类似,建议在选择器中使用 {} 花括号,以清楚地表明正在选择地图值元素,为了简洁起见,可以省略它们。将来,将支持地图键选择器,允许从地图中选择特定的键。例如,给定以下模式
PurchasesByType
| 字段名称 | 字段类型 |
|---|---|
| purchases | MAP{STRING, ROW{PURCHASE} |
以下
purchasesByType.apply(Select.fieldNames("purchases{}.userId"));Python SDK 尚未开发对地图字段的支持。
Go SDK 尚未开发对地图字段的支持。
将导致包含具有键类型字符串和值类型字符串的地图字段的行。选择的地图将包含原始地图中的所有键,并且值将是购买记录中包含的 userId。
虽然建议在选择器中使用 {} 括号以清楚地表明正在选择地图值元素,但为了简洁起见,可以省略它们。将来,将支持地图切片,允许从地图中选择特定的键。
6.6.2. 模式转换
Beam 提供了一组在模式上原生操作的变换。这些变换非常有表现力,允许根据命名模式字段进行选择和聚合。以下是一些有用模式变换的示例。
选择输入
通常,计算只对输入 PCollection 中的某些字段感兴趣。Select 变换允许您轻松地仅投影出感兴趣的字段。生成的 PCollection 的模式包含每个选定字段作为顶级字段。可以选择顶级字段和嵌套字段。例如,在 Purchase 模式中,您可以仅选择 userId 和 streetAddress 字段,如下所示
purchases.apply(Select.fieldNames("userId", "shippingAddress.streetAddress"));Python SDK 尚未开发对嵌套字段的支持。
Go SDK 尚未开发对嵌套字段的支持。
生成的 PCollection 将具有以下模式
| 字段名称 | 字段类型 |
|---|---|
| userId | STRING |
| streetAddress | STRING |
通配符选择也是如此。以下
purchases.apply(Select.fieldNames("userId", "shippingAddress.*"));Python SDK 尚未开发对通配符的支持。
Go SDK 尚未开发对通配符的支持。
将导致以下模式
| 字段名称 | 字段类型 |
|---|---|
| userId | STRING |
| streetAddress | STRING |
| city | STRING |
| state | 可空字符串 |
| country | STRING |
| postCode | STRING |
当选择嵌套在数组中的字段时,相同的规则适用,即每个选定字段在生成的行的顶级字段中单独出现。这意味着,如果从相同的嵌套行中选择多个字段,则每个选定字段将显示为自己的数组字段。例如
purchases.apply(Select.fieldNames( "transactions.bank", "transactions.purchaseAmount"));Python SDK 尚未开发对嵌套字段的支持。
Go SDK 尚未开发对嵌套字段的支持。
将导致以下模式
| 字段名称 | 字段类型 |
|---|---|
| bank | ARRAY[STRING] |
| purchaseAmount | ARRAY[DOUBLE] |
通配符选择等同于分别选择每个字段。
选择嵌套在地图中的字段具有与数组相同的语义。如果从地图中选择多个字段,则每个选定字段将扩展到其自己的地图,位于顶层。这意味着地图键集将被复制,每个选定字段一次。
有时,不同的嵌套行将具有相同名称的字段。选择这些字段中的多个字段会导致名称冲突,因为所有选定字段都放在相同的行模式中。当出现这种情况时,可以使用 Select.withFieldNameAs 生成器方法为选定字段提供备用名称。
Select 变换的另一个用途是将嵌套模式展平成单个扁平模式。例如
purchases.apply(Select.flattenedSchema());Python SDK 尚未开发对嵌套字段的支持。
Go SDK 尚未开发对嵌套字段的支持。
将导致以下模式
| 字段名称 | 字段类型 |
|---|---|
| userId | STRING |
| itemId | STRING |
| shippingAddress_streetAddress | STRING |
| shippingAddress_city | 可空字符串 |
| shippingAddress_state | STRING |
| shippingAddress_country | STRING |
| shippingAddress_postCode | STRING |
| costCents | INT64 |
| transactions_bank | ARRAY[STRING] |
| transactions_purchaseAmount | ARRAY[DOUBLE] |
分组聚合
Group 变换允许您简单地根据输入模式中的任意数量的字段对数据进行分组,将聚合应用于这些分组,并将这些聚合的结果存储在新的模式字段中。Group 变换的输出具有一个模式,该模式包含与执行的每个聚合相对应的字段。
GroupBy 变换允许您简单地根据输入模式中的任意数量的字段对数据进行分组,将聚合应用于这些分组,并将这些聚合的结果存储在新的模式字段中。GroupBy 变换的输出具有一个模式,该模式包含与执行的每个聚合相对应的字段。
Group 的最简单用法不指定任何聚合,在这种情况下,所有与提供的字段集匹配的输入都将分组到一个 ITERABLE 字段中。例如
GroupBy 的最简单用法不指定任何聚合,在这种情况下,所有与提供的字段集匹配的输入都将分组到一个 ITERABLE 字段中。例如
purchases.apply(Group.byFieldNames("userId", "bank"));input_pc = ... # {"user_id": ...,"bank": ..., "purchase_amount": ...}
output_pc = input_pc | beam.GroupBy('user_id','bank')Go SDK 尚未开发出对模式感知分组的支持。
此操作的输出模式为
| 字段名称 | 字段类型 |
|---|---|
| key | ROW{userId:STRING, bank:STRING} |
| values | ITERABLE[ROW[Purchase]] |
key 字段包含分组键,values 字段包含与该键匹配的所有值的列表。
可以使用 withKeyField 和 withValueField 构建器来控制输出模式中 key 和 values 字段的名称,如下所示
purchases.apply(Group.byFieldNames("userId", "shippingAddress.streetAddress")
.withKeyField("userAndStreet")
.withValueField("matchingPurchases"));在分组结果上应用一个或多个聚合非常常见。每个聚合都可以指定一个或多个要聚合的字段、一个聚合函数以及输出模式中结果字段的名称。例如,以下应用程序计算按 userId 分组的三个聚合,所有聚合都以单个输出模式表示
purchases.apply(Group.byFieldNames("userId")
.aggregateField("itemId", Count.combineFn(), "numPurchases")
.aggregateField("costCents", Sum.ofLongs(), "totalSpendCents")
.aggregateField("costCents", Top.<Long>largestLongsFn(10), "topPurchases"));input_pc = ... # {"user_id": ..., "item_Id": ..., "cost_cents": ...}
output_pc = input_pc | beam.GroupBy("user_id")
.aggregate_field("item_id", CountCombineFn, "num_purchases")
.aggregate_field("cost_cents", sum, "total_spendcents")
.aggregate_field("cost_cents", TopCombineFn, "top_purchases")Go SDK 尚未开发出对模式感知分组的支持。
此聚合的结果将具有以下模式
| 字段名称 | 字段类型 |
|---|---|
| key | ROW{userId:STRING} |
| value | ROW{numPurchases: INT64, totalSpendCents: INT64, topPurchases: ARRAY[INT64]} |
通常使用 Selected.flattenedSchema 将结果展平为非嵌套的扁平模式。
联接
Beam 支持模式 PCollections 上的等值联接,即联接条件取决于字段子集相等的联接。例如,以下示例使用 Purchases 模式将交易与可能与该交易关联的评论进行联接(用户和产品都与交易中的用户和产品匹配)。这是一个“自然联接”,其中在联接的左右两侧使用相同的字段名,并使用 using 关键字指定
Python SDK 尚未开发出对联接的支持。
Go SDK 尚未开发出对联接的支持。
PCollection<Transaction> transactions = readTransactions();
PCollection<Review> reviews = readReviews();
PCollection<Row> joined = transactions.apply(
Join.innerJoin(reviews).using("userId", "productId"));生成的模式如下
| 字段名称 | 字段类型 |
|---|---|
| lhs | ROW{Transaction} |
| rhs | ROW{Review} |
每个结果行包含一个 Transaction 和一个与联接条件匹配的 Review。
如果要匹配的两个模式中的字段具有不同的名称,则可以使用 on 函数。例如,如果 Review 模式将这些字段命名为与 Transaction 模式不同的名称,则可以编写以下内容
Python SDK 尚未开发出对联接的支持。
Go SDK 尚未开发出对联接的支持。
PCollection<Row> joined = transactions.apply(
Join.innerJoin(reviews).on(
FieldsEqual
.left("userId", "productId")
.right("reviewUserId", "reviewProductId")));除了内部联接之外,Join 变换还支持完全外部联接、左外部联接和右外部联接。
复杂联接
虽然大多数联接往往是二元联接(将两个输入联接在一起),但有时您会有两个以上的输入流,它们都需要在公共键上进行联接。CoGroup 变换允许根据模式字段相等来将多个 PCollections 联接在一起。每个 PCollection 都可以在最终联接记录中标记为必需或可选,为外联接提供泛化,以用于具有两个以上输入 PCollection 的联接。输出可以选择展开,提供单独的联接记录,如 Join 变换中一样。输出也可以以未展开的格式进行处理,提供联接键以及与该键匹配的每个输入的所有记录的迭代器。
Python SDK 尚未开发出对联接的支持。
Go SDK 尚未开发出对联接的支持。
筛选事件
Filter 变换可以配置为使用一组谓词,每个谓词都基于指定的字段。只有所有谓词都返回 true 的记录才能通过筛选器。例如以下内容
purchases.apply(Filter.create()
.whereFieldName("costCents", c -> c > 100 * 20)
.whereFieldName("shippingAddress.country", c -> c.equals("de"));将生成所有从德国购买且购买价格超过 20 美分的商品。
向模式添加字段
AddFields 变换可用于使用新字段扩展模式。输入行将通过为新字段插入空值来扩展到新的模式,尽管可以指定备用默认值;如果使用默认空值,则新字段类型将标记为可空。可以使用字段选择语法添加嵌套子字段,包括数组或映射值内的嵌套字段。
例如,以下应用程序
purchases.apply(AddFields.<PurchasePojo>create()
.field("timeOfDaySeconds", FieldType.INT32)
.field("shippingAddress.deliveryNotes", FieldType.STRING)
.field("transactions.isFlagged", FieldType.BOOLEAN, false));生成一个具有扩展模式的 PCollection。所有输入行和字段,但还添加了指定的字段。所有结果行都将在 timeOfDaySeconds 和 shippingAddress.deliveryNotes 字段中填充空值,并在 transactions.isFlagged 字段中填充 false 值。
从模式中删除字段
DropFields 允许从模式中删除特定字段。输入行的模式将被截断,并且将从输出中删除删除的字段的任何值。也可以使用字段选择语法删除嵌套字段。
例如,以下代码段
purchases.apply(DropFields.fields("userId", "shippingAddress.streetAddress"));生成输入的副本,其中删除了这两个字段及其相应的
重命名模式字段
RenameFields 允许重命名模式中的特定字段。输入行中的字段值保持不变,只有模式被修改。此变换通常用于准备要输出到模式感知接收器(例如 RDBMS)的记录,以确保 PCollection 模式字段名称与输出的名称匹配。它还可以用于重命名由其他变换生成的字段以使其更易于使用(类似于 SQL 中的 SELECT AS)。也可以使用字段选择语法重命名嵌套字段。
例如,以下代码段
purchases.apply(RenameFields.<PurchasePojo>create()
.rename("userId", "userIdentifier")
.rename("shippingAddress.streetAddress", "shippingAddress.street"));生成相同的一组未修改的输入元素,但是 PCollection 上的模式已更改为将 userId 重命名为 userIdentifier,并将 shippingAddress.streetAddress 重命名为 shippingAddress.street。
类型转换
如前所述,只要这些类型具有等效的模式,Beam 就可以自动在不同的 Java 类型之间进行转换。一种方法是使用 Convert 变换,如下所示。
PCollection<PurchaseBean> purchaseBeans = readPurchasesAsBeans();
PCollection<PurchasePojo> pojoPurchases =
purchaseBeans.apply(Convert.to(PurchasePojo.class));Beam 将验证 PurchasePojo 的推断模式是否与输入 PCollection 的模式匹配,然后将强制转换为 PCollection<PurchasePojo>。
由于 Row 类可以支持任何模式,因此任何具有模式的 PCollection 都可以强制转换为 PCollection 行,如下所示。
PCollection<Row> purchaseRows = purchaseBeans.apply(Convert.toRows());如果源类型是单字段模式,则 Convert 还会根据要求转换为字段的类型,有效地解开行。例如,给定一个具有单个 INT64 字段的模式,以下将将其转换为 PCollection<Long>
PCollection<Long> longs = rows.apply(Convert.to(TypeDescriptors.longs()));在所有情况下,类型检查都在管道图构建时完成,如果类型与模式不匹配,则管道将无法启动。
6.6.3. 模式在 ParDo 中
具有模式的 PCollection 可以应用 ParDo,就像任何其他 PCollection 一样。但是,Beam 运行程序在应用 ParDo 时会意识到模式,这将启用其他功能。
输入转换
Beam 目前不支持 Go 中的输入转换。
由于 Beam 了解源 PCollection 的模式,因此它可以自动将元素转换为任何已知匹配模式的 Java 类型。例如,使用上面提到的 Transaction 模式,假设我们有以下 PCollection
PCollection<PurchasePojo> purchases = readPurchases();如果没有模式,则应用的 DoFn 必须接受类型为 TransactionPojo 的元素。但是,由于存在模式,因此可以应用以下 DoFn
purchases.apply(ParDo.of(new DoFn<PurchasePojo, PurchasePojo>() {
@ProcessElement public void process(@Element PurchaseBean purchase) {
...
}
}));即使 @Element 参数与 PCollection 的 Java 类型不匹配,由于它具有匹配的模式,Beam 将自动转换元素。如果模式不匹配,Beam 将在图构建时检测到这一点,并使用类型错误使作业失败。
由于每个模式都可以用 Row 类型表示,因此 Row 也可以在这里使用
purchases.appy(ParDo.of(new DoFn<PurchasePojo, PurchasePojo>() {
@ProcessElement public void process(@Element Row purchase) {
...
}
}));输入选择
由于输入具有模式,因此您还可以自动选择特定字段在 DoFn 中进行处理。
给定上述 purchases PCollection,假设您只想处理 userId 和 itemId 字段。可以使用上面描述的选择表达式来完成这些操作,如下所示
purchases.appy(ParDo.of(new DoFn<PurchasePojo, PurchasePojo>() {
@ProcessElement public void process(
@FieldAccess("userId") String userId, @FieldAccess("itemId") long itemId) {
...
}
}));您也可以选择嵌套字段,如下所示。
purchases.appy(ParDo.of(new DoFn<PurchasePojo, PurchasePojo>() {
@ProcessElement public void process(
@FieldAccess("shippingAddress.street") String street) {
...
}
}));有关更多信息,请参阅有关字段选择表达式的部分。在选择子模式时,Beam 将自动转换为任何匹配的模式类型,就像读取整个行一样。
7. 数据编码和类型安全
当 Beam 运行程序执行管道时,它们通常需要在 PCollection 中物化中间数据,这需要将元素转换为字节字符串并从字节字符串转换。Beam SDK 使用名为 Coder 的对象来描述如何对给定 PCollection 的元素进行编码和解码。
请注意,编码器与在与外部数据源或接收器交互时解析或格式化数据无关。此类解析或格式化通常应使用
ParDo或MapElements等变换显式完成。
在用于 Java 的 Beam SDK 中,类型 Coder 提供了对数据进行编码和解码所需的方法。用于 Java 的 SDK 提供了许多 Coder 子类,这些子类可与各种标准 Java 类型一起使用,例如 Integer、Long、Double、StringUtf8 等等。您可以在 Coder 包 中找到所有可用的 Coder 子类。
在用于 Python 的 Beam SDK 中,类型 Coder 提供了对数据进行编码和解码所需的方法。用于 Python 的 SDK 提供了许多 Coder 子类,这些子类可与各种标准 Python 类型一起使用,例如基本类型、Tuple、Iterable、StringUtf8 等等。您可以在 apache_beam.coders 包中找到所有可用的 Coder 子类。
标准 Go 类型(如 int、int64 float64、[]byte 和 string 等等)使用内置编码器进行编码。结构体和指向结构体的指针默认使用 Beam Schema Row 编码。但是,用户可以使用 beam.RegisterCoder 构建和注册自定义编码器。您可以在 coder 包中找到可用的 Coder 函数。
标准 Typescript 类型(如 number、UInt8Array 和 string 等等)使用内置编码器进行编码。Json 对象和数组通过 BSON 编码进行编码。对于这些类型,除非与跨语言变换交互,否则无需指定编码器。用户可以通过扩展 beam.coders.Coder 来构建自定义编码器,以便与 withCoderInternal 一起使用,但通常情况下更倾向于使用逻辑类型。
请注意,编码器不一定与类型具有 1:1 的关系。例如,Integer 类型可以具有多个有效的编码器,并且输入和输出数据可以使用不同的 Integer 编码器。变换可能具有使用 BigEndianIntegerCoder 的 Integer 类型输入数据,以及具有使用 VarIntCoder 的 Integer 类型输出数据。
7.1. 指定编码器
Beam SDK 需要为管道中的每个 PCollection 指定一个编码器。在大多数情况下,Beam SDK 可以根据 PCollection 的元素类型或生成它的转换自动推断 Coder,但是,在某些情况下,管道作者需要显式指定 Coder,或者为自定义类型开发 Coder。
可以使用 PCollection.setCoder 方法为现有 PCollection 显式设置编码器。请注意,不能对已完成的 PCollection(例如,通过对其调用 .apply)调用 setCoder。
可以使用 getCoder 方法获取现有 PCollection 的编码器。如果未设置编码器并且无法为给定 PCollection 推断编码器,则此方法将引发 IllegalStateException 错误。
Beam SDK 在尝试自动推断 PCollection 的 Coder 时使用多种机制。
每个管道对象都有一个 CoderRegistry。CoderRegistry 表示 Java 类型与管道应为每种类型的 PCollection 使用的默认编码器之间的映射关系。
用于 Python 的 Beam SDK 具有 CoderRegistry,它表示 Python 类型与应为每种类型的 PCollection 使用的默认编码器之间的映射关系。
用于 Go 的 Beam SDK 允许用户使用 beam.RegisterCoder 注册默认编码器实现。
默认情况下,用于 Java 的 Beam SDK 会使用转换函数对象(例如 DoFn)中的类型参数来自动推断由 PTransform 生成的 PCollection 元素的 Coder。例如,在 ParDo 的情况下,DoFn<Integer, String> 函数对象接受类型为 Integer 的输入元素,并生成类型为 String 的输出元素。在这种情况下,用于 Java 的 SDK 将自动推断输出 PCollection<String> 的默认 Coder(在默认管道 CoderRegistry 中,这是 StringUtf8Coder)。
默认情况下,用于 Python 的 Beam SDK 会使用转换函数对象(例如 DoFn)中的类型提示来自动推断输出 PCollection 元素的 Coder。例如,在 ParDo 的情况下,DoFn 具有类型提示 @beam.typehints.with_input_types(int) 和 @beam.typehints.with_output_types(str),接受类型为 int 的输入元素,并生成类型为 str 的输出元素。在这种情况下,用于 Python 的 Beam SDK 将自动推断输出 PCollection 的默认 Coder(在默认管道 CoderRegistry 中,这是 BytesCoder)。
默认情况下,用于 Go 的 Beam SDK 会根据转换函数对象(例如 DoFn)的输出来自动推断输出 PCollection 元素的 Coder。例如,在 ParDo 的情况下,DoFn 的参数为 v int, emit func(string),接受类型为 int 的输入元素,并生成类型为 string 的输出元素。在这种情况下,用于 Go 的 Beam SDK 将自动推断输出 PCollection 的默认 Coder 为 string_utf8 编码器。
注意:如果使用
Create转换从内存中数据创建PCollection,则不能依赖编码器推断和默认编码器。Create无法访问其参数的任何类型信息,如果参数列表包含一个运行时类没有注册默认编码器的值,则可能无法推断编码器。
使用 Create 时,确保使用正确编码器的最简单方法是在应用 Create 转换时调用 withCoder。
7.2. 默认编码器和 CoderRegistry
每个 Pipeline 对象都有一个 CoderRegistry 对象,它将语言类型映射到管道应为这些类型使用的默认编码器。可以使用 CoderRegistry 自行查找给定类型的默认编码器,或者为给定类型注册新的默认编码器。
CoderRegistry 包含一个默认的编码器到标准 JavaPython 类型的映射,用于使用用于 JavaPython 的 Beam SDK 创建的任何管道。下表显示了标准映射
| Java 类型 | 默认编码器 |
|---|---|
| Double | DoubleCoder |
| Instant | InstantCoder |
| Integer | VarIntCoder |
| Iterable | IterableCoder |
| KV | KvCoder |
| List | ListCoder |
| Map | MapCoder |
| Long | VarLongCoder |
| String | StringUtf8Coder |
| TableRow | TableRowJsonCoder |
| Void | VoidCoder |
| byte[ ] | ByteArrayCoder |
| TimestampedValue | TimestampedValueCoder |
| Python 类型 | 默认编码器 |
|---|---|
| int | VarIntCoder |
| float | FloatCoder |
| str | BytesCoder |
| bytes | StrUtf8Coder |
| Tuple | TupleCoder |
7.2.1. 查找默认编码器
可以使用 CoderRegistry.getCoder 方法确定 Java 类型的默认编码器。可以使用 Pipeline.getCoderRegistry 方法访问给定管道的 CoderRegistry。这允许你确定(或设置)每个管道的基础上 Java 类型的默认编码器:即“对于此管道,验证 Integer 值是否使用 BigEndianIntegerCoder 编码。”
可以使用 CoderRegistry.get_coder 方法确定 Python 类型的默认编码器。可以使用 coders.registry 访问 CoderRegistry。这允许你确定(或设置)Python 类型的默认编码器。
可以使用 beam.NewCoder 函数确定 Go 类型的默认编码器。
7.2.2. 设置类型的默认编码器
要为特定管道的 JavaPython 类型设置默认编码器,请获取并修改管道的 CoderRegistry。使用 Pipeline.getCoderRegistry coders.registry 方法获取 CoderRegistry 对象,然后使用 CoderRegistry.registerCoder CoderRegistry.register_coder 方法为目标类型注册新的 Coder。
要为 Go 类型设置默认编码器,请使用 beam.RegisterCoder 函数为目标类型注册编码器和解码器函数。但是,内置类型(如 int、string、float64 等)无法覆盖其编码器。
以下示例代码演示如何为管道的 Integerint 值设置默认编码器(在本例中为 BigEndianIntegerCoder)。
以下示例代码演示如何为 MyCustomType 元素设置自定义编码器。
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options);
CoderRegistry cr = p.getCoderRegistry();
cr.registerCoder(Integer.class, BigEndianIntegerCoder.class);apache_beam.coders.registry.register_coder(int, BigEndianIntegerCoder)type MyCustomType struct{
...
