




“Apache Beam 是一个定义明确的数据处理模型,它使您可以专注于业务逻辑,而不是分布式处理的底层细节。”

搜索引擎工作负载的可扩展性和成本优化
背景
Seznam.cz 是捷克的一家搜索引擎,为当地超过 25% 的有机搜索流量提供服务。Seznam 雇用了 1,500 多名员工,运营着 30 多项网络服务和相关品牌,每天处理约 1500 万次查询。
Seznam 不断优化其大数据基础设施、网络爬虫、算法和 ML 模型,以期为用户实现搜索结果的准确性、质量和实用性的卓越性。Seznam 是 Apache Beam 的早期贡献者和采用者,他们将多个 PB 级工作负载迁移到 Apache Beam 管道,这些管道在 Seznam 的内部数据中心中运行在 Apache Spark 和 Apache Flink 集群中。
Apache Beam 之旅
Seznam 从 2010 年开始在 Hadoop Yarn 集群中使用 MapReduce 来促进其搜索引擎网络爬虫组件的并发批处理作业处理。几年内,他们的数据基础设施发展到 超过 400 亿行,数据量达到 400 TB,在 HBase 中有 2 个内部数据中心,拥有超过 1,100 台裸机服务器,13 PB 的存储空间和 50 TB 的内存,这使得他们的业务逻辑更加复杂。MapReduce 无法再提供足够的灵活性,成本效率和性能 来支持这种增长,Seznam 将作业重写为原生 Spark。Spark shuffle 操作 使 Seznam 能够将大型数据键拆分为分区,一次将它们加载到内存中,并迭代地处理它们。但是,指数级数据倾斜和无法将单个键的所有值都放入内存缓冲区导致了 磁盘空间利用率和内存开销增加。一些任务的完成时间出乎意料地长,并且由于通用异常,调试 Spark 管道也具有挑战性。因此,Seznam 需要一个可以更高效地扩展的数据处理框架。
要管理这种规模,您需要抽象。
2014 年,Seznam 开始开发 Euphoria API - 一种专有编程模型,可以表达批处理和流式管道中的业务逻辑,并允许运行器独立实现。
Apache Beam 于 2016 年发布,成为一个现成可用且定义明确的统一编程模型。这种引擎独立模型一直在快速发展,支持多个 shuffle 运算符,并完美地适合 Seznam 的现有内部数据基础设施。一段时间以来,Seznam 继续开发 Euphoria,但很快,维护解决方案所需的成本和工作量以及在内部创建自己的运行器所带来的好处超过了拥有专有框架的好处。

