




“Apache Beam 支持我们使网络更安全和更美好的使命,通过为客户提供对流量数据的近乎实时可见性,提供对防御的持续分析和调整,以及抵消 DDoS 攻击期间流量峰值对我们平台性能和效率的影响。”

高效的流式分析:利用 Project Shield 使网络更安全
背景
Project Shield,由 Google Cloud 和 Jigsaw(Google 的子公司)提供,是一种抵御 分布式拒绝服务 (DDoS) 攻击的服务。Project Shield 免费提供给符合条件的网站,这些网站包含媒体、选举和人权相关内容。 成立于 2013 年,Project Shield 的使命是保护言论自由,确保当人们能够访问与民主相关的资讯时,这些资讯不会受到损害、审查或以政治动机的方式被封锁。
在 2022 年上半年,Project Shield 保护了弱势用户的网站,例如人权、新闻和民间社会组织,或者在紧急情况下,政府网站 抵御了超过 25,000 次攻击。值得注意的是,Project Shield 帮助确保了 在 2022 年美国中期选举期间,不受阻碍地访问与选举相关的资讯。它还 使乌克兰的关键基础设施和媒体网站能够抵御不间断的攻击,并在乌克兰被入侵期间继续提供至关重要的服务和资讯。
创始工程师 Marc Howard 和 Chad Hansen 解释了 Project Shield 如何使用 Apache Beam 来实现其核心价值。流式 Apache Beam 管道每天处理大约 3 TB 的日志数据,每秒超过 10,000 次查询。这些管道支持多种产品需求。例如,Apache Beam 为 来自 150 个国家的超过 3000 个客户网站 生成实时分析和重要指标。这些指标推动了大规模的长期攻击分析,微调了 Project Shield 的防御,并在努力使网络成为安全和自由的空间中支持它们。
通往 Beam 的旅程
Project Shield 平台使用 Google Cloud 技术构建,并提供多层防御。为了吸收部分流量并保持网站在线,即使它们的服务器停机,它也使用 Cloud CDN 进行 缓存。为了保护网站免受 DDoS 和其他恶意攻击,它利用 Cloud Armor 功能,例如自适应保护、速率限制和机器人管理。
Project Shield 充当 反向代理:它代表网站接收流量请求,通过缓存吸收流量,过滤有害流量,禁止攻击者,然后将安全流量发送到网站的源服务器。这种配置使网站能够在有人试图用 DDoS 攻击将其关闭时保持运行。挑战在于,随着大量流量被阻止,客户源服务器上的日志不再包含有关网站流量的准确分析。相反,客户依赖 Project Shield 提供所有流量分析。
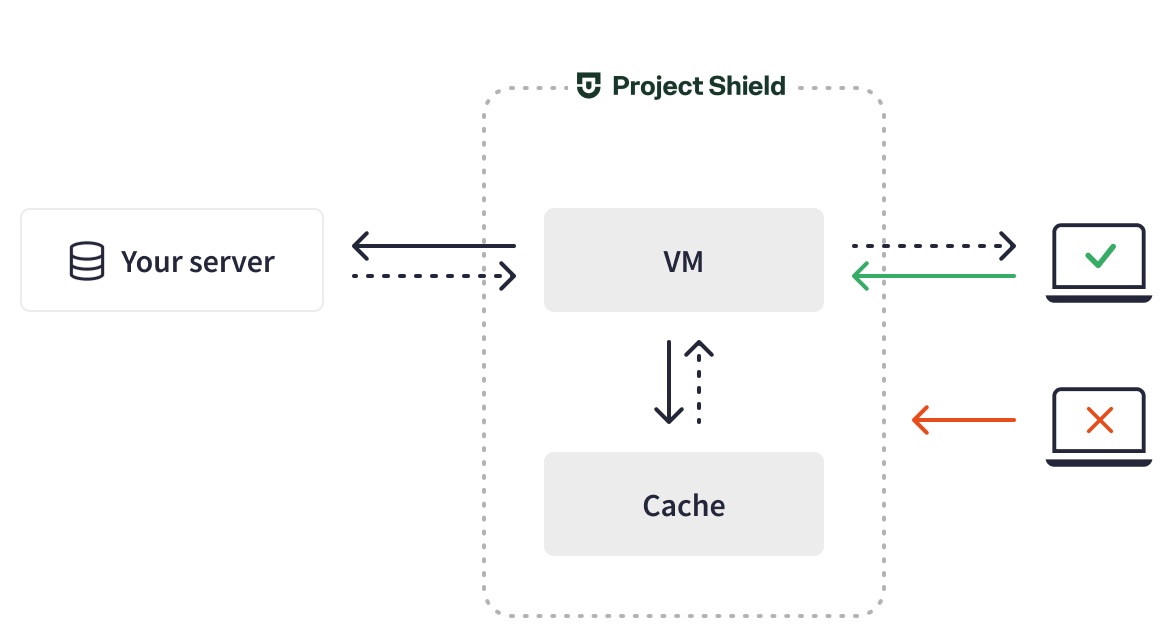 Project Shield 机制
Project Shield 机制最初,Project Shield 将流量日志存储在 BigQuery 中。它使用一个大型查询来生成带有不同流量指标的分析和图表,例如流量量、QPS、缓存流量的份额和攻击数据。但是,查询所有日志,尤其是在流量激增的情况下,速度很慢且成本高昂。
人们通常想知道在关键时刻的流量指标:如果他们的网站遭到攻击:他们想知道现在发生了什么。我们需要数据点快速出现在 UI 上。
Project Shield 的团队随后添加了 Firestore 作为中间步骤,每分钟运行一次 cron 来查询 BigQuery 中的日志并将临时报告写入 Firestore,然后使用这些报告构建图表。此步骤略微提高了性能,但增益不足以满足关键的业务时间线,并且没有为客户提供足够的可见性,让他们了解历史流量。