}
// See documentation on beam.RegisterCoder for other supported coder forms.
func encode(MyCustomType) []byte { ... }
func decode(b []byte) MyCustomType { ... }
func init() {
beam.RegisterCoder(reflect.TypeOf((*MyCustomType)(nil)).Elem(), encode, decode)
}7.2.3. 使用默认编码器注释自定义数据类型
如果管道程序定义了自定义数据类型,可以使用 @DefaultCoder 注解指定要与该类型一起使用的编码器。默认情况下,Beam 将使用 SerializableCoder,它使用 Java 序列化,但它有一些缺点
编码大小和速度效率低下。请参阅 Java 序列化方法的比较。
它是非确定性的:它可能对两个等效对象产生不同的二进制编码。
对于键值对,基于键的操作(GroupByKey、Combine)和每个键的状态的正确性取决于为键使用确定性编码器
可以使用 @DefaultCoder 注解设置新的默认值,如下所示
@DefaultCoder(AvroCoder.class)
public class MyCustomDataType {
...
}如果已创建与数据类型匹配的自定义编码器,并且想要使用 @DefaultCoder 注解,则编码器类必须实现静态 Coder.of(Class<T>) 工厂方法。
public class MyCustomCoder implements Coder {
public static Coder<T> of(Class<T> clazz) {...}
...
}
@DefaultCoder(MyCustomCoder.class)
public class MyCustomDataType {
...
}用于 PythonGo 的 Beam SDK 不支持使用默认编码器对数据类型进行注释。如果想要设置默认编码器,请使用上一节中描述的方法,为类型设置默认编码器。
8. 窗口
窗口化根据 PCollection 中各个元素的时间戳对其进行细分。聚合多个元素的转换(例如 GroupByKey 和 Combine)在每个窗口的基础上隐式工作 - 它们将每个 PCollection 处理为多个有限窗口的连续,尽管整个集合本身可能具有无限的大小。
一个相关的概念,称为 **触发器**,决定何时在收到无界数据时发出聚合的结果。可以使用触发器来细化 PCollection 的窗口化策略。触发器允许你处理迟到的数据或提供早期结果。有关更多信息,请参阅 触发器 部分。
8.1. 窗口基础
一些 Beam 转换,例如 GroupByKey 和 Combine,按公共键对多个元素进行分组。通常,分组操作将整个数据集中具有相同键的所有元素进行分组。对于无界数据集,不可能收集所有元素,因为新元素会不断添加,并且可能无限多个(例如,流数据)。如果你正在处理无界 PCollection,窗口化特别有用。
在 Beam 模型中,任何 PCollection(包括无界 PCollection)都可以细分为逻辑窗口。PCollection 中的每个元素根据 PCollection 的窗口化函数分配到一个或多个窗口,并且每个单独的窗口包含有限数量的元素。然后,分组转换在每个窗口的基础上考虑每个 PCollection 的元素。例如,GroupByKey 隐式地按键和窗口对 PCollection 的元素进行分组。
注意:Beam 的默认窗口化行为是将 PCollection 的所有元素分配到一个全局窗口,并丢弃迟到的数据,即使对于无界 PCollection 也是如此。在对无界 PCollection 使用分组转换(例如 GroupByKey)之前,必须至少执行以下操作之一
- 设置非全局窗口化函数。请参阅 设置 PCollection 的窗口化函数。
- 设置非默认 触发器。这允许全局窗口在其他条件下发出结果,因为默认窗口化行为(等待所有数据到达)永远不会发生。
如果你没有为无界 PCollection 设置非全局窗口化函数或非默认触发器,并且随后使用分组转换(例如 GroupByKey 或 Combine),则你的管道将在构造时生成错误,并且你的作业将失败。
8.1.1. 窗口约束
在为 PCollection 设置窗口化函数之后,下次对该 PCollection 应用分组转换时,将使用元素的窗口。窗口分组按需发生。如果使用 Window 转换设置窗口化函数,则每个元素都将分配到一个窗口,但直到 GroupByKey 或 Combine 在窗口和键上进行聚合之前,才考虑这些窗口。这会对你的管道产生不同的影响。请考虑下图中的示例管道

图 3:应用窗口化的管道
在上面的管道中,我们使用KafkaIO读取一组键值对,创建一个无界的PCollection,然后使用Window转换对该集合应用一个窗口函数。然后,我们对集合应用ParDo,然后使用GroupByKey对ParDo的结果进行分组。窗口函数对ParDo转换没有影响,因为窗口只有在GroupByKey需要时才会真正使用。但是,后续的转换应用于GroupByKey的结果 - 数据按键和窗口分组。
8.1.2. 使用有界 PCollections 进行窗口化
您可以将窗口与**有界**的PCollection中的固定大小数据集一起使用。但是,请注意,窗口仅考虑附加到PCollection每个元素的隐式时间戳,并且创建固定数据集的数据源(例如TextIO)会为每个元素分配相同的时间戳。这意味着默认情况下,所有元素都属于单个全局窗口。
要将窗口与固定数据集一起使用,您可以为每个元素分配自己的时间戳。要为元素分配时间戳,请使用带有DoFn的ParDo转换,该转换输出带有新时间戳的每个元素(例如,Beam SDK for Java 中的WithTimestamps转换)。
为了说明使用有界PCollection的窗口如何影响管道处理数据的方式,请考虑以下管道

图 4:GroupByKey和ParDo没有窗口,在一个有界集合上。
在上面的管道中,我们通过使用TextIO从文件中读取行来创建一个有界的PCollection。然后,我们使用GroupByKey对集合进行分组,并将ParDo转换应用于分组后的PCollection。在本例中,GroupByKey创建了一个唯一键的集合,然后ParDo对每个键只应用一次。
请注意,即使您没有设置窗口函数,仍然存在一个窗口 - PCollection中的所有元素都被分配到一个全局窗口。
现在,考虑相同的管道,但使用窗口函数

图 5:GroupByKey和ParDo有窗口,在一个有界集合上。
和以前一样,管道通过从文件中读取行来创建一个有界的PCollection。然后,我们为该PCollection设置了一个窗口函数。GroupByKey转换根据窗口函数按键和窗口对PCollection的元素进行分组。后续的ParDo转换对每个键应用多次,每个窗口应用一次。
8.2. 提供的窗口函数
您可以定义不同类型的窗口来划分PCollection的元素。Beam 提供了几种窗口函数,包括
- 固定时间窗口
- 滑动时间窗口
- 每会话窗口
- 单一全局窗口
- 基于日历的窗口(Beam SDK for Python 或 Go 不支持)
如果您有更复杂的需求,您也可以定义自己的WindowFn。
请注意,每个元素在逻辑上可以属于多个窗口,具体取决于您使用的窗口函数。例如,滑动时间窗口可以创建重叠窗口,其中单个元素可以分配到多个窗口。但是,PCollection中的每个元素只能在一个窗口中,因此如果一个元素被分配到多个窗口,则该元素在概念上被复制到每个窗口中,并且每个元素除了窗口之外都是相同的。
8.2.1. 固定时间窗口
最简单的窗口形式是使用固定时间窗口:给定一个带时间戳的PCollection,它可能在不断更新,每个窗口都可能捕获(例如)所有时间戳落在 30 秒间隔内的元素。
固定时间窗口代表数据流中一个一致的持续时间、不重叠的时间间隔。考虑持续时间为 30 秒的窗口:无界PCollection中所有时间戳值为 0:00:00 到(不包括)0:00:30 的元素都属于第一个窗口,时间戳值为 0:00:30 到(不包括)0:01:00 的元素都属于第二个窗口,依此类推。
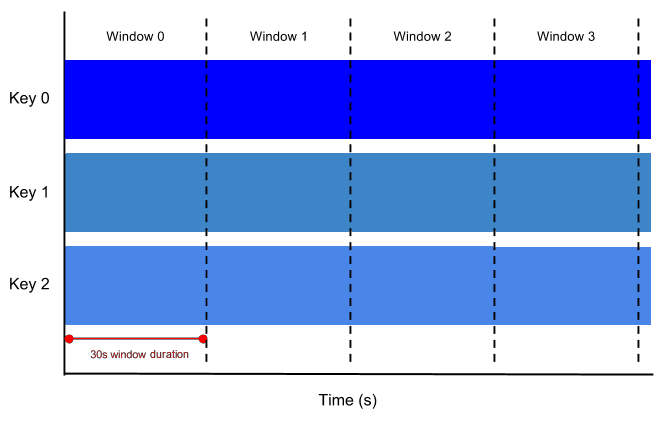
图 6:固定时间窗口,持续时间为 30 秒。
8.2.2. 滑动时间窗口
滑动时间窗口也代表数据流中的时间间隔;但是,滑动时间窗口可以重叠。例如,每个窗口可能捕获 60 秒的数据,但每 30 秒开始一个新窗口。滑动窗口开始的频率称为周期。因此,我们的示例将具有 60 秒的窗口持续时间和 30 秒的周期。
由于多个窗口重叠,数据集中的大多数元素将属于多个窗口。这种窗口对于对数据进行运行平均非常有用;使用滑动时间窗口,您可以计算过去 60 秒数据的运行平均值,在我们的示例中每 30 秒更新一次。
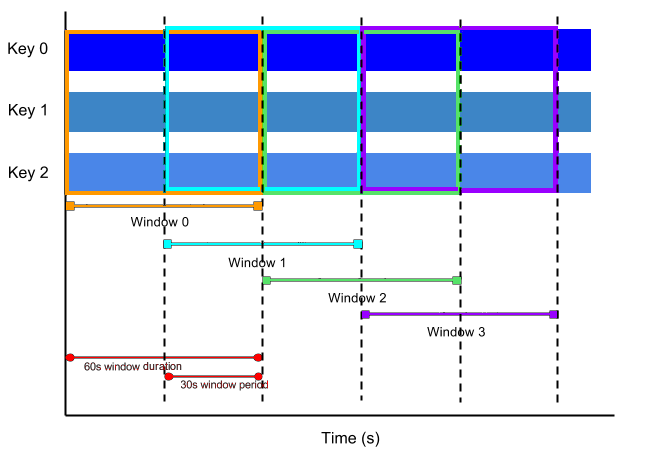
图 7:滑动时间窗口,窗口持续时间为 1 分钟,窗口周期为 30 秒。
8.2.3. 会话窗口
会话窗口函数定义包含在一定间隙持续时间内彼此相邻的元素的窗口。会话窗口在每个键的基础上应用,对于时间分布不规则的数据非常有用。例如,表示用户鼠标活动的數據流可能包含长期的空闲时间,这些空闲时间与大量的点击交织在一起。如果数据在规定的最小间隙持续时间之后到达,这将启动新窗口的开始。
图 8:会话窗口,具有最小间隙持续时间。注意每个数据键如何根据其数据分布具有不同的窗口。
8.2.4. 单个全局窗口
默认情况下,PCollection 中的所有数据都被分配到单个全局窗口,而延迟数据会被丢弃。如果您的数据集大小固定,您可以对PCollection使用全局窗口默认值。
如果您正在处理无界数据集(例如来自流数据源),则可以使用单个全局窗口,但在应用GroupByKey和Combine之类的聚合转换时要谨慎。具有默认触发器的单个全局窗口通常需要整个数据集可用才能进行处理,这对于不断更新的数据是不可能的。要对使用全局窗口的无界PCollection执行聚合,您应该为该PCollection指定一个非默认触发器。
8.3. 设置 PCollection 的窗口函数
您可以通过应用Window转换来设置PCollection的窗口函数。当您应用Window转换时,您必须提供一个WindowFn。WindowFn决定PCollection将用于后续分组转换(例如固定时间窗口或滑动时间窗口)的窗口函数。
当您设置窗口函数时,您可能还希望为PCollection设置一个触发器。触发器决定每个单独的窗口何时被聚合并发出,并帮助细化窗口函数在处理延迟数据和计算早期结果方面的执行方式。有关更多信息,请参阅触发器部分。
在 Beam YAML 中,窗口规范也可以直接放置在任何转换上,而不必要求显式WindowInto转换。
8.3.1. 固定时间窗口
以下示例代码显示了如何应用Window将PCollection划分为固定窗口,每个窗口长 60 秒
PCollection<String> items = ...;
PCollection<String> fixedWindowedItems = items.apply(
Window.<String>into(FixedWindows.of(Duration.standardSeconds(60))));from apache_beam import window
fixed_windowed_items = (
items | 'window' >> beam.WindowInto(window.FixedWindows(60)))fixedWindowedItems := beam.WindowInto(s,
window.NewFixedWindows(60*time.Second),
items)pcoll
.apply(beam.windowInto(windowings.fixedWindows(60)))type: WindowInto
windowing:
type: fixed
size: 60s8.3.2. 滑动时间窗口
以下示例代码显示了如何应用Window将PCollection划分为滑动时间窗口。每个窗口长 30 秒,每五秒开始一个新窗口
PCollection<String> items = ...;
PCollection<String> slidingWindowedItems = items.apply(
Window.<String>into(SlidingWindows.of(Duration.standardSeconds(30)).every(Duration.standardSeconds(5))));from apache_beam import window
sliding_windowed_items = (
items | 'window' >> beam.WindowInto(window.SlidingWindows(30, 5)))slidingWindowedItems := beam.WindowInto(s,
window.NewSlidingWindows(5*time.Second, 30*time.Second),
items)pcoll
.apply(beam.windowInto(windowings.slidingWindows(30, 5)))type: WindowInto
windowing:
type: sliding
size: 5m
period: 30s8.3.3. 会话窗口
以下示例代码显示了如何应用Window将PCollection划分为会话窗口,其中每个会话必须至少间隔 10 分钟(600 秒)的时间间隔。
PCollection<String> items = ...;
PCollection<String> sessionWindowedItems = items.apply(
Window.<String>into(Sessions.withGapDuration(Duration.standardSeconds(600))));from apache_beam import window
session_windowed_items = (
items | 'window' >> beam.WindowInto(window.Sessions(10 * 60)))sessionWindowedItems := beam.WindowInto(s,
window.NewSessions(600*time.Second),
items)pcoll
.apply(beam.windowInto(windowings.sessions(10 * 60)))type: WindowInto
windowing:
type: sessions
gap: 60s请注意,会话是按键的 - 集合中的每个键将根据数据分布具有自己的会话分组。
8.3.4. 单个全局窗口
如果您的PCollection是有界的(大小固定),您可以将所有元素分配到单个全局窗口。以下示例代码显示了如何为PCollection设置单个全局窗口
PCollection<String> items = ...;
PCollection<String> batchItems = items.apply(
Window.<String>into(new GlobalWindows()));from apache_beam import window
global_windowed_items = (
items | 'window' >> beam.WindowInto(window.GlobalWindows()))globalWindowedItems := beam.WindowInto(s,
window.NewGlobalWindows(),
items)pcoll
.apply(beam.windowInto(windowings.globalWindows()))type: WindowInto
windowing:
type: global8.4. 水印和延迟数据
在任何数据处理系统中,数据事件发生的时间(“事件时间”,由数据元素本身的时间戳决定)与数据元素在管道中任何阶段实际被处理的时间(“处理时间”,由处理元素的系统的时钟决定)之间存在一定程度的延迟。此外,无法保证数据事件会按照它们生成的顺序出现在管道中。
例如,假设我们有一个使用固定时间窗口的PCollection,窗口长五分钟。对于每个窗口,Beam 必须收集所有事件时间时间戳在给定窗口范围内的數據(例如,在第一个窗口中,时间戳在 0:00 到 4:59 之间)。时间戳在该范围之外的数据(来自 5:00 或更晚的数据)属于另一个窗口。
但是,数据并不总是保证按时间顺序到达管道,或者总是以可预测的间隔到达。Beam 跟踪一个水印,它表示系统对何时所有数据可以预期到达管道的某个窗口的认识。一旦水印超过窗口的结束,任何到达该窗口的时间戳的元素都被认为是延迟数据。
从我们的示例中,假设我们有一个简单的水印,它假设数据时间戳(事件时间)与数据出现在管道中的时间(处理时间)之间大约有 30 秒的延迟,那么 Beam 将在 5:30 关闭第一个窗口。如果一条数据记录在 5:34 到达,但时间戳将其放在 0:00-4:59 窗口内(例如,3:38),那么该记录就是延迟数据。
注意:为了简单起见,我们假设我们正在使用一个非常简单的水印来估计延迟时间。在实践中,PCollection的数据源决定水印,水印可以更精确或更复杂。
Beam 的默认窗口配置尝试确定何时所有数据都已到达(基于数据源类型),然后将水印推进到窗口的结束。此默认配置不允许延迟数据。触发器允许您修改和细化PCollection的窗口策略。您可以使用触发器来决定每个单独的窗口何时聚合并报告其结果,包括窗口如何发出延迟元素。
8.4.1. 管理延迟数据
您可以通过在设置PCollection的窗口策略时调用.withAllowedLateness操作来允许延迟数据。以下代码示例演示了一个窗口策略,它将允许延迟数据在窗口结束后的两天内到达。
PCollection<String> items = ...;
PCollection<String> fixedWindowedItems = items.apply(
Window.<String>into(FixedWindows.of(Duration.standardMinutes(1)))
.withAllowedLateness(Duration.standardDays(2))); pc = [Initial PCollection]
pc | beam.WindowInto(
FixedWindows(60),
trigger=trigger_fn,
accumulation_mode=accumulation_mode,
timestamp_combiner=timestamp_combiner,
allowed_lateness=Duration(seconds=2*24*60*60)) # 2 dayswindowedItems := beam.WindowInto(s,
window.NewFixedWindows(1*time.Minute), items,
beam.AllowedLateness(2*24*time.Hour), // 2 days
)当您在PCollection上设置.withAllowedLateness时,允许的延迟会传播到您应用允许延迟的第一个PCollection派生的任何后续PCollection。如果您想在管道中稍后更改允许的延迟,您必须通过应用Window.configure().withAllowedLateness()来明确执行此操作。
8.5. 向 PCollection 的元素添加时间戳
无界数据源为每个元素提供时间戳。根据您的无界数据源,您可能需要配置如何从原始数据流中提取时间戳。
然而,有界数据源(例如来自 TextIO 的文件)不提供时间戳。如果您需要时间戳,则必须将其添加到您的 PCollection 的元素中。
您可以通过应用一个 ParDo 变换来为 PCollection 的元素分配新的时间戳,该变换输出带有您设置的时间戳的新元素。
例如,如果您的管道从输入文件中读取日志记录,并且每个日志记录都包含时间戳字段;由于您的管道从文件中读取记录,因此文件源不会自动分配时间戳。您可以从每个记录中解析时间戳字段,并使用带有 DoFn 的 ParDo 变换将时间戳附加到 PCollection 中的每个元素。
PCollection<LogEntry> unstampedLogs = ...;
PCollection<LogEntry> stampedLogs =
unstampedLogs.apply(ParDo.of(new DoFn<LogEntry, LogEntry>() {
public void processElement(@Element LogEntry element, OutputReceiver<LogEntry> out) {
// Extract the timestamp from log entry we're currently processing.
Instant logTimeStamp = extractTimeStampFromLogEntry(element);
// Use OutputReceiver.outputWithTimestamp (rather than
// OutputReceiver.output) to emit the entry with timestamp attached.
out.outputWithTimestamp(element, logTimeStamp);
}
}));class AddTimestampDoFn(beam.DoFn):
def process(self, element):
# Extract the numeric Unix seconds-since-epoch timestamp to be
# associated with the current log entry.
unix_timestamp = extract_timestamp_from_log_entry(element)
# Wrap and emit the current entry and new timestamp in a
# TimestampedValue.
yield beam.window.TimestampedValue(element, unix_timestamp)
timestamped_items = items | 'timestamp' >> beam.ParDo(AddTimestampDoFn())// AddTimestampDoFn extracts an event time from a LogEntry.
func AddTimestampDoFn(element LogEntry, emit func(beam.EventTime, LogEntry)) {
et := extractEventTime(element)
// Defining an emitter with beam.EventTime as the first parameter
// allows the DoFn to set the event time for the emitted element.
emit(mtime.FromTime(et), element)
}
// Use the DoFn with ParDo as normal.
stampedLogs := beam.ParDo(s, AddTimestampDoFn, unstampedLogs)type: AssignTimestamps
config:
language: python
timestamp:
callable: |
import datetime
def extract_timestamp(x):
raw = datetime.datetime.strptime(
x.external_timestamp_field, "%Y-%m-%d")
return raw.astimezone(datetime.timezone.utc) 9. 触发器
注意:Beam SDK for Go 中的触发器 API 目前处于实验阶段,可能会发生变化。
在将数据收集并分组到窗口时,Beam 使用触发器来确定何时发出每个窗口的聚合结果(称为窗格)。如果您使用 Beam 的默认窗口配置和 默认触发器,Beam 会在估计所有数据都已到达时输出聚合结果,并丢弃该窗口的所有后续数据。
您可以为 PCollection 设置触发器以更改此默认行为。Beam 提供了许多可以设置的预构建触发器
- 事件时间触发器。这些触发器根据每个数据元素上的时间戳指示的事件时间运行。Beam 的默认触发器是基于事件时间的。
- 处理时间触发器。这些触发器根据处理时间运行——数据元素在管道中任何给定阶段被处理的时间。
- 数据驱动触发器。这些触发器通过检查到达每个窗口的数据运行,并在该数据满足特定属性时触发。目前,数据驱动触发器仅支持在特定数量的数据元素之后触发。
- 复合触发器。这些触发器以各种方式组合多个触发器。
从高层次上讲,与仅在窗口结束时输出相比,触发器提供了两个额外的功能
- 触发器允许 Beam 在给定窗口中的所有数据到达之前发出早期结果。例如,在经过一定时间后发出,或在到达一定数量的元素后发出。
- 触发器允许通过在事件时间水印经过窗口结束时间后触发来处理延迟数据。
这些功能使您可以控制数据的流向,并在不同的因素之间取得平衡,具体取决于您的用例
- 完整性:在计算结果之前,拥有所有数据有多重要?
