




“没有 Beam,没有所有这些数据和实时信息,我们就无法提供我们正在提供的服务,也无法处理我们正在处理的数据量。”

Apache Beam 加速 Ricardo 的实时和机器学习数据处理,助力电商平台发展。
背景
Ricardo 是瑞士领先的二手市场平台。该网站支持超过 400 万注册买家和卖家,每年通过该平台处理超过 650 万件商品交易。Ricardo 需要处理大量流式事件并管理超过 5TB 的商品、资产和分析数据。
随着 20 年市场规模的增长,Ricardo 决定从内部数据中心迁移到云端,以便轻松扩展和发展,并通过托管云服务降低运营成本。数据智能和工程团队带头进行这一转型,并开发新的 AI/ML 支持的客户体验。Apache Beam 作为一种技术放大器,加速了 Ricardo 的转型。
挑战
从内部数据中心迁移到云端为 Ricardo 提供了一个机会,让他们能够从高度依赖传统的交易型 SQL 迁移到使用 BigQuery 进行分析,并利用基于事件的流式架构。
Ricardo 的数据智能团队确定了两个关键的成功因素:精心设计的数据模型和一个能够在内部和云端提供统一的流式和批处理数据管道执行的框架。
Ricardo 需要一个数据处理框架,该框架能够轻松扩展,使用来自多个来源的历史数据丰富事件流,提供对数据新鲜度的细粒度控制,并提供抽象的管道操作基础设施,从而帮助他们的团队专注于为客户和业务创造新的价值。
走向 Beam 的旅程
Ricardo 的数据智能团队从 2018 年开始对其技术栈进行现代化改造。他们选择了能够在内部和云端提供可靠且可扩展的数据处理的框架。Apache Beam 允许用户使用其喜欢的编程语言创建管道,并提供 Java、Python、Go、SQL、Scala (SCIO) 的 SDK。一个 Beam 运行器 在特定的(通常是分布式)数据处理系统上运行 Beam 管道。Ricardo 选择了 Apache Beam Flink 运行器在内部执行管道,并选择 Dataflow 运行器作为使用 Apache Beam Java SDK 开发的相同管道的托管云服务。Apache Flink 以其可靠性和成本效益而闻名,Ricardo 的数据中心启动了一个内部集群作为初始环境。
我们希望实施一个能够将我们可能性乘以十倍的解决方案,而 Beam 正是如此。这一决定背后的主要驱动因素之一是,我们能够在不增加太多运营负担的情况下不断发展。
将核心业务工作负载的 Beam 管道从 Apache Kafka 导入 BigQuery 的工作在仅仅一个月内就稳定运行。随着 Ricardo 的云迁移的进行,数据智能团队 将内部数据中心 Kubernetes 中的 Flink 集群迁移到 GKE。
我知道 Beam,我知道它有效。当你需要从 Kafka 迁移到 BigQuery,并且知道 Beam 正是合适的工具时,你只需要选择合适的执行器。
能够根据具体的用例和需求以每小时、每分钟或实时的方式刷新数据,帮助该团队提高了数据新鲜度,这对于 Ricardo 的电商平台分析和报告来说是一个重大进步。