Seznam 开始将其关键工作负载迁移到 Apache Beam。他们决定将 Euphoria API 合并为 Apache Beam Java SDK 的高级 DSL。这对 Apache Beam 的重大贡献是 Seznam 主动参与社区的起点,后来他们在 2019 年欧洲 Beam 峰会 和开发者大会上展示了他们独特的经验和发现。
采用 Apache Beam
Apache Beam 使 Seznam 能够以更快的速度执行批处理和流式作业,而不会增加内存和磁盘空间,从而最大限度地提高可扩展性、性能和效率。
Apache Beam 提供多种方法来均匀地分配倾斜数据。用于处理无界数据的 窗口 和用于处理有界数据集的 分区 将输入转换为可以重新洗牌的有限元素集合。Apache Beam 提供了一个基于字节的 shuffle,可以由 Spark 运行器或 Flink 运行器执行,而无需要求 Apache Spark 或 Apache Flink 反序列化完整的键。Apache Beam SDK 提供有效的编码器来序列化和反序列化元素,并传递给分布式工作器。使用 Apache Beam 序列化和基于字节的 shuffle 为 Seznam 的许多用例带来了显著的性能提升,并减少了 Apache Spark 执行环境所需的 shuffle 内存。Seznam 与 磁盘 I/O 和内存拆分 相关的基础设施成本大幅下降。
最有价值的用例之一是 Seznam 的 LinkRevert 作业,它分析网络图以提高搜索相关性。这个数据管道形象地“将互联网颠倒过来”,每天处理超过 150 TB 的数据,扩展重定向链以识别特定 URL 的每个后继者,并发现指向特定网页的回链。Apache Beam 管道执行多个大规模倾斜联接,并根据重定向和回链因素对搜索结果中的 URL 进行评分。
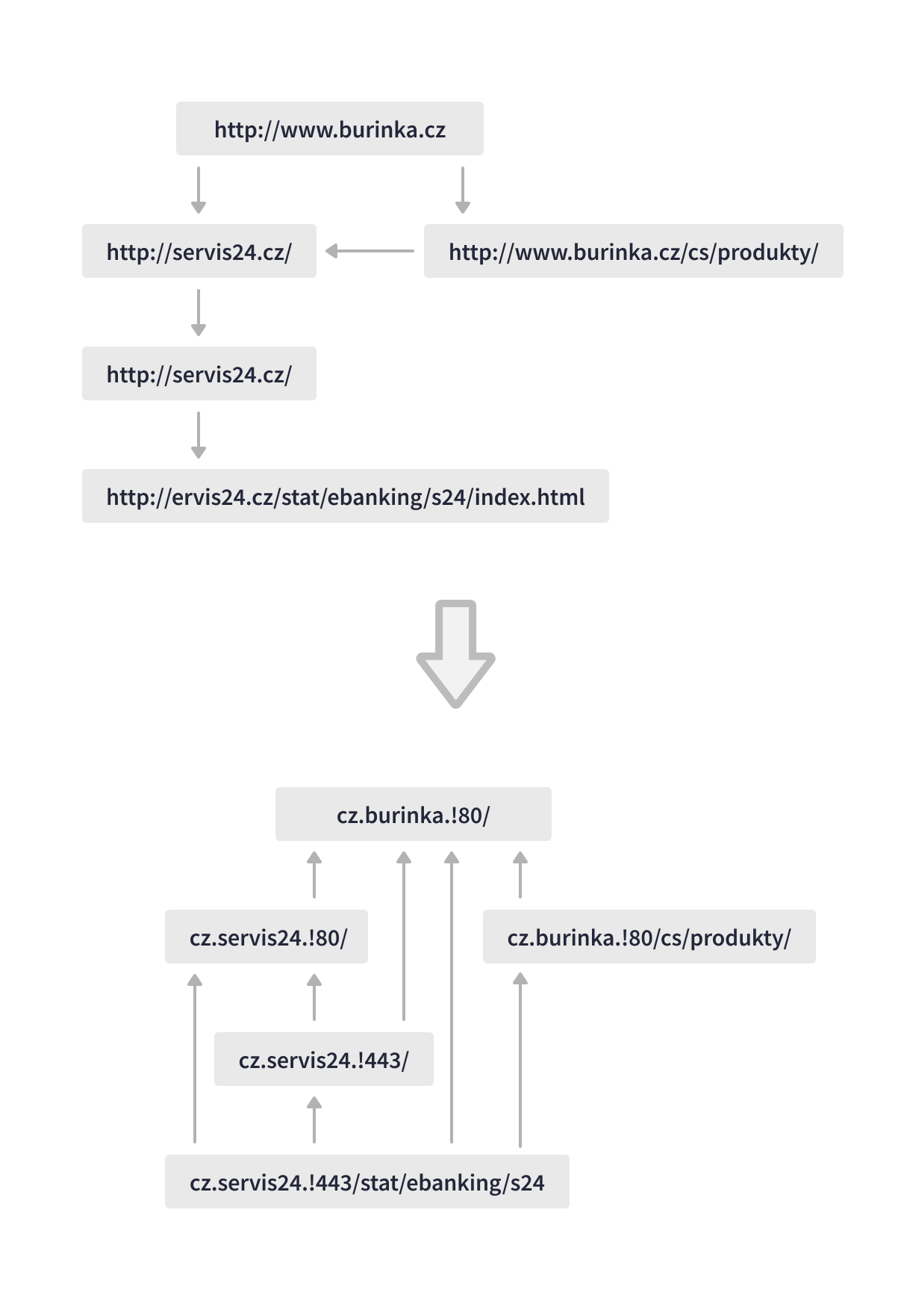
Apache Beam 允许统一的引擎独立执行,因此 Seznam 能够根据用例在 Spark 或 Flink 运行器之间进行选择。例如,由 Spark 运行器在 Hadoop Yarn 集群上执行的 Apache Beam 批处理管道解析新网页文档,使用其他功能丰富数据,并根据网页相关性对网页进行评分,确保及时更新数据库和准确的搜索结果。Apache Beam 流式处理在 Kubernetes 集群上的 Apache Flink 执行环境中运行,用于在用户搜索结果中显示的缩略图请求。流式事件处理的另一个示例是 Apache Beam Flink 运行器管道,它映射、联接和处理搜索日志以计算 SLO 指标和其他功能。
多年来,Seznam 的方法已经发展。他们已经意识到 Apache Beam 在平衡 PB 级工作负载和优化内部数据中心中的内存和计算资源方面带来的巨大好处。Apache Beam 是 Seznam 的首选平台,用于需要多个 shuffle 操作、处理倾斜数据和实现复杂业务逻辑的批处理和流式管道。Apache Beam 统一模型以及作为转换公开的源和接收器,通过单元测试提高了业务逻辑的可维护性和可追溯性。
最大好处之一是 Apache Beam 接收器和源。通过将您的源或接收器公开为转换,您的实现将被隐藏,以后您可以添加其他功能,而不会破坏对用户的现有实现。
监控和调试
Apache Beam 管道监控和调试对于具有复杂业务逻辑和多个数据转换的案例至关重要。Seznam 工程师根据执行引擎确定了最佳工具。Seznam 利用 Criteo 的 Babar 来分析 Spark 运行器上的 Apache Beam 管道,并确定其性能下降的根本原因。Babar 通过分析集群资源利用率、分配的内存、使用的 CPU 等,可以更轻松地进行监控、调试和性能优化。对于在 Kubernetes 集群上的 Flink 运行器执行的 Apache Beam 管道,Seznam 使用 Elasticsearch 来存储、搜索和分析指标。
结果
Apache Beam 为 Seznam 的流式和批处理处理提供了一个统一的模型,该模型提供了可扩展的性能。Apache Beam 支持多种运行器、语言 SDK 以及内置和自定义可插拔 I/O 转换,因此无需投资于专有运行器和解决方案的开发和支持。经过评估,Seznam 将其工作负载迁移到 Apache Beam,并集成了 Euphoria API(由 Seznam 开发的快速原型框架),为 Apache Beam 开源社区做出了贡献。
Apache Beam 的抽象和执行模型使 Seznam 能够稳健地扩展其数据处理。它还提供了灵活性,可以让您只需编写一次业务逻辑,并保持在运行器之间进行选择的自由。该模型对于复杂用例中的管道可维护性特别有价值。Apache Beam 通过将分布不均的数据重新洗牌为可管理的分区,帮助克服了内存和计算资源限制。
这些信息对您有帮助吗?