- 延迟:您希望等待数据多久?例如,您是否要等到您认为所有数据都已到达?您是否会在数据到达时对其进行处理?
- 成本:您愿意花多少计算能力/金钱来降低延迟?
例如,需要实时更新的系统可能使用严格的时间触发器,每 N 秒发出一个窗口,重视速度而不是数据完整性。一个比结果的精确时间更重视数据完整性的系统可能会选择使用 Beam 的默认触发器,该触发器在窗口结束时触发。
您还可以为使用 单一全局窗口作为其窗口函数 的无界 PCollection 设置触发器。当您希望管道对无界数据集提供定期更新时,这可能很有用——例如,对提供给当前时间的所有数据的运行平均值进行更新,每 N 秒或每 N 个元素更新一次。
9.1. 事件时间触发器
AfterWatermark 触发器基于事件时间运行。AfterWatermark 触发器在 水印 经过窗口结束时间后发出窗口内容,基于附加到数据元素上的时间戳。水印是全局进度指标,是 Beam 在任何给定时间点内对管道中输入完整性的概念。 AfterWatermark.pastEndOfWindow() AfterWatermark trigger.AfterEndOfWindow 仅在水印经过窗口结束时间时触发。
此外,您可以配置在管道在窗口结束时间之前或之后收到数据时触发的触发器。
以下示例显示了计费场景,并使用了早期和延迟触发
// Create a bill at the end of the month.
AfterWatermark.pastEndOfWindow()
// During the month, get near real-time estimates.
.withEarlyFirings(
AfterProcessingTime
.pastFirstElementInPane()
.plusDuration(Duration.standardMinutes(1))
// Fire on any late data so the bill can be corrected.
.withLateFirings(AfterPane.elementCountAtLeast(1))AfterWatermark(
early=AfterProcessingTime(delay=1 * 60), late=AfterCount(1))trigger := trigger.AfterEndOfWindow().
EarlyFiring(trigger.AfterProcessingTime().
PlusDelay(60 * time.Second)).
LateFiring(trigger.Repeat(trigger.AfterCount(1)))9.1.1. 默认触发器
PCollection 的默认触发器基于事件时间,并在 Beam 的水印经过窗口结束时间时发出窗口的结果,然后在每次延迟数据到达时触发。
但是,如果您同时使用默认窗口配置和默认触发器,默认触发器只发出一次,延迟数据将被丢弃。这是因为默认窗口配置的允许延迟值为 0。有关修改此行为的信息,请参阅处理延迟数据部分。
9.2. 处理时间触发器
AfterProcessingTime 触发器基于处理时间运行。例如,AfterProcessingTime.pastFirstElementInPane() AfterProcessingTime trigger.AfterProcessingTime() 触发器在自收到数据后经过一定处理时间后发出窗口。处理时间由系统时钟决定,而不是数据元素的时间戳。
AfterProcessingTime 触发器对于从窗口(尤其是具有较长时间范围的窗口,例如单一全局窗口)中触发早期结果很有用。
9.3. 数据驱动触发器
Beam 提供一个数据驱动触发器,AfterPane.elementCountAtLeast() AfterCount trigger.AfterCount()。此触发器基于元素计数;它在当前窗格至少收集了 N 个元素后触发。这允许窗口发出早期结果(在所有数据累积之前),如果您使用的是单个全局窗口,这可能特别有用。
需要注意的是,例如,如果您指定 .elementCountAtLeast(50) AfterCount(50) trigger.AfterCount(50) 并且只到达了 32 个元素,那么这 32 个元素将永远存在。如果您认为这 32 个元素很重要,请考虑使用 复合触发器 来组合多个条件。这允许您指定多个触发条件,例如“当我收到 50 个元素时或每 1 秒触发一次”。
9.4. 设置触发器
当您使用 WindowWindowIntobeam.WindowInto 变换为 PCollection 设置窗口函数时,您也可以指定触发器。
您可以通过调用 Window.into() 变换的结果上的 .triggering() 方法为 PCollection 设置触发器。此代码示例为 PCollection 设置了基于时间的触发器,该触发器在该窗口中的第一个元素被处理后一分钟发出结果。代码示例中的最后一行 .discardingFiredPanes() 设置了窗口的累积模式。
您可以通过在使用 WindowInto 变换时设置 trigger 参数来为 PCollection 设置触发器。此代码示例为 PCollection 设置了基于时间的触发器,该触发器在该窗口中的第一个元素被处理后一分钟发出结果。accumulation_mode 参数设置了窗口的累积模式。
您可以通过在使用 beam.WindowInto 变换时传入 beam.Trigger 参数来为 PCollection 设置触发器。此代码示例为 PCollection 设置了基于时间的触发器,该触发器在该窗口中的第一个元素被处理后一分钟发出结果。beam.AccumulationMode 参数设置了窗口的累积模式。
PCollection<String> pc = ...;
pc.apply(Window.<String>into(FixedWindows.of(1, TimeUnit.MINUTES))
.triggering(AfterProcessingTime.pastFirstElementInPane()
.plusDelayOf(Duration.standardMinutes(1)))
.discardingFiredPanes()); pcollection | WindowInto(
FixedWindows(1 * 60),
trigger=AfterProcessingTime(1 * 60),
accumulation_mode=AccumulationMode.DISCARDING)windowedItems := beam.WindowInto(s,
window.NewFixedWindows(1*time.Minute), pcollection,
beam.Trigger(trigger.AfterProcessingTime().
PlusDelay(1*time.Minute)),
beam.AllowedLateness(30*time.Minute),
beam.PanesDiscard(),
)9.4.1. 窗口累积模式
当您指定触发器时,您还必须设置窗口的累积模式。当触发器触发时,它会将窗口的当前内容作为窗格发出。由于触发器可以多次触发,因此累积模式决定系统在触发器触发时是否累积窗口窗格,或者丢弃它们。
要将窗口设置为累积触发器触发时产生的窗格,请在设置触发器时调用 .accumulatingFiredPanes()。要将窗口设置为丢弃触发的窗格,请调用 .discardingFiredPanes()。
要将窗口设置为累积触发器触发时产生的窗格,请在设置触发器时将 accumulation_mode 参数设置为 ACCUMULATING。要将窗口设置为丢弃触发的窗格,请将 accumulation_mode 设置为 DISCARDING。
要将窗口设置为累积触发器触发时产生的窗格,请在设置触发器时将 beam.AccumulationMode 参数设置为 beam.PanesAccumulate()。要将窗口设置为丢弃触发的窗格,请将 beam.AccumulationMode 设置为 beam.PanesDiscard()。
让我们看一个使用具有固定时间窗口和基于数据的触发器的 PCollection 的示例。例如,如果您想做这样的事情,每个窗口都代表一个 10 分钟的运行平均值,但您希望比每 10 分钟更频繁地在 UI 中显示平均值的当前值。我们将假设以下条件
PCollection使用 10 分钟固定时间窗口。PCollection具有一个重复触发器,该触发器在每次到达 3 个元素时触发。
下图显示了关键 X 的数据事件,它们到达 PCollection 并被分配到窗口中。为了使图表更简单,我们假设这些事件都按顺序到达管道中。
9.4.1.1. 累积模式
如果将触发器设置为累积模式,则触发器将在每次触发时发出以下值。请记住,触发器在每次到达三个元素时触发
First trigger firing: [5, 8, 3]
Second trigger firing: [5, 8, 3, 15, 19, 23]
Third trigger firing: [5, 8, 3, 15, 19, 23, 9, 13, 10]
9.4.1.2. 丢弃模式
如果将触发器设置为丢弃模式,则触发器将在每次触发时发出以下值
First trigger firing: [5, 8, 3]
Second trigger firing: [15, 19, 23]
Third trigger firing: [9, 13, 10]
9.4.2. 处理延迟数据
如果您希望管道处理在水印经过窗口结束时间后到达的数据,则可以在设置窗口配置时应用允许延迟。这将使您的触发器有机会对延迟数据做出反应。如果设置了允许延迟,则默认触发器将在每次延迟数据到达时立即发出新结果。
您可以通过在设置窗口函数时使用 .withAllowedLateness() allowed_lateness beam.AllowedLateness() 来设置允许延迟
PCollection<String> pc = ...;
pc.apply(Window.<String>into(FixedWindows.of(1, TimeUnit.MINUTES))
.triggering(AfterProcessingTime.pastFirstElementInPane()
.plusDelayOf(Duration.standardMinutes(1)))
.withAllowedLateness(Duration.standardMinutes(30)); pc = [Initial PCollection]
pc | beam.WindowInto(
FixedWindows(60),
trigger=AfterProcessingTime(60),
allowed_lateness=1800) # 30 minutes
| ...allowedToBeLateItems := beam.WindowInto(s,
window.NewFixedWindows(1*time.Minute), pcollection,
beam.Trigger(trigger.AfterProcessingTime().
PlusDelay(1*time.Minute)),
beam.AllowedLateness(30*time.Minute),
)此允许延迟会传播到所有作为对原始 PCollection 应用变换的结果而派生的 PCollection。如果您希望在管道中的后期更改允许延迟,您可以再次显式地应用 Window.configure().withAllowedLateness() allowed_lateness beam.AllowedLateness()。
9.5. 复合触发器
您可以组合多个触发器以形成复合触发器,并且可以指定触发器以重复发出结果,最多发出一次,或在其他自定义条件下发出结果。
9.5.1. 复合触发器类型
Beam 包括以下复合触发器
- 您可以通过
.withEarlyFirings和.withLateFirings为AfterWatermark.pastEndOfWindow添加额外的早期触发或延迟触发。 Repeatedly.forever指定一个永远执行的触发器。只要触发器的条件满足,它就会导致窗口发出结果,然后重置并重新开始。将Repeatedly.forever与.orFinally组合起来指定导致重复触发器停止的条件可能很有用。AfterEach.inOrder组合多个触发器以按特定顺序触发。每次序列中的触发器发出窗口时,序列都会前进到下一个触发器。AfterFirst接受多个触发器,并在其任何参数触发器满足时首次发出。这等效于多个触发器的逻辑 OR 操作。AfterAll接受多个触发器,并在其所有参数触发器满足时发出。这等效于多个触发器的逻辑 AND 操作。orFinally可以用作最终条件,导致任何触发器最终触发一次,并且永远不会再次触发。
9.5.2. 与 AfterWatermark 的组合
一些最有用的复合触发器会在 Beam 估计所有数据都已到达时(即水位线经过窗口末尾)触发一次,同时还会触发以下一个或两个事件:
在水位线经过窗口末尾之前进行的推测性触发,以便更快地处理部分结果。
在水位线经过窗口末尾之后发生的延迟触发,以便处理延迟到达的数据。
可以使用 AfterWatermark 表达这种模式。例如,以下示例触发器代码在以下条件下触发:
在 Beam 估计所有数据都已到达时(水位线经过窗口末尾)。
任何时候延迟数据到达,延迟 10 分钟。
- 在两天后,我们假设不再有感兴趣的数据到达,触发器停止执行。
.apply(Window
.configure()
.triggering(AfterWatermark
.pastEndOfWindow()
.withLateFirings(AfterProcessingTime
.pastFirstElementInPane()
.plusDelayOf(Duration.standardMinutes(10))))
.withAllowedLateness(Duration.standardDays(2)));pcollection | WindowInto(
FixedWindows(1 * 60),
trigger=AfterWatermark(late=AfterProcessingTime(10 * 60)),
allowed_lateness=10,
accumulation_mode=AccumulationMode.DISCARDING)compositeTriggerItems := beam.WindowInto(s,
window.NewFixedWindows(1*time.Minute), pcollection,
beam.Trigger(trigger.AfterEndOfWindow().
LateFiring(trigger.AfterProcessingTime().
PlusDelay(10*time.Minute))),
beam.AllowedLateness(2*24*time.Hour),
)9.5.3. 其他复合触发器
还可以构建其他类型的复合触发器。以下示例代码展示了一个简单的复合触发器,它在窗格至少包含 100 个元素或 1 分钟后触发。
Repeatedly.forever(AfterFirst.of(
AfterPane.elementCountAtLeast(100),
AfterProcessingTime.pastFirstElementInPane().plusDelayOf(Duration.standardMinutes(1))))pcollection | WindowInto(
FixedWindows(1 * 60),
trigger=Repeatedly(
AfterAny(AfterCount(100), AfterProcessingTime(1 * 60))),
accumulation_mode=AccumulationMode.DISCARDING)10. 指标
在 Beam 模型中,指标提供了一些关于用户管道当前状态的信息,可能是在管道运行时。可能存在不同的原因,例如:
- 检查在运行管道中的特定步骤时遇到的错误数量。
- 监控与后端服务进行的 RPC 数量。
- 检索已处理元素数量的准确计数。
- 等等。
10.1. Beam 指标的主要概念
- 命名。每个指标都有一个名称,该名称由命名空间和实际名称组成。命名空间可用于区分具有相同名称的多个指标,还允许查询特定命名空间中的所有指标。
- 作用域。每个指标都针对管道中的特定步骤进行报告,指示指标递增时正在运行的代码。
- 动态创建。指标可以在运行时创建,无需预先声明,这与创建日志记录器的方式类似。这使得在实用程序代码中生成指标并对其进行有用的报告变得更加容易。
- 优雅降级。如果运行器不支持度量报告的某些部分,则回退行为是丢弃度量更新,而不是使管道失败。如果运行器不支持度量查询的某些部分,则运行器将不会返回相关数据。
报告的指标隐式地作用于报告它们的管道中的转换。这允许在多个地方报告相同的指标名称,并识别每个转换报告的值,以及在整个管道中聚合指标。
注意:指标在管道执行期间是否可访问或仅在作业完成后可访问,取决于运行器。
10.2. 指标类型
目前支持三种类型的指标:Counter、Distribution 和 Gauge。
在 Go 的 Beam SDK 中,必须将框架提供的 context.Context 传递给指标,否则不会记录指标值。当 context.Context 是第一个参数时,框架会自动向 ProcessElement 和类似方法提供有效的 context.Context。
Counter:报告单个长整型值并可以递增或递减的指标。
Counter counter = Metrics.counter( "namespace", "counter1");
@ProcessElement
public void processElement(ProcessContext context) {
// count the elements
counter.inc();
...
}var counter = beam.NewCounter("namespace", "counter1")
func (fn *MyDoFn) ProcessElement(ctx context.Context, ...) {
// count the elements
counter.Inc(ctx, 1)
...
}from apache_beam import metrics
class MyDoFn(beam.DoFn):
def __init__(self):
self.counter = metrics.Metrics.counter("namespace", "counter1")
def process(self, element):
self.counter.inc()
yield elementDistribution:报告有关报告值的分布信息的指标。
Distribution distribution = Metrics.distribution( "namespace", "distribution1");
@ProcessElement
public void processElement(ProcessContext context) {
Integer element = context.element();
// create a distribution (histogram) of the values
distribution.update(element);
...
}var distribution = beam.NewDistribution("namespace", "distribution1")
func (fn *MyDoFn) ProcessElement(ctx context.Context, v int64, ...) {
// create a distribution (histogram) of the values
distribution.Update(ctx, v)
...
}class MyDoFn(beam.DoFn):
def __init__(self):
self.distribution = metrics.Metrics.distribution("namespace", "distribution1")
def process(self, element):
self.distribution.update(element)
yield elementGauge:报告已报告值中的最新值的指标。由于指标是从许多工作器收集的,因此该值可能不是绝对最新的值,而是最新的值之一。
Gauge gauge = Metrics.gauge( "namespace", "gauge1");
@ProcessElement
public void processElement(ProcessContext context) {
Integer element = context.element();
// create a gauge (latest value received) of the values
gauge.set(element);
...
}var gauge = beam.NewGauge("namespace", "gauge1")
func (fn *MyDoFn) ProcessElement(ctx context.Context, v int64, ...) {
// create a gauge (latest value received) of the values
gauge.Set(ctx, v)
...
}class MyDoFn(beam.DoFn):
def __init__(self):
self.gauge = metrics.Metrics.gauge("namespace", "gauge1")
def process(self, element):
self.gauge.set(element)
yield element10.3. 查询指标
PipelineResult 具有 metrics() 方法,该方法返回一个 MetricResults 对象,允许访问指标。MetricResults 中可用的主要方法允许查询与给定过滤器匹配的所有指标。
beam.PipelineResult 具有 Metrics() 方法,该方法返回一个 metrics.Results 对象,允许访问指标。metrics.Results 中可用的主要方法允许查询与给定过滤器匹配的所有指标。它接收一个具有 SingleResult 参数类型的谓词,该谓词可用于自定义过滤器。
PipelineResult 具有一个 metrics 方法,该方法返回一个 MetricResults 对象。MetricResults 对象允许访问指标。MetricResults 对象中可用的主要方法是 query,它允许查询与给定过滤器匹配的所有指标。query 方法接收一个 MetricsFilter 对象,可用于根据多个不同的条件进行过滤。查询 MetricResults 对象将返回一个字典,其中包含 MetricResult 对象的列表,字典根据类型进行组织,例如 Counter、Distribution 和 Gauge。MetricResult 对象包含一个 result 函数,用于获取指标的值,并包含一个 key 属性。key 属性包含有关命名空间和指标名称的信息。
public interface PipelineResult {
MetricResults metrics();
}
public abstract class MetricResults {
public abstract MetricQueryResults queryMetrics(@Nullable MetricsFilter filter);
}
public interface MetricQueryResults {
Iterable<MetricResult<Long>> getCounters();
Iterable<MetricResult<DistributionResult>> getDistributions();
Iterable<MetricResult<GaugeResult>> getGauges();
}
public interface MetricResult<T> {
MetricName getName();
String getStep();
T getCommitted();
T getAttempted();
}func queryMetrics(pr beam.PipelineResult, ns, n string) metrics.QueryResults {
return pr.Metrics().Query(func(r beam.MetricResult) bool {
return r.Namespace() == ns && r.Name() == n
})
}class PipelineResult:
def metrics(self) -> MetricResults:
"""Returns a the metric results from the pipeline."""
class MetricResults:
def query(self, filter: MetricsFilter) -> Dict[str, List[MetricResult]]:
"""Filters the results against the specified filter."""
class MetricResult:
def result(self):
"""Returns the value of the metric."""10.4. 在管道中使用指标
下面是一个如何在用户管道中使用 Counter 指标的简单示例。
// creating a pipeline with custom metrics DoFn
pipeline
.apply(...)
.apply(ParDo.of(new MyMetricsDoFn()));
pipelineResult = pipeline.run().waitUntilFinish(...);
// request the metric called "counter1" in namespace called "namespace"
MetricQueryResults metrics =
pipelineResult
.metrics()
.queryMetrics(
MetricsFilter.builder()
.addNameFilter(MetricNameFilter.named("namespace", "counter1"))
.build());
// print the metric value - there should be only one line because there is only one metric
// called "counter1" in the namespace called "namespace"
for (MetricResult<Long> counter: metrics.getCounters()) {
System.out.println(counter.getName() + ":" + counter.getAttempted());
}
public class MyMetricsDoFn extends DoFn<Integer, Integer> {
private final Counter counter = Metrics.counter( "namespace", "counter1");
@ProcessElement
public void processElement(ProcessContext context) {
// count the elements
counter.inc();
context.output(context.element());
}
}func addMetricDoFnToPipeline(s beam.Scope, input beam.PCollection) beam.PCollection {
return beam.ParDo(s, &MyMetricsDoFn{}, input)
}
func executePipelineAndGetMetrics(ctx context.Context, p *beam.Pipeline) (metrics.QueryResults, error) {
pr, err := beam.Run(ctx, runner, p)
if err != nil {
return metrics.QueryResults{}, err
}
// Request the metric called "counter1" in namespace called "namespace"
ms := pr.Metrics().Query(func(r beam.MetricResult) bool {
return r.Namespace() == "namespace" && r.Name() == "counter1"
})
// Print the metric value - there should be only one line because there is
// only one metric called "counter1" in the namespace called "namespace"
for _, c := range ms.Counters() {
fmt.Println(c.Namespace(), "-", c.Name(), ":", c.Committed)
}
return ms, nil
}
type MyMetricsDoFn struct {
counter beam.Counter
}
func init() {
beam.RegisterType(reflect.TypeOf((*MyMetricsDoFn)(nil)))
}
func (fn *MyMetricsDoFn) Setup() {
// While metrics can be defined in package scope or dynamically
// it's most efficient to include them in the DoFn.
fn.counter = beam.NewCounter("namespace", "counter1")
}
func (fn *MyMetricsDoFn) ProcessElement(ctx context.Context, v beam.V, emit func(beam.V)) {
// count the elements
fn.counter.Inc(ctx, 1)
emit(v)
}class MyMetricsDoFn(beam.DoFn):
def __init__(self):
self.counter = metrics.Metrics.counter("namespace", "counter1")
def process(self, element):
counter.inc()
yield element
pipeline = beam.Pipeline()
pipeline | beam.ParDo(MyMetricsDoFn())
result = pipeline.run().wait_until_finish()
metrics = result.metrics().query(
metrics.MetricsFilter.with_namespace("namespace").with_name("counter1"))
for metric in metrics["counters"]:
print(metric)10.5. 导出指标
Beam 指标可以导出到外部接收器。如果在配置中设置了指标接收器,运行器将以默认的 5 秒周期将指标推送到接收器。配置存储在 MetricsOptions 类中。它包含推送周期配置,以及接收器特定选项,例如类型和 URL。目前仅支持 REST HTTP 和 Graphite 接收器,并且仅 Flink 和 Spark 运行器支持指标导出。
此外,Beam 指标会导出到内部 Spark 和 Flink 仪表板,以便在它们各自的 UI 中查看。
11. 状态和计时器
Beam 的窗口和触发机制提供了一种强大的抽象,用于根据时间戳对无界输入数据进行分组和聚合。但是,对于某些聚合用例,开发人员可能需要比窗口和触发器提供的更高级别的控制。Beam 提供了一个 API,用于手动管理每个键的状态,从而允许对聚合进行细粒度控制。
Beam 的状态 API 对每个键建模状态。要使用状态 API,请从一个键控 PCollection 开始,在 Java 中,它被建模为 PCollection<KV<K, V>>。处理此 PCollection 的 ParDo 现在可以声明状态变量。在 ParDo 内部,这些状态变量可用于写入或更新当前键的状态,或读取以前为该键写入的状态。状态始终完全作用于当前处理键。
窗口仍然可以与有状态处理一起使用。每个键的所有状态都作用于当前窗口。这意味着在首次为给定窗口看到键时,任何状态读取都将返回空,并且运行器可以在窗口完成后垃圾收集状态。在有状态操作符之前使用 Beam 的窗口化聚合通常也很有用。例如,使用组合器预聚合数据,然后将聚合数据存储在状态中。使用状态和计时器时,目前不支持合并窗口。
有时会使用有状态处理来在 DoFn 中实现状态机样式的处理。这样做时,务必记住,输入 PCollection 中的元素没有保证的顺序,并确保程序逻辑对这种情况具有弹性。使用 DirectRunner 编写的单元测试会打乱元素处理的顺序,建议使用它们测试正确性。
在 Java 中,DoFn 通过创建表示每个状态的最终 StateSpec 成员变量来声明要访问的状态。每个状态都必须使用 StateId 注释命名;此名称对于图中的 ParDo 是唯一的,与图中其他节点无关。DoFn 可以声明多个状态变量。
在 Python 中,DoFn 通过创建表示每个状态的 StateSpec 类成员变量来声明要访问的状态。每个 StateSpec 都用一个名称初始化,该名称对于图中的 ParDo 是唯一的,与图中其他节点无关。DoFn 可以声明多个状态变量。
在 Go 中,DoFn 通过创建表示每个状态的状态结构成员变量来声明要访问的状态。每个状态变量都用一个键初始化,该键对于图中的 ParDo 是唯一的,与图中其他节点无关。如果没有提供名称,则键默认为成员变量的名称。DoFn 可以声明多个状态变量。
注意:Typescript 的 Beam SDK 尚未支持状态和计时器 API,但可以使用跨语言管道(见下文)使用这些功能。
11.1. 状态类型
Beam 提供了几种类型的状态
ValueState
ValueState 是一个标量状态值。对于输入中的每个键,ValueState 将存储一个类型化的值,该值可以在 DoFn 的 @ProcessElement 或 @OnTimer 方法中读取和修改。如果 ValueState 的类型已注册编码器,则 Beam 将自动推断状态值的编码器。否则,可以在创建 ValueState 时显式指定编码器。例如,以下 ParDo 创建一个单个状态变量,用于累积看到的元素数量。
注意:ValueState 在 Python SDK 中称为 ReadModifyWriteState。
PCollection<KV<String, ValueT>> perUser = readPerUser();
perUser.apply(ParDo.of(new DoFn<KV<String, ValueT>, OutputT>() {
@StateId("state") private final StateSpec<ValueState<Integer>> numElements = StateSpecs.value();
@ProcessElement public void process(@StateId("state") ValueState<Integer> state) {
// Read the number element seen so far for this user key.