Ricardo 的团队发现 Apache Beam Flink 运行器在 GKE 上自托管的 Flink 集群中对于流式管道来说具有优势。完全控制 Flink 配置能够设置 Flink 集群到外部对等 Kafka 托管服务的必要连接。数据智能团队通过显著优化集群资源利用率降低了运营成本。对于批处理管道,该团队选择了 Dataflow 托管服务,因为它提供了按需自动扩展和 FlexRS 等降低成本的功能,对于在 TB 级历史数据上训练机器学习模型来说尤其高效。这种混合方法很好地满足了 Ricardo 的需求,并证明是一种可靠的生产解决方案。
用例的演变
将流式数据视为动态数据,将表视为静态数据,这为我们提供了一个良机,让我们可以回顾一下早在 20 年前做出的某些数据模型决策。市场上的商品具有描述它们的资产,为了提高性能和成本优化,属于一起的数据实体被拆分成不同的数据库实例。Apache Beam 使 Ricardo 的数据智能团队能够 加入资产和商品流 并优化 BigQuery 扫描以降低成本。在设计管道时,该团队为资产和商品创建了流式数据。由于资产流式数据是主要流式数据,他们将流式数据向后移动 5 分钟,并在 BigTable 中创建了一个查找模式。这种巧妙的解决方案确保资产流式数据始终首先被处理,同时 BigTable 允许将最新的资产与商品匹配,Apache Beam 将两者合并在一起。
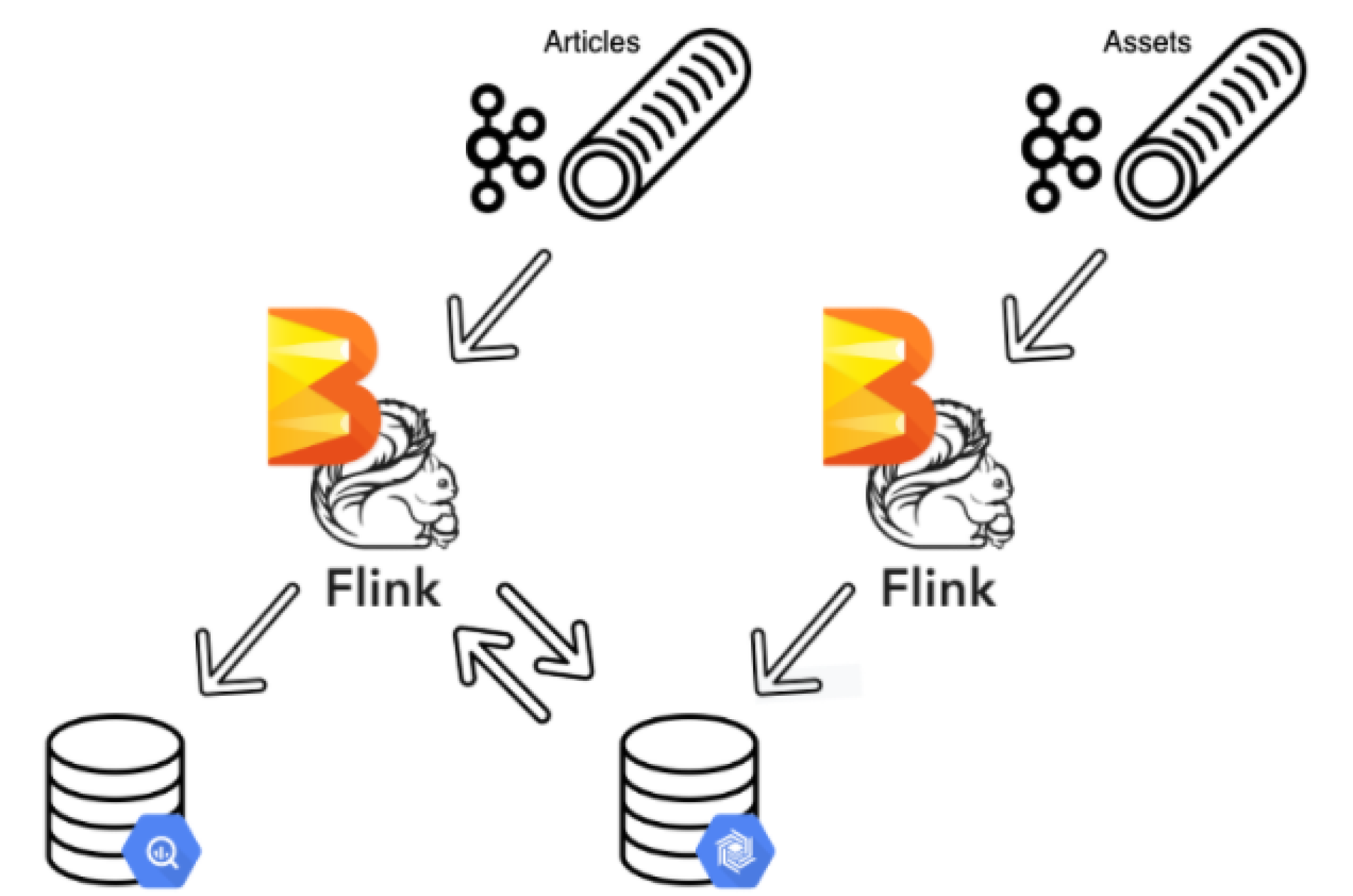
成功加入不同的数据流促使 Ricardo 在数据科学和机器学习等领域进一步采用 Apache Beam。
一旦你开始设计简单的用例,你总会发现边缘情况。这个管道已经运行了一年,Beam 处理了所有事情,从非常简单的用例到非常复杂的事情。
作为一家电商零售商,Ricardo 面临着欺诈交易的规模和复杂性的不断增长,并通过使用 Beam 管道进行欺诈检测和预防采取了战略性方法。Beam 管道根据外部智能 API 的操作来识别欺诈行为的迹象,例如设备特征或用户活动。Apache Beam 有状态处理 功能使 Ricardo 能够对数据流应用关联操作(例如,触发封禁用户)。因此,Apache Beam 节省了 Ricardo 的客户服务团队在调查重复案件方面的时间和精力。它还运行批处理管道以 查找关联账户,通过封装机器学习模型将商品与类别关联起来,或者计算某个商品的销售可能性,以以往无法达到的规模或精度。
Apache Beam 最初由 Ricardo 的数据智能团队实施,它被证明是一个强大的框架,支持高级场景,并充当 Kafka、BigQuery、平台和外部 API 之间的粘合剂,这鼓励了 Ricardo 的其他团队采用它。
[Apache Beam] 是一款非常棒的框架,在我们测试之后,其他团队也开始接受这个想法并开始使用它。
结果
Apache Beam 为 Ricardo 提供了一个可扩展且可靠的数据处理框架,该框架支持 Ricardo 的基本业务场景,并能够实现新的用例以实时响应事件。
在 Ricardo 的转型过程中,Apache Beam 一直是一个统一的框架,能够运行批处理和流式管道,提供内部和云托管服务的执行,以及 Java 和 Python 等编程语言选项,使数据科学和研究团队能够快速利用新的实时场景,从而加快了价值实现时间。
在第一个管道之后,我们正在处理其他用例,并计划将它们迁移到 Beam。我一直试图传播这样一个想法,即这是一个可靠的框架,它实际上可以帮助你以一致的方式完成工作。
Apache Beam 是一种使可能性成倍增加的技术,使 Ricardo 能够在其现代化和云迁移之旅的各个阶段最大限度地利用技术优势。
了解更多
这些信息是否有用?