// state.read() returns null if it was never set. The below code allows us to have a default value of 0.
int currentValue = MoreObjects.firstNonNull(state.read(), 0);
// Update the state.
state.write(currentValue + 1);
}
}));// valueStateFn keeps track of the number of elements seen.
type valueStateFn struct {
Val state.Value[int]
}
func (s *valueStateFn) ProcessElement(p state.Provider, book string, word string, emitWords func(string)) error {
// Get the value stored in our state
val, ok, err := s.Val.Read(p)
if err != nil {
return err
}
if !ok {
s.Val.Write(p, 1)
} else {
s.Val.Write(p, val+1)
}
if val > 10000 {
// Example of clearing and starting again with an empty bag
s.Val.Clear(p)
}
return nil
}Beam 还允许显式指定 ValueState 值的编码器。例如
PCollection<KV<String, ValueT>> perUser = readPerUser();
perUser.apply(ParDo.of(new DoFn<KV<String, ValueT>, OutputT>() {
@StateId("state") private final StateSpec<ValueState<MyType>> numElements = StateSpecs.value(new MyTypeCoder());
...
}));class ReadModifyWriteStateDoFn(DoFn):
STATE_SPEC = ReadModifyWriteStateSpec('num_elements', VarIntCoder())
def process(self, element, state=DoFn.StateParam(STATE_SPEC)):
# Read the number element seen so far for this user key.
current_value = state.read() or 0
state.write(current_value+1)
_ = (p | 'Read per user' >> ReadPerUser()
| 'state pardo' >> beam.ParDo(ReadModifyWriteStateDoFn()))type valueStateDoFn struct {
Val state.Value[MyCustomType]
}
func encode(m MyCustomType) []byte {
return m.Bytes()
}
func decode(b []byte) MyCustomType {
return MyCustomType{}.FromBytes(b)
}
func init() {
beam.RegisterCoder(reflect.TypeOf((*MyCustomType)(nil)).Elem(), encode, decode)
}const pcoll = root.apply(
beam.create([
{ key: "a", value: 1 },
{ key: "b", value: 10 },
{ key: "a", value: 100 },
])
);
const result: PCollection<number> = await pcoll
.apply(
withCoderInternal(
new KVCoder(new StrUtf8Coder(), new VarIntCoder())
)
)
.applyAsync(
pythonTransform(
// Construct a new Transform from source.
"__constructor__",
[
pythonCallable(`
# Define a DoFn to be used below.
class ReadModifyWriteStateDoFn(beam.DoFn):
STATE_SPEC = beam.transforms.userstate.ReadModifyWriteStateSpec(
'num_elements', beam.coders.VarIntCoder())
def process(self, element, state=beam.DoFn.StateParam(STATE_SPEC)):
current_value = state.read() or 0
state.write(current_value + 1)
yield current_value + 1
class MyPythonTransform(beam.PTransform):
def expand(self, pcoll):
return pcoll | beam.ParDo(ReadModifyWriteStateDoFn())
`),
],
// Keyword arguments to pass to the transform, if any.
{},
// Output type if it cannot be inferred
{ requestedOutputCoders: { output: new VarIntCoder() } }
)
);CombiningState
CombiningState 允许你创建使用 Beam 组合器更新的状态对象。例如,前面的 ValueState 示例可以重写为使用 CombiningState
PCollection<KV<String, ValueT>> perUser = readPerUser();
perUser.apply(ParDo.of(new DoFn<KV<String, ValueT>, OutputT>() {
@StateId("state") private final StateSpec<CombiningState<Integer, int[], Integer>> numElements =
StateSpecs.combining(Sum.ofIntegers());
@ProcessElement public void process(@StateId("state") ValueState<Integer> state) {
state.add(1);
}
}));class CombiningStateDoFn(DoFn):
SUM_TOTAL = CombiningValueStateSpec('total', sum)
def process(self, element, state=DoFn.StateParam(SUM_TOTAL)):
state.add(1)
_ = (p | 'Read per user' >> ReadPerUser()
| 'Combine state pardo' >> beam.ParDo(CombiningStateDofn()))// combiningStateFn keeps track of the number of elements seen.
type combiningStateFn struct {
// types are the types of the accumulator, input, and output respectively
Val state.Combining[int, int, int]
}
func (s *combiningStateFn) ProcessElement(p state.Provider, book string, word string, emitWords func(string)) error {
// Get the value stored in our state
val, _, err := s.Val.Read(p)
if err != nil {
return err
}
s.Val.Add(p, 1)
if val > 10000 {
// Example of clearing and starting again with an empty bag
s.Val.Clear(p)
}
return nil
}
func combineState(s beam.Scope, input beam.PCollection) beam.PCollection {
// ...
// CombineFn param can be a simple fn like this or a structural CombineFn
cFn := state.MakeCombiningState[int, int, int]("stateKey", func(a, b int) int {
return a + b
})
combined := beam.ParDo(s, combiningStateFn{Val: cFn}, input)
// ...
BagState
状态的一个常见用例是累积多个元素。BagState 允许累积无序的元素集。这允许将元素添加到集合中,而无需先读取整个集合,这是一种效率提升。此外,支持分页读取的运行器可以允许单个包的大小大于可用内存。
PCollection<KV<String, ValueT>> perUser = readPerUser();
perUser.apply(ParDo.of(new DoFn<KV<String, ValueT>, OutputT>() {
@StateId("state") private final StateSpec<BagState<ValueT>> numElements = StateSpecs.bag();
@ProcessElement public void process(
@Element KV<String, ValueT> element,
@StateId("state") BagState<ValueT> state) {
// Add the current element to the bag for this key.
state.add(element.getValue());
if (shouldFetch()) {
// Occasionally we fetch and process the values.
Iterable<ValueT> values = state.read();
processValues(values);
state.clear(); // Clear the state for this key.
}
}
}));class BagStateDoFn(DoFn):
ALL_ELEMENTS = BagStateSpec('buffer', coders.VarIntCoder())
def process(self, element_pair, state=DoFn.StateParam(ALL_ELEMENTS)):
state.add(element_pair[1])
if should_fetch():
all_elements = list(state.read())
process_values(all_elements)
state.clear()
_ = (p | 'Read per user' >> ReadPerUser()
| 'Bag state pardo' >> beam.ParDo(BagStateDoFn()))// bagStateFn only emits words that haven't been seen
type bagStateFn struct {
Bag state.Bag[string]
}
func (s *bagStateFn) ProcessElement(p state.Provider, book, word string, emitWords func(string)) error {
// Get all values we've written to this bag state in this window.
vals, ok, err := s.Bag.Read(p)
if err != nil {
return err
}
if !ok || !contains(vals, word) {
emitWords(word)
s.Bag.Add(p, word)
}
if len(vals) > 10000 {
// Example of clearing and starting again with an empty bag
s.Bag.Clear(p)
}
return nil
}11.2. 延迟状态读取
当 DoFn 包含多个状态规范时,按顺序读取每个状态可能会很慢。调用状态上的 read() 函数可能会导致运行器执行阻塞读取。按顺序执行多个阻塞读取会增加元素处理的延迟。如果你知道状态总是会被读取,则可以将其注释为 @AlwaysFetched,然后运行器可以预取所有必要的状态。例如
PCollection<KV<String, ValueT>> perUser = readPerUser();
perUser.apply(ParDo.of(new DoFn<KV<String, ValueT>, OutputT>() {
@StateId("state1") private final StateSpec<ValueState<Integer>> state1 = StateSpecs.value();
@StateId("state2") private final StateSpec<ValueState<String>> state2 = StateSpecs.value();
@StateId("state3") private final StateSpec<BagState<ValueT>> state3 = StateSpecs.bag();
@ProcessElement public void process(
@AlwaysFetched @StateId("state1") ValueState<Integer> state1,
@AlwaysFetched @StateId("state2") ValueState<String> state2,
@AlwaysFetched @StateId("state3") BagState<ValueT> state3) {
state1.read();
state2.read();
state3.read();
}
}));This is not supported yet, see https://github.com/apache/beam/issues/20739.This is not supported yet, see https://github.com/apache/beam/issues/22964.
但是,如果存在状态未被获取的代码路径,则使用 @AlwaysFetched 进行注释会为这些路径添加不必要的获取。在这种情况下,readLater 方法允许运行器知道将来会读取状态,从而允许将多个状态读取一起批处理。
PCollection<KV<String, ValueT>> perUser = readPerUser();
perUser.apply(ParDo.of(new DoFn<KV<String, ValueT>, OutputT>() {
@StateId("state1") private final StateSpec<ValueState<Integer>> state1 = StateSpecs.value();
@StateId("state2") private final StateSpec<ValueState<String>> state2 = StateSpecs.value();
@StateId("state3") private final StateSpec<BagState<ValueT>> state3 = StateSpecs.bag();
@ProcessElement public void process(
@StateId("state1") ValueState<Integer> state1,
@StateId("state2") ValueState<String> state2,
@StateId("state3") BagState<ValueT> state3) {
if (/* should read state */) {
state1.readLater();
state2.readLater();
state3.readLater();
}
// The runner can now batch all three states into a single read, reducing latency.
processState1(state1.read());
processState2(state2.read());
processState3(state3.read());
}
}));11.3. 计时器
Beam 提供了一个每个键的计时器回调 API。这允许延迟处理使用状态 API 存储的数据。计时器可以设置为在事件时间或处理时间时间戳回调。每个计时器都用 TimerId 标识。每个键的给定计时器只能设置为一个时间戳。在计时器上调用 set 会覆盖该键的计时器的先前触发时间。
11.3.1. 事件时间计时器
事件时间计时器在 DoFn 的输入水位线经过设置计时器的时刻时触发,这意味着运行器认为不再有时间戳早于计时器时间戳的元素要处理。这允许进行事件时间聚合。
PCollection<KV<String, ValueT>> perUser = readPerUser();
perUser.apply(ParDo.of(new DoFn<KV<String, ValueT>, OutputT>() {
@StateId("state") private final StateSpec<ValueState<Integer>> state = StateSpecs.value();
@TimerId("timer") private final TimerSpec timer = TimerSpecs.timer(TimeDomain.EVENT_TIME);
@ProcessElement public void process(
@Element KV<String, ValueT> element,
@Timestamp Instant elementTs,
@StateId("state") ValueState<Integer> state,
@TimerId("timer") Timer timer) {
...
// Set an event-time timer to the element timestamp.
timer.set(elementTs);
}
@OnTimer("timer") public void onTimer() {
//Process timer.
}
}));class EventTimerDoFn(DoFn):
ALL_ELEMENTS = BagStateSpec('buffer', coders.VarIntCoder())
TIMER = TimerSpec('timer', TimeDomain.WATERMARK)
def process(self,
element_pair,
t = DoFn.TimestampParam,
buffer = DoFn.StateParam(ALL_ELEMENTS),
timer = DoFn.TimerParam(TIMER)):
buffer.add(element_pair[1])
# Set an event-time timer to the element timestamp.
timer.set(t)
@on_timer(TIMER)
def expiry_callback(self, buffer = DoFn.StateParam(ALL_ELEMENTS)):
state.clear()
_ = (p | 'Read per user' >> ReadPerUser()
| 'EventTime timer pardo' >> beam.ParDo(EventTimerDoFn()))type eventTimerDoFn struct {
State state.Value[int64]
Timer timers.EventTime
}
func (fn *eventTimerDoFn) ProcessElement(ts beam.EventTime, sp state.Provider, tp timers.Provider, book, word string, emitWords func(string)) {
// ...
// Set an event-time timer to the element timestamp.
fn.Timer.Set(tp, ts.ToTime())
// ...
}
func (fn *eventTimerDoFn) OnTimer(sp state.Provider, tp timers.Provider, w beam.Window, key string, timer timers.Context, emitWords func(string)) {
switch timer.Family {
case fn.Timer.Family:
// process callback for this timer
}
}
func AddEventTimeDoFn(s beam.Scope, in beam.PCollection) beam.PCollection {
return beam.ParDo(s, &eventTimerDoFn{
// Timers are given family names so their callbacks can be handled independantly.
Timer: timers.InEventTime("processWatermark"),
State: state.MakeValueState[int64]("latest"),
}, in)
}11.3.2. 处理时间计时器
处理时间计时器在实际挂钟时间经过时触发。这通常用于在处理之前创建更大的数据批次。它也可以用于调度应在特定时间发生的事件。与事件时间计时器一样,处理时间计时器是每个键的——每个键都有计时器的单独副本。
虽然处理时间计时器可以设置为绝对时间戳,但通常将其设置为相对于当前时间的偏移量。在 Java 中,可以使用Timer.offset和Timer.setRelative方法来实现这一点。
PCollection<KV<String, ValueT>> perUser = readPerUser();
perUser.apply(ParDo.of(new DoFn<KV<String, ValueT>, OutputT>() {
@TimerId("timer") private final TimerSpec timer = TimerSpecs.timer(TimeDomain.PROCESSING_TIME);
@ProcessElement public void process(@TimerId("timer") Timer timer) {
...
// Set a timer to go off 30 seconds in the future.
timer.offset(Duration.standardSeconds(30)).setRelative();
}
@OnTimer("timer") public void onTimer() {
//Process timer.
}
}));class ProcessingTimerDoFn(DoFn):
ALL_ELEMENTS = BagStateSpec('buffer', coders.VarIntCoder())
TIMER = TimerSpec('timer', TimeDomain.REAL_TIME)
def process(self,
element_pair,
buffer = DoFn.StateParam(ALL_ELEMENTS),
timer = DoFn.TimerParam(TIMER)):
buffer.add(element_pair[1])
# Set a timer to go off 30 seconds in the future.
timer.set(Timestamp.now() + Duration(seconds=30))
@on_timer(TIMER)
def expiry_callback(self, buffer = DoFn.StateParam(ALL_ELEMENTS)):
# Process timer.
state.clear()
_ = (p | 'Read per user' >> ReadPerUser()
| 'ProcessingTime timer pardo' >> beam.ParDo(ProcessingTimerDoFn()))type processingTimerDoFn struct {
Timer timers.ProcessingTime
}
func (fn *processingTimerDoFn) ProcessElement(sp state.Provider, tp timers.Provider, book, word string, emitWords func(string)) {
// ...
// Set a timer to go off 30 seconds in the future.
fn.Timer.Set(tp, time.Now().Add(30*time.Second))
// ...
}
func (fn *processingTimerDoFn) OnTimer(sp state.Provider, tp timers.Provider, w beam.Window, key string, timer timers.Context, emitWords func(string)) {
switch timer.Family {
case fn.Timer.Family:
// process callback for this timer
}
}
func AddProcessingTimeDoFn(s beam.Scope, in beam.PCollection) beam.PCollection {
return beam.ParDo(s, &processingTimerDoFn{
// Timers are given family names so their callbacks can be handled independantly.
Timer: timers.InProcessingTime("timer"),
}, in)
}11.3.3. 动态计时器标签
Beam 还支持使用 Java SDK 中的TimerMap动态设置计时器标签。这允许在DoFn中设置多个不同的计时器,并允许动态选择计时器标签 - 例如,基于输入元素中的数据。具有特定标签的计时器只能设置为单个时间戳,因此再次设置计时器将覆盖具有该标签的计时器的先前过期时间。每个TimerMap都使用计时器族 ID 进行标识,不同计时器族中的计时器是独立的。
在 Python SDK 中,可以在调用set()或clear()时指定动态计时器标签。默认情况下,如果未指定,计时器标签为空字符串。
PCollection<KV<String, ValueT>> perUser = readPerUser();
perUser.apply(ParDo.of(new DoFn<KV<String, ValueT>, OutputT>() {
@TimerFamily("actionTimers") private final TimerSpec timer =
TimerSpecs.timerMap(TimeDomain.EVENT_TIME);
@ProcessElement public void process(
@Element KV<String, ValueT> element,
@Timestamp Instant elementTs,
@TimerFamily("actionTimers") TimerMap timers) {
timers.set(element.getValue().getActionType(), elementTs);
}
@OnTimerFamily("actionTimers") public void onTimer(@TimerId String timerId) {
LOG.info("Timer fired with id " + timerId);
}
}));class TimerDoFn(DoFn):
ALL_ELEMENTS = BagStateSpec('buffer', coders.VarIntCoder())
TIMER = TimerSpec('timer', TimeDomain.REAL_TIME)
def process(self,
element_pair,
buffer = DoFn.StateParam(ALL_ELEMENTS),
timer = DoFn.TimerParam(TIMER)):
buffer.add(element_pair[1])
# Set a timer to go off 30 seconds in the future with dynamic timer tag 'first_timer'.
# And set a timer to go off 60 seconds in the future with dynamic timer tag 'second_timer'.
timer.set(Timestamp.now() + Duration(seconds=30), dynamic_timer_tag='first_timer')
timer.set(Timestamp.now() + Duration(seconds=60), dynamic_timer_tag='second_timer')
# Note that a timer can also be explicitly cleared if previously set with a dynamic timer tag:
# timer.clear(dynamic_timer_tag=...)
@on_timer(TIMER)
def expiry_callback(self, buffer = DoFn.StateParam(ALL_ELEMENTS), timer_tag=DoFn.DynamicTimerTagParam):
# Process timer, the dynamic timer tag associated with expiring timer can be read back with DoFn.DynamicTimerTagParam.
buffer.clear()
yield (timer_tag, 'fired')
_ = (p | 'Read per user' >> ReadPerUser()
| 'ProcessingTime timer pardo' >> beam.ParDo(TimerDoFn()))type hasAction interface {
Action() string
}
type dynamicTagsDoFn[V hasAction] struct {
Timer timers.EventTime
}
func (fn *dynamicTagsDoFn[V]) ProcessElement(ts beam.EventTime, tp timers.Provider, key string, value V, emitWords func(string)) {
// ...
// Set a timer to go off 30 seconds in the future.
fn.Timer.Set(tp, ts.ToTime(), timers.WithTag(value.Action()))
// ...
}
func (fn *dynamicTagsDoFn[V]) OnTimer(tp timers.Provider, w beam.Window, key string, timer timers.Context, emitWords func(string)) {
switch timer.Family {
case fn.Timer.Family:
tag := timer.Tag // Do something with fired tag
_ = tag
}
}
func AddDynamicTimerTagsDoFn[V hasAction](s beam.Scope, in beam.PCollection) beam.PCollection {
return beam.ParDo(s, &dynamicTagsDoFn[V]{
Timer: timers.InEventTime("actionTimers"),
}, in)
}11.3.4. 计时器输出时间戳
默认情况下,事件时间计时器会将ParDo的输出水位保持到计时器的时间戳。这意味着如果计时器设置为下午 12 点,管道图中稍后完成的任何窗口化聚合或事件时间计时器在下午 12 点之后将不会过期。计时器的时间戳也是计时器回调的默认输出时间戳。这意味着从 onTimer 方法输出的任何元素将具有等于计时器触发时间戳的时间戳。对于处理时间计时器,默认输出时间戳和水位保持是在设置计时器时输入水位的当前值。
在某些情况下,DoFn 需要输出比计时器过期时间更早的时间戳,因此还需要将其输出水位保持到这些时间戳。例如,考虑以下管道,它将记录临时批处理到状态,并设置计时器来清空状态。
PCollection<KV<String, ValueT>> perUser = readPerUser();
perUser.apply(ParDo.of(new DoFn<KV<String, ValueT>, OutputT>() {
@StateId("elementBag") private final StateSpec<BagState<ValueT>> elementBag = StateSpecs.bag();
@StateId("timerSet") private final StateSpec<ValueState<Boolean>> timerSet = StateSpecs.value();
@TimerId("outputState") private final TimerSpec timer = TimerSpecs.timer(TimeDomain.PROCESSING_TIME);
@ProcessElement public void process(
@Element KV<String, ValueT> element,
@StateId("elementBag") BagState<ValueT> elementBag,
@StateId("timerSet") ValueState<Boolean> timerSet,
@TimerId("outputState") Timer timer) {
// Add the current element to the bag for this key.
elementBag.add(element.getValue());
if (!MoreObjects.firstNonNull(timerSet.read(), false)) {
// If the timer is not current set, then set it to go off in a minute.
timer.offset(Duration.standardMinutes(1)).setRelative();
timerSet.write(true);
}
}
@OnTimer("outputState") public void onTimer(
@StateId("elementBag") BagState<ValueT> elementBag,
@StateId("timerSet") ValueState<Boolean> timerSet,
OutputReceiver<ValueT> output) {
for (ValueT bufferedElement : elementBag.read()) {
// Output each element.
output.outputWithTimestamp(bufferedElement, bufferedElement.timestamp());
}
elementBag.clear();
// Note that the timer has now fired.
timerSet.clear();
}
}));type badTimerOutputTimestampsFn[V any] struct {
ElementBag state.Bag[V]
TimerSet state.Value[bool]
OutputState timers.ProcessingTime
}
func (fn *badTimerOutputTimestampsFn[V]) ProcessElement(sp state.Provider, tp timers.Provider, key string, value V, emit func(string)) error {
// Add the current element to the bag for this key.
if err := fn.ElementBag.Add(sp, value); err != nil {
return err
}
set, _, err := fn.TimerSet.Read(sp)
if err != nil {
return err
}
if !set {
fn.OutputState.Set(tp, time.Now().Add(1*time.Minute))
fn.TimerSet.Write(sp, true)
}
return nil
}
func (fn *badTimerOutputTimestampsFn[V]) OnTimer(sp state.Provider, tp timers.Provider, w beam.Window, key string, timer timers.Context, emit func(string)) error {
switch timer.Family {
case fn.OutputState.Family:
vs, _, err := fn.ElementBag.Read(sp)
if err != nil {
return err
}
for _, v := range vs {
// Output each element
emit(fmt.Sprintf("%v", v))
}
fn.ElementBag.Clear(sp)
// Note that the timer has now fired.
fn.TimerSet.Clear(sp)
}
return nil
}这段代码的问题在于 ParDo 正在缓冲元素,但是没有阻止水位超出这些元素的时间戳,因此所有这些元素都可能被丢弃为迟到的数据。为了防止这种情况发生,需要在计时器上设置输出时间戳,以防止水位超出最小元素的时间戳。以下代码演示了这一点。
PCollection<KV<String, ValueT>> perUser = readPerUser();
perUser.apply(ParDo.of(new DoFn<KV<String, ValueT>, OutputT>() {
// The bag of elements accumulated.
@StateId("elementBag") private final StateSpec<BagState<ValueT>> elementBag = StateSpecs.bag();
// The timestamp of the timer set.
@StateId("timerTimestamp") private final StateSpec<ValueState<Long>> timerTimestamp = StateSpecs.value();
// The minimum timestamp stored in the bag.
@StateId("minTimestampInBag") private final StateSpec<CombiningState<Long, long[], Long>>
minTimestampInBag = StateSpecs.combining(Min.ofLongs());
@TimerId("outputState") private final TimerSpec timer = TimerSpecs.timer(TimeDomain.PROCESSING_TIME);
@ProcessElement public void process(
@Element KV<String, ValueT> element,
@StateId("elementBag") BagState<ValueT> elementBag,
@AlwaysFetched @StateId("timerTimestamp") ValueState<Long> timerTimestamp,
@AlwaysFetched @StateId("minTimestampInBag") CombiningState<Long, long[], Long> minTimestamp,
@TimerId("outputState") Timer timer) {
// Add the current element to the bag for this key.
elementBag.add(element.getValue());
// Keep track of the minimum element timestamp currently stored in the bag.
minTimestamp.add(element.getValue().timestamp());
// If the timer is already set, then reset it at the same time but with an updated output timestamp (otherwise
// we would keep resetting the timer to the future). If there is no timer set, then set one to expire in a minute.
Long timerTimestampMs = timerTimestamp.read();
Instant timerToSet = (timerTimestamp.isEmpty().read())
? Instant.now().plus(Duration.standardMinutes(1)) : new Instant(timerTimestampMs);
// Setting the outputTimestamp to the minimum timestamp in the bag holds the watermark to that timestamp until the
// timer fires. This allows outputting all the elements with their timestamp.
timer.withOutputTimestamp(minTimestamp.read()).s et(timerToSet).
timerTimestamp.write(timerToSet.getMillis());
}
@OnTimer("outputState") public void onTimer(
@StateId("elementBag") BagState<ValueT> elementBag,
@StateId("timerTimestamp") ValueState<Long> timerTimestamp,
OutputReceiver<ValueT> output) {
for (ValueT bufferedElement : elementBag.read()) {
// Output each element.
output.outputWithTimestamp(bufferedElement, bufferedElement.timestamp());
}
// Note that the timer has now fired.
timerTimestamp.clear();
}
}));Timer output timestamps is not yet supported in Python SDK. See https://github.com/apache/beam/issues/20705.type element[V any] struct {
Timestamp int64
Value V
}
type goodTimerOutputTimestampsFn[V any] struct {
ElementBag state.Bag[element[V]] // The bag of elements accumulated.
TimerTimerstamp state.Value[int64] // The timestamp of the timer set.
MinTimestampInBag state.Combining[int64, int64, int64] // The minimum timestamp stored in the bag.
OutputState timers.ProcessingTime // The timestamp of the timer.
}
func (fn *goodTimerOutputTimestampsFn[V]) ProcessElement(et beam.EventTime, sp state.Provider, tp timers.Provider, key string, value V, emit func(beam.EventTime, string)) error {
// ...
// Add the current element to the bag for this key, and preserve the event time.
if err := fn.ElementBag.Add(sp, element[V]{Timestamp: et.Milliseconds(), Value: value}); err != nil {
return err
}
// Keep track of the minimum element timestamp currently stored in the bag.
fn.MinTimestampInBag.Add(sp, et.Milliseconds())
// If the timer is already set, then reset it at the same time but with an updated output timestamp (otherwise
// we would keep resetting the timer to the future). If there is no timer set, then set one to expire in a minute.
ts, ok, _ := fn.TimerTimerstamp.Read(sp)
var tsToSet time.Time
if ok {
tsToSet = time.UnixMilli(ts)
} else {
tsToSet = time.Now().Add(1 * time.Minute)
}
minTs, _, _ := fn.MinTimestampInBag.Read(sp)
outputTs := time.UnixMilli(minTs)
// Setting the outputTimestamp to the minimum timestamp in the bag holds the watermark to that timestamp until the
// timer fires. This allows outputting all the elements with their timestamp.
fn.OutputState.Set(tp, tsToSet, timers.WithOutputTimestamp(outputTs))
fn.TimerTimerstamp.Write(sp, tsToSet.UnixMilli())
return nil
}
func (fn *goodTimerOutputTimestampsFn[V]) OnTimer(sp state.Provider, tp timers.Provider, w beam.Window, key string, timer timers.Context, emit func(beam.EventTime, string)) error {
switch timer.Family {
case fn.OutputState.Family:
vs, _, err := fn.ElementBag.Read(sp)
if err != nil {
return err
}
for _, v := range vs {
// Output each element with their timestamp
emit(beam.EventTime(v.Timestamp), fmt.Sprintf("%v", v.Value))
}
fn.ElementBag.Clear(sp)
// Note that the timer has now fired.
fn.TimerTimerstamp.Clear(sp)
}
return nil
}
func AddTimedOutputBatching[V any](s beam.Scope, in beam.PCollection) beam.PCollection {
return beam.ParDo(s, &goodTimerOutputTimestampsFn[V]{
ElementBag: state.MakeBagState[element[V]]("elementBag"),
TimerTimerstamp: state.MakeValueState[int64]("timerTimestamp"),
MinTimestampInBag: state.MakeCombiningState[int64, int64, int64]("minTimestampInBag", func(a, b int64) int64 {
if a < b {
return a
}
return b
}),
OutputState: timers.InProcessingTime("outputState"),
}, in)
}11.4. 垃圾回收状态
需要对每个键状态进行垃圾回收,否则状态不断增长的规模可能会对性能产生负面影响。有两种常见的垃圾回收状态策略。
11.4.1. **使用窗口进行垃圾回收**
每个键的所有状态和计时器都限定在它所在的窗口中。这意味着根据输入元素的时间戳,ParDo 将看到状态的不同值,具体取决于该元素落入的窗口。此外,一旦输入水位超过窗口的结束时间,运行器应该回收该窗口的所有状态。(注意:如果为窗口设置了允许的延迟值为正值,则运行器必须等待水位超过窗口的结束时间加上允许的延迟,然后才能回收状态)。这可以用作垃圾回收策略。
例如,给定以下内容
PCollection<KV<String, ValueT>> perUser = readPerUser();
perUser.apply(Window.into(CalendarWindows.days(1)
.withTimeZone(DateTimeZone.forID("America/Los_Angeles"))));
.apply(ParDo.of(new DoFn<KV<String, ValueT>, OutputT>() {
@StateId("state") private final StateSpec<ValueState<Integer>> state = StateSpecs.value();
...
@ProcessElement public void process(@Timestamp Instant ts, @StateId("state") ValueState<Integer> state) {
// The state is scoped to a calendar day window. That means that if the input timestamp ts is after
// midnight PST, then a new copy of the state will be seen for the next day.
}
}));class StateDoFn(DoFn):
ALL_ELEMENTS = BagStateSpec('buffer', coders.VarIntCoder())
def process(self,
element_pair,
buffer = DoFn.StateParam(ALL_ELEMENTS)):
...
_ = (p | 'Read per user' >> ReadPerUser()
| 'Windowing' >> beam.WindowInto(FixedWindows(60 * 60 * 24))
| 'DoFn' >> beam.ParDo(StateDoFn())) items := beam.ParDo(s, statefulDoFn{
S: state.MakeValueState[int]("S"),
}, elements)
out := beam.WindowInto(s, window.NewFixedWindows(24*time.Hour), items)此ParDo按天存储状态。一旦管道完成了对给定日期数据的处理,所有该日期的状态都将被回收。
11.4.1. **使用计时器进行垃圾回收**
在某些情况下,很难找到一个窗口化策略来模拟所需的垃圾回收策略。例如,一个常见的需求是在某个键上没有看到活动一段时间后,回收该键的状态。这可以通过更新回收状态的计时器来实现。例如
PCollection<KV<String, ValueT>> perUser = readPerUser();
perUser.apply(ParDo.of(new DoFn<KV<String, ValueT>, OutputT>() {
// The state for the key.
@StateId("state") private final StateSpec<ValueState<ValueT>> state = StateSpecs.value();
// The maximum element timestamp seen so far.
@StateId("maxTimestampSeen") private final StateSpec<CombiningState<Long, long[], Long>>
maxTimestamp = StateSpecs.combining(Max.ofLongs());
@TimerId("gcTimer") private final TimerSpec gcTimer = TimerSpecs.timer(TimeDomain.EVENT_TIME);
@ProcessElement public void process(
@Element KV<String, ValueT> element,
@Timestamp Instant ts,
@StateId("state") ValueState<ValueT> state,
@StateId("maxTimestampSeen") CombiningState<Long, long[], Long> maxTimestamp,
@TimerId("gcTimer") gcTimer) {
updateState(state, element);
maxTimestamp.add(ts.getMillis());
// Set the timer to be one hour after the maximum timestamp seen. This will keep overwriting the same timer, so
// as long as there is activity on this key the state will stay active. Once the key goes inactive for one hour's
// worth of event time (as measured by the watermark), then the gc timer will fire.
Instant expirationTime = new Instant(maxTimestamp.read()).plus(Duration.standardHours(1));
timer.set(expirationTime);
}
@OnTimer("gcTimer") public void onTimer(
@StateId("state") ValueState<ValueT> state,
@StateId("maxTimestampSeen") CombiningState<Long, long[], Long> maxTimestamp) {
// Clear all state for the key.
state.clear();
maxTimestamp.clear();
}
}class UserDoFn(DoFn):
ALL_ELEMENTS = BagStateSpec('state', coders.VarIntCoder())
MAX_TIMESTAMP = CombiningValueStateSpec('max_timestamp_seen', max)
TIMER = TimerSpec('gc-timer', TimeDomain.WATERMARK)
def process(self,
element,
t = DoFn.TimestampParam,
state = DoFn.StateParam(ALL_ELEMENTS),
max_timestamp = DoFn.StateParam(MAX_TIMESTAMP),
timer = DoFn.TimerParam(TIMER)):
update_state(state, element)
max_timestamp.add(t.micros)
# Set the timer to be one hour after the maximum timestamp seen. This will keep overwriting the same timer, so
# as long as there is activity on this key the state will stay active. Once the key goes inactive for one hour's
# worth of event time (as measured by the watermark), then the gc timer will fire.
expiration_time = Timestamp(micros=max_timestamp.read()) + Duration(seconds=60*60)
timer.set(expiration_time)
@on_timer(TIMER)
def expiry_callback(self,
state = DoFn.StateParam(ALL_ELEMENTS),
max_timestamp = DoFn.StateParam(MAX_TIMESTAMP)):
state.clear()
max_timestamp.clear()
_ = (p | 'Read per user' >> ReadPerUser()
| 'User DoFn' >> beam.ParDo(UserDoFn()))type timerGarbageCollectionFn[V any] struct {
State state.Value[V] // The state for the key.
MaxTimestampInBag state.Combining[int64, int64, int64] // The maximum element timestamp seen so far.
GcTimer timers.EventTime // The timestamp of the timer.
}
func (fn *timerGarbageCollectionFn[V]) ProcessElement(et beam.EventTime, sp state.Provider, tp timers.Provider, key string, value V, emit func(beam.EventTime, string)) {
updateState(sp, fn.State, key, value)
fn.MaxTimestampInBag.Add(sp, et.Milliseconds())
// Set the timer to be one hour after the maximum timestamp seen. This will keep overwriting the same timer, so
// as long as there is activity on this key the state will stay active. Once the key goes inactive for one hour's
// worth of event time (as measured by the watermark), then the gc timer will fire.
maxTs, _, _ := fn.MaxTimestampInBag.Read(sp)
expirationTime := time.UnixMilli(maxTs).Add(1 * time.Hour)
fn.GcTimer.Set(tp, expirationTime)
}
func (fn *timerGarbageCollectionFn[V]) OnTimer(sp state.Provider, tp timers.Provider, w beam.Window, key string, timer timers.Context, emit func(beam.EventTime, string)) {
switch timer.Family {
case fn.GcTimer.Family:
// Clear all the state for the key
fn.State.Clear(sp)
fn.MaxTimestampInBag.Clear(sp)
}
}
func AddTimerGarbageCollection[V any](s beam.Scope, in beam.PCollection) beam.PCollection {
return beam.ParDo(s, &timerGarbageCollectionFn[V]{
State: state.MakeValueState[V]("timerTimestamp"),
MaxTimestampInBag: state.MakeCombiningState[int64, int64, int64]("maxTimestampInBag", func(a, b int64) int64 {
if a > b {
return a
}
return b
}),
GcTimer: timers.InEventTime("gcTimer"),
}, in)
}11.5. 状态和计时器示例
以下是状态和计时器的一些示例用途
11.5.1. 连接点击和浏览量
在这个例子中,管道正在处理来自电子商务网站首页的数据。有两个输入流:一个表示在首页向用户显示的建议产品链接的查看流,另一个表示用户实际点击这些链接的点击流。管道的目标是将点击事件与查看事件连接起来,输出包含来自两个事件的信息的新连接事件。每个链接都有一个唯一的标识符,该标识符同时出现在查看事件和连接事件中。
许多查看事件永远不会被点击事件跟进。此管道将等待一个小时以进行点击,之后它将放弃此连接。虽然每个点击事件都应该有一个查看事件,但一小部分查看事件可能会丢失,并且永远无法进入 Beam 管道;管道将类似地在看到点击事件后等待一个小时,如果在该时间内没有收到查看事件,则放弃。输入事件没有排序 - 有可能在查看事件之前看到点击事件。一个小时的连接超时应该基于事件时间,而不是处理时间。
// Read the event stream and key it by the link id.
PCollection<KV<String, Event>> eventsPerLinkId =
readEvents()
.apply(WithKeys.of(Event::getLinkId).withKeyType(TypeDescriptors.strings()));
eventsPerLinkId.apply(ParDo.of(new DoFn<KV<String, Event>, JoinedEvent>() {
// Store the view event.
@StateId("view") private final StateSpec<ValueState<Event>> viewState = StateSpecs.value();
// Store the click event.
@StateId("click") private final StateSpec<ValueState<Event>> clickState = StateSpecs.value();
// The maximum element timestamp seen so far.
@StateId("maxTimestampSeen") private final StateSpec<CombiningState<Long, long[], Long>>
maxTimestamp = StateSpecs.combining(Max.ofLongs());
// Timer that fires when an hour goes by with an incomplete join.
@TimerId("gcTimer") private final TimerSpec gcTimer = TimerSpecs.timer(TimeDomain.EVENT_TIME);
@ProcessElement public void process(
@Element KV<String, Event> element,
@Timestamp Instant ts,
@AlwaysFetched @StateId("view") ValueState<Event> viewState,
@AlwaysFetched @StateId("click") ValueState<Event> clickState,
@AlwaysFetched @StateId("maxTimestampSeen") CombiningState<Long, long[], Long> maxTimestampState,
@TimerId("gcTimer") gcTimer,
OutputReceiver<JoinedEvent> output) {
// Store the event into the correct state variable.
Event event = element.getValue();
ValueState<Event> valueState = event.getType().equals(VIEW) ? viewState : clickState;
valueState.write(event);
Event view = viewState.read();
Event click = clickState.read();
(if view != null && click != null) {
// We've seen both a view and a click. Output a joined event and clear state.
output.output(JoinedEvent.of(view, click));
clearState(viewState, clickState, maxTimestampState);
} else {
// We've only seen on half of the join.
// Set the timer to be one hour after the maximum timestamp seen. This will keep overwriting the same timer, so
// as long as there is activity on this key the state will stay active. Once the key goes inactive for one hour's
// worth of event time (as measured by the watermark), then the gc timer will fire.
maxTimestampState.add(ts.getMillis());
Instant expirationTime = new Instant(maxTimestampState.read()).plus(Duration.standardHours(1));
gcTimer.set(expirationTime);
}
}
@OnTimer("gcTimer") public void onTimer(
@StateId("view") ValueState<Event> viewState,
@StateId("click") ValueState<Event> clickState,
@StateId("maxTimestampSeen") CombiningState<Long, long[], Long> maxTimestampState) {
// An hour has gone by with an incomplete join. Give up and clear the state.
clearState(viewState, clickState, maxTimestampState);
}
private void clearState(
@StateId("view") ValueState<Event> viewState,
@StateId("click") ValueState<Event> clickState,
@StateId("maxTimestampSeen") CombiningState<Long, long[], Long> maxTimestampState) {
viewState.clear();
clickState.clear();
maxTimestampState.clear();
}
}));class JoinDoFn(DoFn):
# stores the view event.
VIEW_STATE_SPEC = ReadModifyWriteStateSpec('view', EventCoder())
# stores the click event.
CLICK_STATE_SPEC = ReadModifyWriteStateSpec('click', EventCoder())
# The maximum element timestamp value seen so far.
MAX_TIMESTAMP = CombiningValueStateSpec('max_timestamp_seen', max)
# Timer that fires when an hour goes by with an incomplete join.
GC_TIMER = TimerSpec('gc', TimeDomain.WATERMARK)
def process(self,
element,
view=DoFn.StateParam(VIEW_STATE_SPEC),
click=DoFn.StateParam(CLICK_STATE_SPEC),
max_timestamp_seen=DoFn.StateParam(MAX_TIMESTAMP),
ts=DoFn.TimestampParam,
gc=DoFn.TimerParam(GC_TIMER)):
event = element
if event.type == 'view':
view.write(event)
else:
click.write(event)
previous_view = view.read()
previous_click = click.read()
# We've seen both a view and a click. Output a joined event and clear state.
if previous_view and previous_click:
yield (previous_view, previous_click)
view.clear()
click.clear()
max_timestamp_seen.clear()
else:
max_timestamp_seen.add(ts)
gc.set(max_timestamp_seen.read() + Duration(seconds=3600))
@on_timer(GC_TIMER)
def gc_callback(self,
view=DoFn.StateParam(VIEW_STATE_SPEC),
click=DoFn.StateParam(CLICK_STATE_SPEC),
max_timestamp_seen=DoFn.StateParam(MAX_TIMESTAMP)):
view.clear()
click.clear()
max_timestamp_seen.clear()
_ = (p | 'EventsPerLinkId' >> ReadPerLinkEvents()
| 'Join DoFn' >> beam.ParDo(JoinDoFn()))type JoinedEvent struct {
View, Click *Event
}
type joinDoFn struct {
View state.Value[*Event] // Store the view event.
Click state.Value[*Event] // Store the click event.
MaxTimestampSeen state.Combining[int64, int64, int64] // The maximum element timestamp seen so far.
GcTimer timers.EventTime // The timestamp of the timer.
}
func (fn *joinDoFn) ProcessElement(et beam.EventTime, sp state.Provider, tp timers.Provider, key string, event *Event, emit func(JoinedEvent)) {
valueState := fn.View
if event.isClick() {
valueState = fn.Click
}
valueState.Write(sp, event)
view, _, _ := fn.View.Read(sp)
click, _, _ := fn.Click.Read(sp)
if view != nil && click != nil {
emit(JoinedEvent{View: view, Click: click})
fn.clearState(sp)
return
}
fn.MaxTimestampSeen.Add(sp, et.Milliseconds())
expTs, _, _ := fn.MaxTimestampSeen.Read(sp)
fn.GcTimer.Set(tp, time.UnixMilli(expTs).Add(1*time.Hour))
}
func (fn *joinDoFn) OnTimer(sp state.Provider, tp timers.Provider, w beam.Window, key string, timer timers.Context, emit func(beam.EventTime, string)) {
switch timer.Family {
case fn.GcTimer.Family:
fn.clearState(sp)
}
}
func (fn *joinDoFn) clearState(sp state.Provider) {
fn.View.Clear(sp)
fn.Click.Clear(sp)
fn.MaxTimestampSeen.Clear(sp)
}
func AddJoinDoFn(s beam.Scope, in beam.PCollection) beam.PCollection {
return beam.ParDo(s, &joinDoFn{
View: state.MakeValueState[*Event]("view"),
Click: state.MakeValueState[*Event]("click"),
MaxTimestampSeen: state.MakeCombiningState[int64, int64, int64]("maxTimestampSeen", func(a, b int64) int64 {
if a > b {
return a
}
return b
}),
GcTimer: timers.InEventTime("gcTimer"),
}, in)
}11.5.2. 批处理 RPC
在这个例子中,输入元素被转发到外部 RPC 服务。RPC 接受批处理请求 - 可以将同一个用户的多个事件批处理到一个 RPC 调用中。由于此 RPC 服务也施加速率限制,因此我们希望将十秒钟的事件批处理在一起,以减少调用次数。
PCollection<KV<String, ValueT>> perUser = readPerUser();
perUser.apply(ParDo.of(new DoFn<KV<String, ValueT>, OutputT>() {
// Store the elements buffered so far.
@StateId("state") private final StateSpec<BagState<ValueT>> elements = StateSpecs.bag();
// Keep track of whether a timer is currently set or not.
@StateId("isTimerSet") private final StateSpec<ValueState<Boolean>> isTimerSet = StateSpecs.value();
// The processing-time timer user to publish the RPC.
@TimerId("outputState") private final TimerSpec timer = TimerSpecs.timer(TimeDomain.PROCESSING_TIME);
@ProcessElement public void process(
@Element KV<String, ValueT> element,
@StateId("state") BagState<ValueT> elementsState,
@StateId("isTimerSet") ValueState<Boolean> isTimerSetState,
@TimerId("outputState") Timer timer) {
// Add the current element to the bag for this key.
state.add(element.getValue());
if (!MoreObjects.firstNonNull(isTimerSetState.read(), false)) {
// If there is no timer currently set, then set one to go off in 10 seconds.
timer.offset(Duration.standardSeconds(10)).setRelative();
isTimerSetState.write(true);
}
}
@OnTimer("outputState") public void onTimer(
@StateId("state") BagState<ValueT> elementsState,
@StateId("isTimerSet") ValueState<Boolean> isTimerSetState) {
// Send an RPC containing the batched elements and clear state.
sendRPC(elementsState.read());
elementsState.clear();
isTimerSetState.clear();
}
}));class BufferDoFn(DoFn):
BUFFER = BagStateSpec('buffer', EventCoder())
IS_TIMER_SET = ReadModifyWriteStateSpec('is_timer_set', BooleanCoder())
OUTPUT = TimerSpec('output', TimeDomain.REAL_TIME)
def process(self,
buffer=DoFn.StateParam(BUFFER),
is_timer_set=DoFn.StateParam(IS_TIMER_SET),
timer=DoFn.TimerParam(OUTPUT)):
buffer.add(element)
if not is_timer_set.read():
timer.set(Timestamp.now() + Duration(seconds=10))
is_timer_set.write(True)
@on_timer(OUTPUT)
def output_callback(self,
buffer=DoFn.StateParam(BUFFER),
is_timer_set=DoFn.StateParam(IS_TIMER_SET)):
send_rpc(list(buffer.read()))
buffer.clear()
is_timer_set.clear()type bufferDoFn[V any] struct {
Elements state.Bag[V] // Store the elements buffered so far.
IsTimerSet state.Value[bool] // Keep track of whether a timer is currently set or not.
OutputElements timers.ProcessingTime // The processing-time timer user to publish the RPC.
}
func (fn *bufferDoFn[V]) ProcessElement(et beam.EventTime, sp state.Provider, tp timers.Provider, key string, value V) {
fn.Elements.Add(sp, value)
isSet, _, _ := fn.IsTimerSet.Read(sp)
if !isSet {
fn.OutputElements.Set(tp, time.Now().Add(10*time.Second))
fn.IsTimerSet.Write(sp, true)
}
}
func (fn *bufferDoFn[V]) OnTimer(sp state.Provider, tp timers.Provider, w beam.Window, key string, timer timers.Context) {
switch timer.Family {
case fn.OutputElements.Family:
elements, _, _ := fn.Elements.Read(sp)
sendRpc(elements)
fn.Elements.Clear(sp)
fn.IsTimerSet.Clear(sp)
}
}
func AddBufferDoFn[V any](s beam.Scope, in beam.PCollection) beam.PCollection {
return beam.ParDo(s, &bufferDoFn[V]{
Elements: state.MakeBagState[V]("elements"),
IsTimerSet: state.MakeValueState[bool]("isTimerSet"),
OutputElements: timers.InProcessingTime("outputElements"),
}, in)
}12. 可拆分 DoFns
可拆分的DoFn (SDF) 使用户能够创建包含 I/O(以及一些高级 非 I/O 用例)的模块化组件。拥有可以相互连接的模块化 I/O 组件简化了用户想要使用的典型模式。例如,一个流行的用例是从消息队列读取文件名,然后解析这些文件。传统上,用户需要要么编写一个包含消息队列和文件读取器逻辑的单个 I/O 连接器(增加了复杂性),要么选择重用消息队列 I/O,然后使用一个读取文件的普通DoFn(降低了性能)。使用 SDF,我们将 Apache Beam 的 I/O API 的丰富功能引入到DoFn中,从而在保持传统 I/O 连接器性能的同时实现模块化。
12.1. SDF 基础
从高层次来看,SDF 负责处理元素和限制对。限制表示在处理元素时必须完成的工作的一部分。
执行 SDF 遵循以下步骤
- 每个元素都与一个限制配对(例如,文件名与表示整个文件的偏移量范围配对)。
- 每个元素和限制对都被拆分(例如,偏移量范围被分成更小的部分)。
- 运行器将元素和限制对重新分配给多个工作器。
- 元素和限制对并行处理(例如,读取文件)。在最后一步中,元素和限制对可以暂停自己的处理,或者被进一步拆分成元素和限制对。

12.1.1. 基本 SDF
一个基本的 SDF 由三个部分组成:限制、限制提供者和限制跟踪器。如果您想控制水位,特别是在流式管道中,还需要另外两个组件:水位估计器提供者和水位估计器。
限制是用户定义的对象,用于表示给定元素的工作子集。例如,我们将OffsetRange定义为限制,以表示 Java 和 Python 中的偏移位置。
限制提供者允许 SDF 作者覆盖默认实现,包括用于拆分和调整大小的实现。在 Java 和 Go 中,它是DoFn。 Python 有一个专门的RestrictionProvider类型。
限制跟踪器负责跟踪在处理过程中限制的哪个子集已完成。有关 API 详细信息,请阅读 Java 和 Python 参考文档。
在 Java 中定义了一些内置的RestrictionTracker实现
SDF 在 Python 中也有一个内置的RestrictionTracker实现
Go 也有一个内置的RestrictionTracker类型
水位状态是用户定义的对象,用于从WatermarkEstimatorProvider创建WatermarkEstimator。最简单的水位状态可以是timestamp。
水位估计器提供者允许 SDF 作者定义如何初始化水位状态并创建水位估计器。在 Java 和 Go 中,它是DoFn。 Python 有一个专门的WatermarkEstimatorProvider类型。
水位估计器在元素-限制对正在处理时跟踪水位。有关 API 详细信息,请阅读 Java、Python 和 Go 参考文档。
在 Java 中定义了一些内置的WatermarkEstimator实现
除了默认的WatermarkEstimatorProvider之外,Python 中还具有相同的一组内置的WatermarkEstimator实现
以下WatermarkEstimator类型在 Go 中实现
要定义一个 SDF,您必须选择 SDF 是有界的(默认)还是无界的,并定义一种方法来为元素初始化初始限制。区别在于如何表示工作量
- 有界 DoFn 是指那些事先已知并且有结束的工作量由元素表示的 DoFn。有界元素的示例包括文件或文件组。
- 无界 DoFn 是指那些工作量没有特定结束时间或工作量事先未知的 DoFn。无界元素的示例包括 Kafka 或 PubSub 主题。
在 Java 中,您可以使用 @UnboundedPerElement 或 @BoundedPerElement 来注释您的DoFn。在 Python 中,您可以使用 @unbounded_per_element 来注释DoFn。
@BoundedPerElement
private static class FileToWordsFn extends DoFn<String, Integer> {
@GetInitialRestriction
public OffsetRange getInitialRestriction(@Element String fileName) throws IOException {
return new OffsetRange(0, new File(fileName).length());
}
@ProcessElement
public void processElement(
@Element String fileName,
RestrictionTracker<OffsetRange, Long> tracker,
OutputReceiver<Integer> outputReceiver)
throws IOException {
RandomAccessFile file = new RandomAccessFile(fileName, "r");
seekToNextRecordBoundaryInFile(file, tracker.currentRestriction().getFrom());
while (tracker.tryClaim(file.getFilePointer())) {
outputReceiver.output(readNextRecord(file));
}
}
// Providing the coder is only necessary if it can not be inferred at runtime.
@GetRestrictionCoder
public Coder<OffsetRange> getRestrictionCoder() {
return OffsetRange.Coder.of();
}
}class FileToWordsRestrictionProvider(beam.transforms.core.RestrictionProvider
):
def initial_restriction(self, file_name):
return OffsetRange(0, os.stat(file_name).st_size)
def create_tracker(self, restriction):
return beam.io.restriction_trackers.OffsetRestrictionTracker()
class FileToWordsFn(beam.DoFn):
def process(
self,
file_name,
# Alternatively, we can let FileToWordsFn itself inherit from
# RestrictionProvider, implement the required methods and let
# tracker=beam.DoFn.RestrictionParam() which will use self as
# the provider.
tracker=beam.DoFn.RestrictionParam(FileToWordsRestrictionProvider())):
with open(file_name) as file_handle:
file_handle.seek(tracker.current_restriction.start())
while tracker.try_claim(file_handle.tell()):
yield read_next_record(file_handle)
# Providing the coder is only necessary if it can not be inferred at
# runtime.
def restriction_coder(self):
return ...func (fn *splittableDoFn) CreateInitialRestriction(filename string) offsetrange.Restriction {
return offsetrange.Restriction{
Start: 0,
End: getFileLength(filename),
}
}
func (fn *splittableDoFn) CreateTracker(rest offsetrange.Restriction) *sdf.LockRTracker {
return sdf.NewLockRTracker(offsetrange.NewTracker(rest))
}
func (fn *splittableDoFn) ProcessElement(rt *sdf.LockRTracker, filename string, emit func(int)) error {
file, err := os.Open(filename)
if err != nil {
return err
}
offset, err := seekToNextRecordBoundaryInFile(file, rt.GetRestriction().(offsetrange.Restriction).Start)
if err != nil {
return err
}
for rt.TryClaim(offset) {
record, newOffset := readNextRecord(file)
emit(record)
offset = newOffset
}
return nil
}此时,我们已经有了支持 运行器启动的拆分 的 SDF,从而实现了动态工作再平衡。为了提高初始工作并行化的速率,或者对于不支持运行器启动的拆分的那些运行器,我们建议提供一组初始拆分
void splitRestriction(
@Restriction OffsetRange restriction, OutputReceiver<OffsetRange> splitReceiver) {
long splitSize = 64 * (1 << 20);
long i = restriction.getFrom();
while (i < restriction.getTo() - splitSize) {
// Compute and output 64 MiB size ranges to process in parallel
long end = i + splitSize;
splitReceiver.output(new OffsetRange(i, end));
i = end;
}
// Output the last range
splitReceiver.output(new OffsetRange(i, restriction.getTo()));
}class FileToWordsRestrictionProvider(beam.transforms.core.RestrictionProvider
):
def split(self, file_name, restriction):
# Compute and output 64 MiB size ranges to process in parallel
split_size = 64 * (1 << 20)
i = restriction.start
while i < restriction.end - split_size:
yield OffsetRange(i, i + split_size)
i += split_size
yield OffsetRange(i, restriction.end)func (fn *splittableDoFn) SplitRestriction(filename string, rest offsetrange.Restriction) (splits []offsetrange.Restriction) {
size := 64 * (1 << 20)
i := rest.Start
for i < rest.End - size {
// Compute and output 64 MiB size ranges to process in parallel
end := i + size
splits = append(splits, offsetrange.Restriction{i, end})
i = end
}
// Output the last range
splits = append(splits, offsetrange.Restriction{i, rest.End})
return splits
}12.2. 大小和进度
在执行 SDF 时,大小和进度用于告知运行器,以便它们可以做出明智的决定,例如应该拆分哪些限制以及如何并行化工作。
在处理元素和限制之前,运行器可以使用初始大小来选择如何以及由谁处理限制,从而尝试提高工作的初始平衡和并行化。在处理元素和限制期间,大小和进度用于选择要拆分的限制以及谁应该处理它们。
默认情况下,我们使用限制跟踪器对剩余工作的估计,回退到假设所有限制具有相等的成本。要覆盖默认设置,SDF 作者可以在限制提供程序中提供适当的方法。SDF 作者需要知道,由于运行器发起的拆分和进度估计,大小调整方法将在捆绑处理期间并发调用。
@GetSize
double getSize(@Element String fileName, @Restriction OffsetRange restriction) {
return (fileName.contains("expensiveRecords") ? 2 : 1) * restriction.getTo()
- restriction.getFrom();
}# The RestrictionProvider is responsible for calculating the size of given
# restriction.
class MyRestrictionProvider(beam.transforms.core.RestrictionProvider):
def restriction_size(self, file_name, restriction):
weight = 2 if "expensiveRecords" in file_name else 1
return restriction.size() * weightfunc (fn *splittableDoFn) RestrictionSize(filename string, rest offsetrange.Restriction) float64 {
weight := float64(1)
if strings.Contains(filename, “expensiveRecords”) {
weight = 2
}
return weight * (rest.End - rest.Start)
}12.3. 用户发起的检查点
某些 I/O 无法在单个捆绑的生命周期内生成完成限制所需的所有数据。这通常发生在无界限制中,但也可能发生在有界限制中。例如,可能还有更多需要摄取但尚未可用的数据。导致这种情况的另一个原因是源系统限制了您的数据。
您的 SDF 可以向您发出信号,表明您尚未完成当前限制的处理。此信号可以建议一个恢复时间。虽然运行器会尝试遵守恢复时间,但这不能保证。这允许执行继续在具有可用工作的限制上进行,从而提高资源利用率。
@ProcessElement
public ProcessContinuation processElement(
RestrictionTracker<OffsetRange, Long> tracker,
OutputReceiver<RecordPosition> outputReceiver) {
long currentPosition = tracker.currentRestriction().getFrom();
Service service = initializeService();
try {
while (true) {
List<RecordPosition> records = service.readNextRecords(currentPosition);
if (records.isEmpty()) {
// Return a short delay if there is no data to process at the moment.
return ProcessContinuation.resume().withResumeDelay(Duration.standardSeconds(10));
}
for (RecordPosition record : records) {
if (!tracker.tryClaim(record.getPosition())) {
return ProcessContinuation.stop();
}
currentPosition = record.getPosition() + 1;
outputReceiver.output(record);
}
}
} catch (ThrottlingException exception) {
// Return a longer delay in case we are being throttled.
return ProcessContinuation.resume().withResumeDelay(Duration.standardSeconds(60));
}
}class MySplittableDoFn(beam.DoFn):
def process(
self,
element,
restriction_tracker=beam.DoFn.RestrictionParam(
MyRestrictionProvider())):
current_position = restriction_tracker.current_restriction.start()
while True:
# Pull records from an external service.
try:
records = external_service.fetch(current_position)
if records.empty():
# Set a shorter delay in case we are being throttled.
restriction_tracker.defer_remainder(timestamp.Duration(second=10))
return
for record in records:
if restriction_tracker.try_claim(record.position):
current_position = record.position
yield record
else:
return
except TimeoutError:
# Set a longer delay in case we are being throttled.
restriction_tracker.defer_remainder(timestamp.Duration(seconds=60))
returnfunc (fn *checkpointingSplittableDoFn) ProcessElement(rt *sdf.LockRTracker, emit func(Record)) (sdf.ProcessContinuation, error) {
position := rt.GetRestriction().(offsetrange.Restriction).Start
for {
records, err := fn.ExternalService.readNextRecords(position)
if err != nil {
if err == fn.ExternalService.ThrottlingErr {
// Resume at a later time to avoid throttling.
return sdf.ResumeProcessingIn(60 * time.Second), nil
}
return sdf.StopProcessing(), err
}
if len(records) == 0 {
// Wait for data to be available.
return sdf.ResumeProcessingIn(10 * time.Second), nil
}
for _, record := range records {
if !rt.TryClaim(position) {
// Records have been claimed, finish processing.
return sdf.StopProcessing(), nil
}
position += 1
emit(record)
}
}
}12.4. 运行器发起的拆分
运行器随时可能尝试在处理限制时拆分限制。这允许运行器暂停限制的处理,以便可以执行其他工作(对于无界限制来说很常见,以限制输出量和/或提高延迟),或者将限制拆分为两部分,从而提高系统中的可用并行性。不同的运行器(例如,Dataflow、Flink、Spark)在批处理和流式执行下具有不同的策略来发出拆分。
在编写 SDF 时请牢记这一点,因为限制的结束可能会改变。在编写处理循环时,请使用尝试声明限制的一部分的结果,而不是假设您可以处理到结束。
一个不正确的例子可能是
@ProcessElement
public void badTryClaimLoop(
@Element String fileName,
RestrictionTracker<OffsetRange, Long> tracker,
OutputReceiver<Integer> outputReceiver)
throws IOException {
RandomAccessFile file = new RandomAccessFile(fileName, "r");
seekToNextRecordBoundaryInFile(file, tracker.currentRestriction().getFrom());
// The restriction tracker can be modified by another thread in parallel
// so storing state locally is ill advised.
long end = tracker.currentRestriction().getTo();
while (file.getFilePointer() < end) {
// Only after successfully claiming should we produce any output and/or
// perform side effects.
tracker.tryClaim(file.getFilePointer());
outputReceiver.output(readNextRecord(file));
}
}class BadTryClaimLoop(beam.DoFn):
def process(
self,
file_name,
tracker=beam.DoFn.RestrictionParam(FileToWordsRestrictionProvider())):
with open(file_name) as file_handle:
file_handle.seek(tracker.current_restriction.start())
# The restriction tracker can be modified by another thread in parallel
# so storing state locally is ill advised.
end = tracker.current_restriction.end()
while file_handle.tell() < end:
# Only after successfully claiming should we produce any output and/or
# perform side effects.
tracker.try_claim(file_handle.tell())
yield read_next_record(file_handle)func (fn *badTryClaimLoop) ProcessElement(rt *sdf.LockRTracker, filename string, emit func(int)) error {
file, err := os.Open(filename)
if err != nil {
return err
}
offset, err := seekToNextRecordBoundaryInFile(file, rt.GetRestriction().(offsetrange.Restriction).Start)
if err != nil {
return err
}
// The restriction tracker can be modified by another thread in parallel
// so storing state locally is ill advised.
end = rt.GetRestriction().(offsetrange.Restriction).End
for offset < end {
// Only after successfully claiming should we produce any output and/or
// perform side effects.
rt.TryClaim(offset)
record, newOffset := readNextRecord(file)
emit(record)
offset = newOffset
}
return nil
}12.5. 水印估计
默认水印估计器不会生成水印估计。因此,输出水印仅由上游水印的最小值计算得出。
SDF 可以通过指定此元素和限制对将要生成的所有未来输出的下限来推进输出水印。运行器通过对所有上游水印和每个元素和限制对报告的最小值取最小值来计算最小输出水印。报告的水印必须在捆绑边界之间对每个元素和限制对单调增加。当元素和限制对停止处理其水印时,它不再被视为上述计算的一部分。
提示
- 如果您编写了一个输出带时间戳的记录的 SDF,则应公开方法以允许此 SDF 的用户配置要使用哪个水印估计器。
- 在水印之前生成的所有数据都可能被视为延迟。有关更多详细信息,请参阅 水印和延迟数据。
12.5.1. 控制水印
水印估计器主要有两种类型:时间戳观察和外部时钟观察。时间戳观察水印估计器使用每个记录的输出时间戳来计算水印估计,而外部时钟观察水印估计器使用与任何单个输出无关的时钟来控制水印,例如机器的本地时钟或通过外部服务公开的时钟。
水印估计器提供程序允许您覆盖默认水印估计逻辑并使用现有的水印估计器实现。您也可以提供自己的水印估计器实现。
// (Optional) Define a custom watermark state type to save information between bundle
// processing rounds.
public static class MyCustomWatermarkState {
public MyCustomWatermarkState(String element, OffsetRange restriction) {
// Store data necessary for future watermark computations
}
}
// (Optional) Choose which coder to use to encode the watermark estimator state.
@GetWatermarkEstimatorStateCoder
public Coder<MyCustomWatermarkState> getWatermarkEstimatorStateCoder() {
return AvroCoder.of(MyCustomWatermarkState.class);
}
// Define a WatermarkEstimator
public static class MyCustomWatermarkEstimator
implements TimestampObservingWatermarkEstimator<MyCustomWatermarkState> {
public MyCustomWatermarkEstimator(MyCustomWatermarkState type) {
// Initialize watermark estimator state
}
@Override
public void observeTimestamp(Instant timestamp) {
// Will be invoked on each output from the SDF
}
@Override
public Instant currentWatermark() {
// Return a monotonically increasing value
return currentWatermark;
}
@Override
public MyCustomWatermarkState getState() {
// Return state to resume future watermark estimation after a checkpoint/split
return null;
}
}
// Then, update the DoFn to generate the initial watermark estimator state for all new element
// and restriction pairs and to create a new instance given watermark estimator state.
@GetInitialWatermarkEstimatorState
public MyCustomWatermarkState getInitialWatermarkEstimatorState(
@Element String element, @Restriction OffsetRange restriction) {
// Compute and return the initial watermark estimator state for each element and
// restriction. All subsequent processing of an element and restriction will be restored
// from the existing state.
return new MyCustomWatermarkState(element, restriction);
}
@NewWatermarkEstimator
public WatermarkEstimator<MyCustomWatermarkState> newWatermarkEstimator(
@WatermarkEstimatorState MyCustomWatermarkState oldState) {
return new MyCustomWatermarkEstimator(oldState);
}
}# (Optional) Define a custom watermark state type to save information between
# bundle processing rounds.
class MyCustomerWatermarkEstimatorState(object):
def __init__(self, element, restriction):
# Store data necessary for future watermark computations
pass
# Define a WatermarkEstimator
class MyCustomWatermarkEstimator(WatermarkEstimator):
def __init__(self, estimator_state):
self.state = estimator_state
def observe_timestamp(self, timestamp):
# Will be invoked on each output from the SDF
pass
def current_watermark(self):
# Return a monotonically increasing value
return current_watermark
def get_estimator_state(self):
# Return state to resume future watermark estimation after a
# checkpoint/split
return self.state
# Then, a WatermarkEstimatorProvider needs to be created for this
# WatermarkEstimator
class MyWatermarkEstimatorProvider(WatermarkEstimatorProvider):
def initial_estimator_state(self, element, restriction):
return MyCustomerWatermarkEstimatorState(element, restriction)
def create_watermark_estimator(self, estimator_state):
return MyCustomWatermarkEstimator(estimator_state)
# Finally, define the SDF using your estimator.
class MySplittableDoFn(beam.DoFn):
def process(
self,
element,
restriction_tracker=beam.DoFn.RestrictionParam(MyRestrictionProvider()),
watermark_estimator=beam.DoFn.WatermarkEstimatorParam(
MyWatermarkEstimatorProvider())):
# The current watermark can be inspected.
watermark_estimator.current_watermark()// WatermarkState is a custom type.`
//
// It is optional to write your own state type when making a custom estimator.
type WatermarkState struct {
Watermark time.Time
}
// CustomWatermarkEstimator is a custom watermark estimator.
// You may use any type here, including some of Beam's built in watermark estimator types,
// e.g. sdf.WallTimeWatermarkEstimator, sdf.TimestampObservingWatermarkEstimator, and sdf.ManualWatermarkEstimator
type CustomWatermarkEstimator struct {
state WatermarkState
}
// CurrentWatermark returns the current watermark and is invoked on DoFn splits and self-checkpoints.
// Watermark estimators must implement CurrentWatermark() time.Time
func (e *CustomWatermarkEstimator) CurrentWatermark() time.Time {
return e.state.Watermark
}
// ObserveTimestamp is called on the output timestamps of all
// emitted elements to update the watermark. It is optional
func (e *CustomWatermarkEstimator) ObserveTimestamp(ts time.Time) {
e.state.Watermark = ts
}
// InitialWatermarkEstimatorState defines an initial state used to initialize the watermark
// estimator. It is optional. If this is not defined, WatermarkEstimatorState may not be
// defined and CreateWatermarkEstimator must not take in parameters.
func (fn *weDoFn) InitialWatermarkEstimatorState(et beam.EventTime, rest offsetrange.Restriction, element string) WatermarkState {
// Return some watermark state
return WatermarkState{Watermark: time.Now()}
}
// CreateWatermarkEstimator creates the watermark estimator used by this Splittable DoFn.
// Must take in a state parameter if InitialWatermarkEstimatorState is defined, otherwise takes no parameters.
func (fn *weDoFn) CreateWatermarkEstimator(initialState WatermarkState) *CustomWatermarkEstimator {
return &CustomWatermarkEstimator{state: initialState}
}
// WatermarkEstimatorState returns the state used to resume future watermark estimation
// after a checkpoint/split. It is required if InitialWatermarkEstimatorState is defined,
// otherwise it must not be defined.
func (fn *weDoFn) WatermarkEstimatorState(e *CustomWatermarkEstimator) WatermarkState {
return e.state
}
// ProcessElement is the method to execute for each element.
// It can optionally take in a watermark estimator.
func (fn *weDoFn) ProcessElement(e *CustomWatermarkEstimator, element string) {
// ...
e.state.Watermark = time.Now()
}12.6. 在排空期间截断
支持清空管道运行器的运行器需要能够清空 SDF;否则,管道可能永远不会停止。默认情况下,有界限制会处理限制的剩余部分,而无界限制会在下一个 SDF 发起的检查点或运行器发起的拆分处完成处理。您可以通过在限制提供程序上定义适当的方法来覆盖此默认行为。
注意:一旦管道清空开始且截断限制转换被触发,sdf.ProcessContinuation 将不会重新调度。
@TruncateRestriction
@Nullable
TruncateResult<OffsetRange> truncateRestriction(
@Element String fileName, @Restriction OffsetRange restriction) {
if (fileName.contains("optional")) {
// Skip optional files
return null;
}
return TruncateResult.of(restriction);
}class MyRestrictionProvider(beam.transforms.core.RestrictionProvider):
def truncate(self, file_name, restriction):
if "optional" in file_name:
# Skip optional files
return None
return restriction// TruncateRestriction is a transform that is triggered when pipeline starts to drain. It helps to finish a
// pipeline quicker by truncating the restriction.
func (fn *splittableDoFn) TruncateRestriction(rt *sdf.LockRTracker, element string) offsetrange.Restriction {
start := rt.GetRestriction().(offsetrange.Restriction).Start
prevEnd := rt.GetRestriction().(offsetrange.Restriction).End
// truncate the restriction by half.
newEnd := prevEnd / 2
return offsetrange.Restriction{
Start: start,
End: newEnd,
}
}12.7. 捆绑最终化
捆绑最终化使 DoFn 能够通过注册回调来执行副作用。一旦运行器确认已持久保存输出,就会调用回调。例如,消息队列可能需要确认它已将消息摄取到管道中。捆绑最终化不仅限于 SDF,但在本文中有所提及,因为这是主要用例。
@ProcessElement
public void processElement(ProcessContext c, BundleFinalizer bundleFinalizer) {
// ... produce output ...
bundleFinalizer.afterBundleCommit(
Instant.now().plus(Duration.standardMinutes(5)),
() -> {
// ... perform a side effect ...
});
}class MySplittableDoFn(beam.DoFn):
def process(self, element, bundle_finalizer=beam.DoFn.BundleFinalizerParam):
# ... produce output ...
# Register callback function for this bundle that performs the side
# effect.
bundle_finalizer.register(my_callback_func)func (fn *splittableDoFn) ProcessElement(bf beam.BundleFinalization, rt *sdf.LockRTracker, element string) {
// ... produce output ...
bf.RegisterCallback(5*time.Minute, func() error {
// ... perform a side effect ...
return nil
})
}13. 多语言管道
本节提供了对多语言管道的全面文档。要开始创建多语言管道,请参阅
Beam 允许您组合用任何支持的 SDK 语言(目前是 Java 和 Python)编写的转换,并将它们用于一个多语言管道中。此功能使得通过单个跨语言转换,可以轻松地在不同的 Apache Beam SDK 中同时提供新功能。例如,Apache Kafka 连接器 和 SQL 转换 (来自 Java SDK) 可用于 Python 管道。
使用来自多个 SDK 语言的转换的管道被称为多语言管道。
Beam YAML 完全建立在跨语言转换之上。除了内置的转换之外,您还可以编写自己的转换(使用 Beam API 的全部表达能力),并通过一个称为 提供者 的概念将其公开。
13.1. 创建跨语言转换
为了使用一种语言编写的转换可用于用另一种语言编写的管道,Beam 使用扩展服务,该服务创建并将适当的语言特定管道片段注入到管道中。
在以下示例中,Beam Python 管道启动一个本地 Java 扩展服务,以创建并将适当的 Java 管道片段注入到 Python 管道中,以便执行 Java Kafka 跨语言转换。然后,SDK 将下载并存放执行这些转换所需的必要 Java 依赖项。

在运行时,Beam 运行器将执行 Python 和 Java 转换以运行管道。
在本节中,我们将使用 KafkaIO.Read 来说明如何为 Java 创建跨语言转换以及 Python 的测试示例。
13.1.1. 创建跨语言 Java 转换
有两种方法可以使 Java 转换可用于其他 SDK。
- 选项 1:在某些情况下,您可以在不编写任何其他 Java 代码的情况下使用其他 SDK 中现有的 Java 转换。
- 选项 2:您可以通过添加一些 Java 类来使用来自其他 SDK 的任意 Java 转换。
13.1.1.1 在不编写更多 Java 代码的情况下使用现有的 Java 转换
从 Beam 2.34.0 开始,Python SDK 用户可以使用一些 Java 转换,而无需编写额外的 Java 代码。这在许多情况下都很有用。例如
- 不熟悉 Java 的开发人员可能需要从 Python 管道中使用现有的 Java 转换。
- 开发人员可能需要使现有的 Java 转换可用于 Python 管道,而无需编写/发布更多 Java 代码。
注意:此功能目前仅在从 Python 管道中使用 Java 转换时可用。
为了符合直接使用的条件,Java 转换的 API 必须满足以下要求
- Java 转换可以使用可用的公共构造函数或同一个 Java 类中的公共静态方法(构造函数方法)来构建。
- Java 转换可以使用一个或多个构建器方法进行配置。每个构建器方法都应该是公共的,并且应该返回 Java 转换的实例。
以下是一个可以从 Python API 中直接使用的示例 Java 类。
public class JavaDataGenerator extends PTransform<PBegin, PCollection<String>> {
. . .
// The following method satisfies requirement 1.
// Note that you could use a class constructor instead of a static method.
public static JavaDataGenerator create(Integer size) {
return new JavaDataGenerator(size);
}
static class JavaDataGeneratorConfig implements Serializable {
public String prefix;
public long length;
public String suffix;
. . .
}
// The following method conforms to requirement 2.
public JavaDataGenerator withJavaDataGeneratorConfig(JavaDataGeneratorConfig dataConfig) {
return new JavaDataGenerator(this.size, javaDataGeneratorConfig);
}
. . .
}
有关完整示例,请参阅 JavaDataGenerator。
要从 Python SDK 管道中使用符合上述要求的 Java 类,请执行以下步骤
- 创建一个yaml 允许列表,该列表描述了将从 Python 中直接访问的 Java 转换类和方法。
- 使用
javaClassLookupAllowlistFile选项传递允许列表的路径来启动扩展服务。 - 使用 Python JavaExternalTransform API 从 Python 端直接访问允许列表中定义的 Java 转换。
从 Beam 2.36.0 开始,可以跳过步骤 1 和 2,如下面的相应部分所述。
步骤 1
要从 Python 中使用合格的 Java 转换,请定义一个yaml 允许列表。此允许列表列出了从 Python 端直接使用的类名、构造函数方法和构建器方法。
从 Beam 2.35.0 开始,您可以选择将 * 传递给 javaClassLookupAllowlistFile 选项,而不是定义实际的允许列表。* 指定类路径中所有支持的转换都可以通过 API 访问。我们建议在生产环境中使用实际的允许列表,因为允许客户端访问任意 Java 类会带来安全风险。
version: v1
allowedClasses:
- className: my.beam.transforms.JavaDataGenerator
allowedConstructorMethods:
- create
allowedBuilderMethods:
- withJavaDataGeneratorConfig步骤 2
在启动 Java 扩展服务时,将允许列表作为参数提供。例如,您可以使用以下命令将扩展服务启动为本地 Java 进程
java -jar <jar file> <port> --javaClassLookupAllowlistFile=<path to the allowlist file>从 Beam 2.36.0 开始,如果未提供扩展服务地址,JavaExternalTransform API 将自动启动具有给定 jar 文件依赖项的扩展服务。
步骤 3
您可以使用从 JavaExternalTransform API 创建的存根转换,从您的 Python 管道中直接使用 Java 类。此 API 允许您使用 Java 类名构建转换,并允许您调用构建器方法来配置类。
构造函数和方法参数类型使用 Beam 模式在 Python 和 Java 之间映射。使用 Python 端提供的对象类型自动生成模式。如果 Java 类构造函数方法或构建器方法接受任何复杂的对象类型,请确保这些对象的 Beam 模式已注册并可用于 Java 扩展服务。如果模式尚未注册,Java 扩展服务将尝试使用 JavaFieldSchema 注册模式。在 Python 中,可以使用 NamedTuple 表示任意对象,这些对象将在模式中表示为 Beam 行。以下是一个 Python 存根转换,它代表上述 Java 转换
JavaDataGeneratorConfig = typing.NamedTuple(
'JavaDataGeneratorConfig', [('prefix', str), ('length', int), ('suffix', str)])
data_config = JavaDataGeneratorConfig(prefix='start', length=20, suffix='end')
java_transform = JavaExternalTransform(
'my.beam.transforms.JavaDataGenerator', expansion_service='localhost:<port>').create(numpy.int32(100)).withJavaDataGeneratorConfig(data_config)
您可以在 Python 管道中使用此转换以及其他 Python 转换。有关完整示例,请参阅 javadatagenerator.py。
13.1.1.2 使用 API 使现有的 Java 转换可用于其他 SDK
要使您的 Beam Java SDK 转换可移植到跨 SDK 语言,您必须实现两个接口:ExternalTransformBuilder 和 ExternalTransformRegistrar。ExternalTransformBuilder 接口使用从管道传递的配置值构建跨语言转换,而 ExternalTransformRegistrar 接口注册跨语言转换以供扩展服务使用。
实现接口
为您的转换定义一个 Builder 类,该类实现
ExternalTransformBuilder接口并覆盖buildExternal方法,该方法将用于构建您的转换对象。您的转换的初始配置值应该在buildExternal方法中定义。在大多数情况下,让 Java 转换构建器类实现ExternalTransformBuilder很方便。注意:
ExternalTransformBuilder要求您定义一个配置对象(一个简单的POJO)来捕获外部SDK发送的一组参数,以启动Java转换。 通常,这些参数直接映射到Java转换的构造函数参数。@AutoValue.Builder abstract static class Builder<K, V> implements ExternalTransformBuilder<External.Configuration, PBegin, PCollection<KV<K, V>>> { abstract Builder<K, V> setConsumerConfig(Map<String, Object> config); abstract Builder<K, V> setTopics(List<String> topics); /** Remaining property declarations omitted for clarity. */ abstract Read<K, V> build(); @Override public PTransform<PBegin, PCollection<KV<K, V>>> buildExternal( External.Configuration config) { setTopics(ImmutableList.copyOf(config.topics)); /** Remaining property defaults omitted for clarity. */ } }有关完整示例,请参见JavaCountBuilder和JavaPrefixBuilder。
请注意,
buildExternal方法可以在将外部SDK接收到的属性设置到转换中之前执行其他操作。 例如,buildExternal可以在将属性设置到转换中之前验证配置对象中可用的属性。通过定义一个实现
ExternalTransformRegistrar的类,将转换注册为外部跨语言转换。 您必须使用AutoService注释注释您的类,以确保您的转换由扩展服务正确注册和实例化。在您的注册器类中,为您的转换定义一个统一资源名称 (URN)。 URN必须是唯一标识您与扩展服务之间的转换的字符串。
从您的注册器类中,为外部SDK在初始化您的转换期间使用的参数定义一个配置类。
以下来自KafkaIO转换的示例展示了如何实现步骤二到四
@AutoService(ExternalTransformRegistrar.class) public static class External implements ExternalTransformRegistrar { public static final String URN = "beam:external:java:kafka:read:v1"; @Override public Map<String, Class<? extends ExternalTransformBuilder<?, ?, ?>>> knownBuilders() { return ImmutableMap.of( URN, (Class<? extends ExternalTransformBuilder<?, ?, ?>>) (Class<?>) AutoValue_KafkaIO_Read.Builder.class); } /** Parameters class to expose the Read transform to an external SDK. */ public static class Configuration { private Map<String, String> consumerConfig; private List<String> topics; public void setConsumerConfig(Map<String, String> consumerConfig) { this.consumerConfig = consumerConfig; } public void setTopics(List<String> topics) { this.topics = topics; } /** Remaining properties omitted for clarity. */ } }有关其他示例,请参见JavaCountRegistrar和JavaPrefixRegistrar。
在您实现ExternalTransformBuilder和ExternalTransformRegistrar接口后,您的转换可以由默认的Java扩展服务成功注册和创建。
启动扩展服务
您可以在同一个管道中使用多个转换的扩展服务。 Beam Java SDK为Java转换提供默认的扩展服务。 您也可以编写自己的扩展服务,但这通常是不必要的,因此本节不介绍它。
执行以下操作以直接启动Java扩展服务
# Build a JAR with both your transform and the expansion service
# Start the expansion service at the specified port.
$ jar -jar /path/to/expansion_service.jar <PORT_NUMBER>扩展服务现在已准备好为指定端口上的转换提供服务。
在为您的转换创建SDK特定的包装器时,您可能可以使用SDK提供的实用程序来启动扩展服务。 例如,Python SDK提供了实用程序JavaJarExpansionService和BeamJarExpansionService,用于使用JAR文件启动Java扩展服务。
包含依赖项
如果您的转换需要外部库,您可以通过将它们添加到扩展服务的类路径中来包含它们。 它们包含在类路径中后,将在扩展服务扩展您的转换时进行分段。
编写SDK特定的包装器
您的跨语言Java转换可以通过更低级别的ExternalTransform类在多语言管道中调用(如下一节所述); 但是,如果可能,您应该在管道语言(例如Python)中编写一个SDK特定的包装器来访问转换。 这种更高级别的抽象将使管道作者更容易使用您的转换。
要创建用于Python管道中的SDK包装器,请执行以下操作
为您的跨语言转换创建Python模块。
在模块中,使用
PayloadBuilder类之一来构建初始跨语言转换扩展请求的有效负载。有效负载的参数名称和类型应该映射到提供给Java
ExternalTransformBuilder的配置POJO的参数名称和类型。 参数类型使用Beam模式跨SDK映射。 参数名称通过简单地将Python下划线分隔的变量名称转换为驼峰式(Java标准)来映射。在以下示例中,kafka.py使用
NamedTupleBasedPayloadBuilder来构建有效负载。 参数映射到Java KafkaIO.External.Configuration配置对象(如上一节所述)。class ReadFromKafkaSchema(typing.NamedTuple): consumer_config: typing.Mapping[str, str] topics: typing.List[str] # Other properties omitted for clarity. payload = NamedTupleBasedPayloadBuilder(ReadFromKafkaSchema(...))启动扩展服务,除非由管道创建者指定。 Beam Python SDK提供了实用程序
JavaJarExpansionService和BeamJarExpansionService,用于使用JAR文件启动扩展服务。JavaJarExpansionService可用于使用给定JAR文件的路径(本地路径或URL)启动扩展服务。BeamJarExpansionService可用于从Beam发布的JAR启动扩展服务。对于与Beam一起发布的转换,请执行以下操作
向Beam添加一个Gradle目标,该目标可用于为目标Java转换构建一个阴影扩展服务JAR。 此目标应该生成一个包含扩展Java转换所需的所有依赖项的Beam JAR,并且该JAR应该与Beam一起发布。 您可能可以使用现有的Gradle目标,该目标提供扩展服务JAR的聚合版本(例如,适用于所有GCP IO)。
在您的Python模块中,使用Gradle目标实例化
BeamJarExpansionService。expansion_service = BeamJarExpansionService('sdks:java:io:expansion-service:shadowJar')
添加一个扩展
ExternalTransform的Python包装器转换类。 将上面定义的有效负载和扩展服务作为参数传递给ExternalTransform父类的构造函数。
13.1.2. 创建跨语言 Python 转换
在扩展服务范围内定义的任何Python转换都应该可以通过指定其完全限定名称来访问。 例如,您可以在Java管道中使用Python的ReadFromText转换及其完全限定名称apache_beam.io.ReadFromText
p.apply("Read",
PythonExternalTransform.<PBegin, PCollection<String>>from("apache_beam.io.ReadFromText")
.withKwarg("file_pattern", options.getInputFile())
.withKwarg("validate", false))
PythonExternalTransform还有其他有用的方法,例如用于分段PyPI包依赖项的withExtraPackages和用于设置输出编码器的withOutputCoder。 如果您的转换存在于外部包中,请确保使用withExtraPackages指定该包,例如
p.apply("Read",
PythonExternalTransform.<PBegin, PCollection<String>>from("my_python_package.BeamReadPTransform")
.withExtraPackages(ImmutableList.of("my_python_package")))
或者,您可能希望创建一个Python模块,该模块将现有的Python转换注册为跨语言转换,以便与Python扩展服务一起使用,并调用该现有转换以执行其预期操作。 注册的URN稍后可在扩展请求中使用,以指示扩展目标。
定义Python模块
为您的转换定义一个统一资源名称 (URN)。 URN必须是唯一标识您与扩展服务之间的转换的字符串。
TEST_COMPK_URN = "beam:transforms:xlang:test:compk"对于现有的Python转换,创建一个新类来将URN注册到Python扩展服务。
@ptransform.PTransform.register_urn(TEST_COMPK_URN, None) class CombinePerKeyTransform(ptransform.PTransform):从类中,定义一个expand方法,该方法接受一个输入PCollection,运行Python转换,然后返回输出PCollection。
def expand(self, pcoll): return pcoll \ | beam.CombinePerKey(sum).with_output_types( typing.Tuple[unicode, int])与其他Python转换一样,定义一个
to_runner_api_parameter方法,该方法返回URN。def to_runner_api_parameter(self, unused_context): return TEST_COMPK_URN, None定义一个静态
from_runner_api_parameter方法,该方法返回跨语言Python转换的实例。@staticmethod def from_runner_api_parameter( unused_ptransform, unused_parameter, unused_context): return CombinePerKeyTransform()
启动扩展服务
扩展服务可用于同一管道中的多个转换。 Beam Python SDK为您提供一个默认扩展服务,供您与您的Python转换一起使用。 您可以在编写自己的扩展服务,但这通常是不必要的,因此本节不介绍它。
执行以下步骤以直接启动默认的Python扩展服务
创建一个虚拟环境,并安装Apache Beam SDK。
使用指定的端口启动Python SDK的扩展服务。

$ export PORT_FOR_EXPANSION_SERVICE=12345导入任何包含要使用扩展服务提供的转换的模块。
$ python -m apache_beam.runners.portability.expansion_service_test -p $PORT_FOR_EXPANSION_SERVICE --pickle_library=cloudpickle此扩展服务现在已准备好为地址
localhost:$PORT_FOR_EXPANSION_SERVICE上的转换提供服务。
13.1.3. 创建跨语言 Go 转换
Go目前不支持创建跨语言转换,只支持使用来自其他语言的跨语言转换; 有关更多信息,请参见问题21767。
13.1.4. 定义 URN
开发跨语言转换涉及为转换定义一个URN,以便将其注册到扩展服务。在本节中,我们提供了一个定义此类URN的约定。遵循此约定是可选的,但它将确保您的转换在扩展服务中注册时,不会与其他开发人员开发的转换发生冲突。
13.1.4.1. 模式
URN应包含以下组件
- ns-id:命名空间标识符。默认建议是
beam:transform。 - org-identifier:标识定义转换的组织。在Apache Beam中定义的转换使用
org.apache.beam来标识。 - functionality-identifier:标识跨语言转换的功能。
- version:转换的版本号。
我们使用增强的巴克斯-诺尔形式提供URN约定中的模式。大写的关键字来自URN规范。
transform-urn = ns-id “:” org-identifier “:” functionality-identifier “:” version
ns-id = (“beam” / NID) “:” “transform”
id-char = ALPHA / DIGIT / "-" / "." / "_" / "~" ; A subset of characters allowed in a URN
org-identifier = 1*id-char
functionality-identifier = 1*id-char
version = “v” 1*(DIGIT / “.”) ; For example, ‘v1.2’13.1.4.2. 示例
下面我们给出了几个示例转换类及其相应的URN。
- Apache Beam提供的用于写入Parquet文件的转换。
beam:transform:org.apache.beam:parquet_write:v1
- Apache Beam提供的用于使用元数据从Kafka读取的转换。
beam:transform:org.apache.beam:kafka_read_with_metadata:v1
- 由组织abc.org开发的用于从数据存储MyDatastore读取的转换。
beam:transform:org.abc:mydatastore_read:v1
13.2. 使用跨语言转换
根据管道的SDK语言,您可以使用高级SDK包装器类或低级转换类来访问跨语言转换。
13.2.1. 在 Java 管道中使用跨语言转换
用户可以使用三种方法在Java管道中使用跨语言转换。在最高级别的抽象中,一些流行的Python转换可以通过专用的Java包装器转换访问。例如,Java SDK具有DataframeTransform类,该类使用Python SDK的DataframeTransform,它还有RunInference类,该类使用Python SDK的RunInference,等等。当目标Python转换没有SDK特定的包装器转换时,可以通过指定Python转换的完全限定名称来使用更低级别的PythonExternalTransform类。如果您想尝试来自除Python之外的SDK的外部转换(包括Java SDK本身),也可以使用最低级别的External类。
使用SDK包装器
要通过 SDK 包装器使用跨语言转换,请导入 SDK 包装器的模块并在您的管道中调用它,如示例所示。
import org.apache.beam.sdk.extensions.python.transforms.DataframeTransform;
input.apply(DataframeTransform.of("lambda df: df.groupby('a').sum()").withIndexes())
使用 PythonExternalTransform 类
如果不可用 SDK 特定的包装器,您可以通过指定目标 Python 转换的完全限定名称和构造函数参数,通过 PythonExternalTransform 类访问 Python 跨语言转换。
input.apply(
PythonExternalTransform.<PCollection<Row>, PCollection<Row>>from(
"apache_beam.dataframe.transforms.DataframeTransform")
.withKwarg("func", PythonCallableSource.of("lambda df: df.groupby('a').sum()"))
.withKwarg("include_indexes", true))
使用 External 类
确保您已在本地机器上安装了任何运行时环境依赖项(如 JRE)(直接在本地机器上或通过容器提供)。有关详细信息,请参阅扩展服务部分。
注意:从 Java 管道中包含 Python 转换时,所有 Python 依赖项都必须包含在 SDK 运行时容器中。
启动您尝试使用的转换所在语言的 SDK 的扩展服务(如果不可用)。
确保您尝试使用的转换可用,并且扩展服务可以使用它。
实例化管道时包含 External.of(…)。引用 URN、有效负载和扩展服务。有关示例,请参阅 跨语言转换测试套件。
在将作业提交到 Beam 运行器后,通过终止扩展服务进程来关闭扩展服务。
13.2.2. 在 Python 管道中使用跨语言转换
如果跨语言转换有 Python 特定的包装器,请使用它。否则,您必须使用更底层的 ExternalTransform 类来访问转换。
使用SDK包装器
要通过 SDK 包装器使用跨语言转换,请导入 SDK 包装器的模块并在您的管道中调用它,如示例所示。
from apache_beam.io.kafka import ReadFromKafka
kafka_records = (
pipeline
| 'ReadFromKafka' >> ReadFromKafka(
consumer_config={
'bootstrap.servers': self.bootstrap_servers,
'auto.offset.reset': 'earliest'
},
topics=[self.topic],
max_num_records=max_num_records,
expansion_service=<Address of expansion service>))
使用 ExternalTransform 类
如果不可用 SDK 特定的包装器,您必须通过 ExternalTransform 类访问跨语言转换。
确保您已在本地机器上安装了任何运行时环境依赖项(如 JRE)。有关详细信息,请参阅扩展服务部分。
启动您尝试使用的转换所在语言的 SDK 的扩展服务(如果不可用)。Python 提供了几个用于自动启动扩展 Java 服务的类,例如 JavaJarExpansionService 和 BeamJarExpansionService,它们可以直接作为扩展服务传递给
beam.ExternalTransform。确保您尝试使用的转换可用,并且扩展服务可以使用它。对于 Java,确保转换的构建器和注册器在扩展服务的类路径中可用。
实例化管道时包含
ExternalTransform。引用 URN、有效负载和扩展服务。您可以使用一个可用的PayloadBuilder类来构建ExternalTransform的有效负载。with pipeline as p: res = ( p | beam.Create(['a', 'b']).with_output_types(unicode) | beam.ExternalTransform( TEST_PREFIX_URN, ImplicitSchemaPayloadBuilder({'data': '0'}), <expansion service>)) assert_that(res, equal_to(['0a', '0b']))有关其他示例,请参阅 addprefix.py 和 javacount.py。
在将作业提交到 Beam 运行器后,通过终止扩展服务进程来关闭任何手动启动的扩展服务。
使用 JavaExternalTransform 类
Python 可以通过 代理对象 调用 Java 定义的转换,就好像它们是 Python 转换一样。这些以如下方式调用。
```py
MyJavaTransform = beam.JavaExternalTransform('fully.qualified.ClassName', classpath=[jars])
with pipeline as p:
res = (
p
| beam.Create(['a', 'b']).with_output_types(unicode)
| MyJavaTransform(javaConstructorArg, ...).builderMethod(...)
assert_that(res, equal_to(['0a', '0b']))
```
如果 Java 中的方法名是保留的 Python 关键字(如 from),则可以使用 Python 的 getattr 方法。
与其他外部转换一样,可以提供一个预启动的扩展服务,或者提供包含转换、其依赖项和 Beam 扩展服务的 jar 文件,在这种情况下将自动启动扩展服务。
13.2.3. 在 Go 管道中使用跨语言转换
如果跨语言有 Go 特定的包装器,请使用它。否则,您必须使用更底层的 CrossLanguage 函数来访问转换。
扩展服务
Go SDK 支持自动启动 Java 扩展服务(如果未提供扩展地址),尽管这比提供持久性扩展服务要慢。许多包装的 Java 转换会自动执行此操作;如果您希望手动执行此操作,请使用 xlangx 包的 UseAutomatedJavaExpansionService() 函数。为了使用 Python 跨语言转换,您必须手动在本地机器上启动任何必要的扩展服务,并确保在管道构建期间您的代码可以访问它们。
使用SDK包装器
要通过 SDK 包装器使用跨语言转换,请导入 SDK 包装器的包并在您的管道中调用它,如示例所示。
import (
"github.com/apache/beam/sdks/v2/go/pkg/beam/io/xlang/kafkaio"
)
// Kafka Read using previously defined values.
kafkaRecords := kafkaio.Read(
s,
expansionAddr, // Address of expansion service.
bootstrapAddr,
[]string{topicName},
kafkaio.MaxNumRecords(numRecords),
kafkaio.ConsumerConfigs(map[string]string{"auto.offset.reset": "earliest"}))
使用 CrossLanguage 函数
如果不可用 SDK 特定的包装器,您必须通过 beam.CrossLanguage 函数访问跨语言转换。
确保您正在运行适当的扩展服务。有关详细信息,请参阅扩展服务部分。
确保您尝试使用的转换可用,并且扩展服务可以使用它。有关详细信息,请参阅 创建跨语言转换。
根据需要在您的管道中使用
beam.CrossLanguage函数。引用 URN、有效负载、扩展服务地址,并定义输入和输出。您可以使用 beam.CrossLanguagePayload 函数作为编码有效负载的辅助工具。您可以使用 beam.UnnamedInput 和 beam.UnnamedOutput 函数作为单个未命名输入/输出的快捷方式,或为命名输入/输出定义一个映射。type prefixPayload struct { Data string `beam:"data"` } urn := "beam:transforms:xlang:test:prefix" payload := beam.CrossLanguagePayload(prefixPayload{Data: prefix}) expansionAddr := "localhost:8097" outT := beam.UnnamedOutput(typex.New(reflectx.String)) res := beam.CrossLanguage(s, urn, payload, expansionAddr, beam.UnnamedInput(inputPCol), outT)在将作业提交到 Beam 运行器后,通过终止扩展服务进程来关闭扩展服务。
13.2.4. 在 Typescript 管道中使用跨语言转换
使用 Typescript 包装器进行跨语言管道类似于使用任何其他转换,前提是依赖项(例如,最新的 Python 解释器或 Java JRE)可用。例如,大多数 Typescript IOs 只是其他语言 Beam 转换的包装器。
如果包装器尚不可用,可以使用 apache_beam.transforms.external.rawExternalTransform 显式使用它。它接受一个 `urn`(标识转换的字符串)、一个 `payload`(二进制或 json 对象,参数化转换)和一个 `expansionService`,它可以是预启动服务的地址,也可以是返回自动启动扩展服务对象的调用函数。
例如,可以编写
pcoll.applyAsync(
rawExternalTransform(
"beam:registered:urn",
{arg: value},
"localhost:expansion_service_port"
)
);
注意,pcoll 必须具有与跨语言兼容的编码器,例如 SchemaCoder。这可以通过 withCoderInternal 或 withRowCoder 转换来确保,例如
const result = pcoll.apply(
beam.withRowCoder({ intFieldName: 0, stringFieldName: "" })
);
如果无法推断编码器,也可以在输出上指定编码器,例如
此外,还有一些实用工具,例如 pythonTransform,可以简化从特定语言调用转换的过程。
const result: PCollection<number> = await pcoll
.apply(
beam.withName("UpdateCoder1", beam.withRowCoder({ a: 0, b: 0 }))
)
.applyAsync(
pythonTransform(
// Fully qualified name
"apache_beam.transforms.Map",
// Positional arguments
[pythonCallable("lambda x: x.a + x.b")],
// Keyword arguments
{},
// Output type if it cannot be inferred
{ requestedOutputCoders: { output: new VarIntCoder() } }
)
);
跨语言转换也可以在行内定义,这对于访问调用 SDK 中不可用的功能或库很有用。
const result: PCollection<string> = await pcoll
.apply(withCoderInternal(new StrUtf8Coder()))
.applyAsync(
pythonTransform(
// Define an arbitrary transform from a callable.
"__callable__",
[
pythonCallable(`
def apply(pcoll, prefix, postfix):
return pcoll | beam.Map(lambda s: prefix + s + postfix)
`),
],
// Keyword arguments to pass above, if any.
{ prefix: "x", postfix: "y" },
// Output type if it cannot be inferred
{ requestedOutputCoders: { output: new StrUtf8Coder() } }
)
);
13.3. 运行器支持
目前,Flink、Spark 和直接运行器等可移植运行器可以与多语言管道一起使用。
Dataflow 通过 Dataflow Runner v2 后端架构支持多语言管道。
13.4 提示和故障排除
有关其他提示和故障排除信息,请参阅 此处。
14 批处理 DoFns
批处理 DoFn 目前是 Python 独有的功能。
批处理 DoFn 使用户能够创建操作多个逻辑元素批次的模块化、可组合组件。这些 DoFn 可以利用向量化 Python 库(如 numpy、scipy 和 pandas),这些库对数据批次进行操作以提高效率。
14.1 基础
批处理 DoFn 目前是 Python 独有的功能。
一个简单的批处理 DoFn 可能如下所示
class MultiplyByTwo(beam.DoFn):
# Type
def process_batch(self, batch: np.ndarray) -> Iterator[np.ndarray]:
yield batch * 2
# Declare what the element-wise output type is
def infer_output_type(self, input_element_type):
return input_element_type此 DoFn 可用于其他方式对单个元素进行操作的 Beam 管道。Beam 将隐式缓冲元素并在输入端创建 numpy 数组,并在输出端将 numpy 数组分解回单个元素。
(p | beam.Create([1, 2, 3, 4]).with_output_types(np.int64)
| beam.ParDo(MultiplyByTwo()) # Implicit buffering and batch creation
| beam.Map(lambda x: x/3)) # Implicit batch explosion注意,我们使用 PTransform.with_output_types 为 beam.Create 的输出设置逐元素类型提示。然后,当 MultiplyByTwo 应用于此 PCollection 时,Beam 会识别 np.ndarray 是与 np.int64 元素一起使用的可接受批处理类型。我们将在本指南中一直使用像这样的 numpy 类型提示,但 Beam 也支持来自其他库的类型提示,请参阅 支持的批处理类型。
在前面的情况下,Beam 将隐式在输入和输出边界处创建和分解批次。但是,如果将具有相同类型的批处理 DoFn 连接在一起,则此批处理创建和分解将被省略。批次将直接传递!这使得对操作批次的转换进行有效组合变得更加简单。
(p | beam.Create([1, 2, 3, 4]).with_output_types(np.int64)
| beam.ParDo(MultiplyByTwo()) # Implicit buffering and batch creation
| beam.ParDo(MultiplyByTwo()) # Batches passed through
| beam.ParDo(MultiplyByTwo()))14.2 按元素回退
批处理 DoFn 目前是 Python 独有的功能。
对于某些 DoFn,您可能能够为所需逻辑提供批处理和逐元素的实现。您可以通过简单地定义 process 和 process_batch 来做到这一点。
class MultiplyByTwo(beam.DoFn):
def process(self, element: np.int64) -> Iterator[np.int64]:
# Multiply an individual int64 by 2
yield element * 2
def process_batch(self, batch: np.ndarray) -> Iterator[np.ndarray]:
# Multiply a _batch_ of int64s by 2
yield batch * 2执行此 DoFn 时,Beam 将根据上下文选择最佳实现。一般来说,如果 DoFn 的输入已经过批处理,Beam 将使用批处理实现;否则,它将使用在 process 方法中定义的逐元素实现。
注意,在这种情况下,不需要定义 infer_output_type。这是因为 Beam 可以从 process 上的类型提示中获取输出类型。
14.3 批处理生产与批处理消费
批处理 DoFn 目前是 Python 独有的功能。
按照惯例,Beam 假设使用批处理输入的 process_batch 方法也将生成批处理输出。类似地,Beam 假设 process 方法将生成单个元素。这可以通过 @beam.DoFn.yields_elements 和 @beam.DoFn.yields_batches 装饰器来覆盖。例如
# Consumes elements, produces batches
class ReadFromFile(beam.DoFn):
@beam.DoFn.yields_batches
def process(self, path: str) -> Iterator[np.ndarray]:
...
yield array
# Declare what the element-wise output type is
def infer_output_type(self):
return np.int64
# Consumes batches, produces elements
class WriteToFile(beam.DoFn):
@beam.DoFn.yields_elements
def process_batch(self, batch: np.ndarray) -> Iterator[str]:
...
yield output_path14.4 支持的批处理类型
批处理 DoFn 目前是 Python 独有的功能。
在本指南中的批处理 DoFn 实现中,我们使用了 numpy 类型 - np.int64 作为元素类型提示,np.ndarray 作为相应的批处理类型提示 - 但 Beam 也支持来自其他库的类型提示。
numpy
| 元素类型提示 | 批处理类型提示 |
|---|---|
数值类型(int、np.int32、bool、…) | np.ndarray(或 NumpyArray) |
pandas
| 元素类型提示 | 批处理类型提示 |
|---|---|
数值类型(int、np.int32、bool、…) | pd.Series |
bytes | |
任何 | |
| Beam 架构类型 | pd.DataFrame |
pyarrow
| 元素类型提示 | 批处理类型提示 |
|---|---|
数值类型(int、np.int32、bool、…) | pd.Series |
任何 | |
List | |
映射 | |
| Beam 架构类型 | pa.Table |
其他类型?
如果您想使用其他批处理类型与批处理 DoFn 一起使用,请 提交问题。
14.5 动态批量输入和输出类型
批处理 DoFn 目前是 Python 独有的功能。
对于某些批处理 DoFn,仅使用 process 和/或 process_batch 上的类型提示静态声明批处理类型可能还不够。您可能需要动态声明这些类型。您可以通过覆盖 DoFn 上的 get_input_batch_type 和 get_output_batch_type 方法来做到这一点。
# Utilize Beam's parameterized NumpyArray typehint
from apache_beam.typehints.batch import NumpyArray
class MultipyByTwo(beam.DoFn):
# No typehints needed
def process_batch(self, batch):
yield batch * 2
def get_input_batch_type(self, input_element_type):
return NumpyArray[input_element_type]
def get_output_batch_type(self, input_element_type):
return NumpyArray[input_element_type]
def infer_output_type(self, input_element_type):
return input_element_type14.6 批量和事件时间语义
批处理 DoFn 目前是 Python 独有的功能。
目前,批次必须具有适用于批次中每个逻辑元素的单个时间信息集(事件时间、窗口等)。目前没有机制来创建跨越多个时间戳的批次。但是,可以在 Batched DoFn 实现中检索此时间信息。可以使用传统的 DoFn.*Param 属性访问此信息。
class RetrieveTimingDoFn(beam.DoFn):
def process_batch(
self,
batch: np.ndarray,
timestamp=beam.DoFn.TimestampParam,
pane_info=beam.DoFn.PaneInfoParam,
) -> Iterator[np.ndarray]:
...
def infer_output_type(self, input_type):
return input_type15 变换服务
Apache Beam SDK 版本 2.49.0 及更高版本包含一个名为“转换服务”的 Docker Compose 服务。
下图说明了转换服务的架构基础。
要使用转换服务,Docker 必须在启动服务的机器上可用。
转换服务有几个主要用例。
15.1 使用变换服务升级变换
转换服务可用于升级(或降级)Beam 管道使用的受支持的单个转换的 Beam SDK 版本,而无需更改管道的 Beam 版本。此功能目前仅适用于 Beam Java SDK 2.53.0 及更高版本。目前,以下转换可用于升级
- BigQuery 读取转换(URN:beam:transform:org.apache.beam:bigquery_read:v1)
- BigQuery 写入转换(URN:beam:transform:org.apache.beam:bigquery_write:v1)
- Kafka 读取转换(URN:beam:transform:org.apache.beam:kafka_read_with_metadata:v2)
- Kafka 写入转换(URN:beam:transform:org.apache.beam:kafka_write:v2)
要使用此功能,您只需执行一个 Java 管道,并添加一些管道选项,这些选项指定您要升级的转换的 URN 和您要将转换升级到的 Beam 版本。管道中所有具有匹配 URN 的转换都将被升级。
例如,要将使用 Beam 2.53.0 运行的管道的 BigQuery 读取转换升级到未来的 Beam 版本 2.xy.z,您可以指定以下其他管道选项。
--transformsToOverride=beam:transform:org.apache.beam:bigquery_read:v1 --transformServiceBeamVersion=2.xy.zThis feature is currently not available for Python SDK.This feature is currently not available for Go SDK.请注意,框架会自动为您下载相关的 Docker 容器并启动转换服务。
请参阅 这里,了解使用此功能升级 BigQuery 读取和写入转换的完整示例。
15.2 使用变换服务进行多语言管道
转换服务实现了 Beam 扩展 API。这使 Beam 多语言管道在扩展转换服务中提供的转换时能够使用转换服务。这里的主要优点是,多语言管道能够在不安装对其他语言运行时支持的情况下运行。例如,使用 Java 转换(如 KafkaIO)的 Beam Python 管道能够在不安装 Java 在本地进行作业提交的情况下运行,只要系统中有 Docker。
在某些情况下,Apache Beam SDK 可以自动启动转换服务。
当本地没有 Python 运行时,但有 Docker 时,Java
PythonExternalTransformAPI 会自动启动转换服务。当您使用 Java 转换,本地没有 Java 语言运行时,并且本地有 Docker 时,Apache Beam Python 多语言包装器可能会自动启动转换服务。
Beam 用户还可以选择 手动启动 转换服务,并将其用作多语言管道使用的扩展服务。
15.3 手动启动变换服务
可以使用 Apache Beam SDK 提供的实用程序手动启动 Beam 转换服务实例。
java -jar beam-sdks-java-transform-service-app-<Beam version for the jar>.jar --port <port> --beam_version <Beam version for the transform service> --project_name <a unique ID for the transform service> --command uppython -m apache_beam.utils.transform_service_launcher --port <port> --beam_version <Beam version for the transform service> --project_name <a unique ID for the transform service> --command upThis feature is currently in development.要停止转换服务,请使用以下命令。
java -jar beam-sdks-java-transform-service-app-<Beam version for the jar>.jar --port <port> --beam_version <Beam version for the transform service> --project_name <a unique ID for the transform service> --command downpython -m apache_beam.utils.transform_service_launcher --port <port> --beam_version <Beam version for the transform service> --project_name <a unique ID for the transform service> --command downThis feature is currently in development.15.4 变换服务中包含的可移植变换
Beam 转换服务包含在 Apache Beam Java 和 Python SDK 中实现的一些转换。
目前,转换服务中包含以下转换
Java 转换:Google Cloud I/O 连接器、Kafka I/O 连接器和 JDBC I/O 连接器
Python 转换:在 Apache Beam Python SDK 中实现的所有可移植转换,例如 RunInference 和 DataFrame 转换。
有关可用转换的更全面列表,请参阅 转换服务 开发人员指南。
最后更新于 2024/10/31
您找到所有需要的内容了吗?
所有内容都实用且清晰吗?您想更改任何内容吗?请告诉我们!