与 BigQuery 不同,Firestore 是为中等规模的工作负载设计的。因此,无法同时获取许多模型,从而为客户提供扩展时间范围内的累积统计信息。每分钟查询日志从成本角度来看效率低下。此外,一些日志带有延迟到达 BigQuery,有必要在 24 小时后再次运行 cron 以检查迟到的日志。
每分钟查询所有流量日志非常昂贵,尤其是在考虑到我们是 DDoS 防御服务的情况下 - 我们看到的日志数量往往会急剧激增。
Project Shield 的团队寻找了一种数据处理框架,该框架可以最大限度地减少端到端延迟,满足其扩展需求以提高客户可见性,并确保成本效率。
他们选择了 Apache Beam,因为它具有 强大的处理保证、流式处理功能以及为 BigQuery 和 Pub/Sub 提供的现成 I/O。通过将 Apache Beam 与 Dataflow 运行器 配对,他们还受益于内置的自动扩展。此外,Apache Beam Python SDK 允许您在整个过程中使用 Python,并简化了读取数据模型类型的过程,这些类型必须在使用它们的后台和写入它们的管道上保持一致。
用例
Project Shield 成为 Apache Beam 的早期采用者之一,并在 2020 年将他们的工作流迁移到流式 Apache Beam 管道。目前,Apache Beam 通过多个流式管道支持多种产品需求。
生成面向用户的分析的统一流式管道从 Pub/Sub 中读取日志,这些日志来自 Cloud Logging,每分钟将日志窗口化一次,按请求的主机名拆分,生成报告,并将报告写入 BigQuery。该管道聚合日志数据,无需使用 DLP 即可删除 个人身份信息 (PII),并允许将数据存储在 BigQuery 中更长时间,同时满足监管要求。 CombineFn 使 Project Shield 的团队能够创建一个自定义累加器,该累加器在根据主机名和分钟对日志数据进行键控时会考虑键,将每个键的日志数据组合起来。如果日志迟到,Apache Beam 会创建一个新的报告,并根据每个主机名和分钟聚合多个报告。
我们只需对数据进行键控,使用 CombinePerKey,累加器就像魔术一样起作用,这对我们来说是一个巨大的胜利。
Apache Beam 日志处理管道使 Project Shield 能够仅查询相关报告,从而使 Project Shield 能够在短短 2 分钟内将数据加载到客户仪表板。该管道还为 Project Shield 的客户提供了增强的可见性,因为查询的报告尺寸更小,存储起来比流量日志更容易。
端到端管道延迟对我们来说非常重要,Apache Beam 流式处理允许在 2 分钟内在图表上显示所有流量指标,但也允许回顾几天、几周或几个月的历史数据,并在可扩展的时间范围内向客户显示图表。

Project Shield 扩展了流式 Apache Beam 日志处理管道,以根据攻击期间的日志和请求生成不同类型的报告。Apache Beam 管道分析攻击并生成关键的防御建议。这些建议随后被内部长期攻击分析系统用来微调 Project Shield 的防御。
Apache Beam 还通过分析流量日志中的模式来为 Project Shield 的流量速率限制决策提供动力。流式 Apache Beam 管道收集有关网站合法使用情况的资讯,从该分析中排除滥用流量,并制定安全地划分这两组的流量速率限制。这些限制随后以 Cloud Armor 规则和策略的形式执行,并用于限制滥用流量或完全禁止滥用流量。
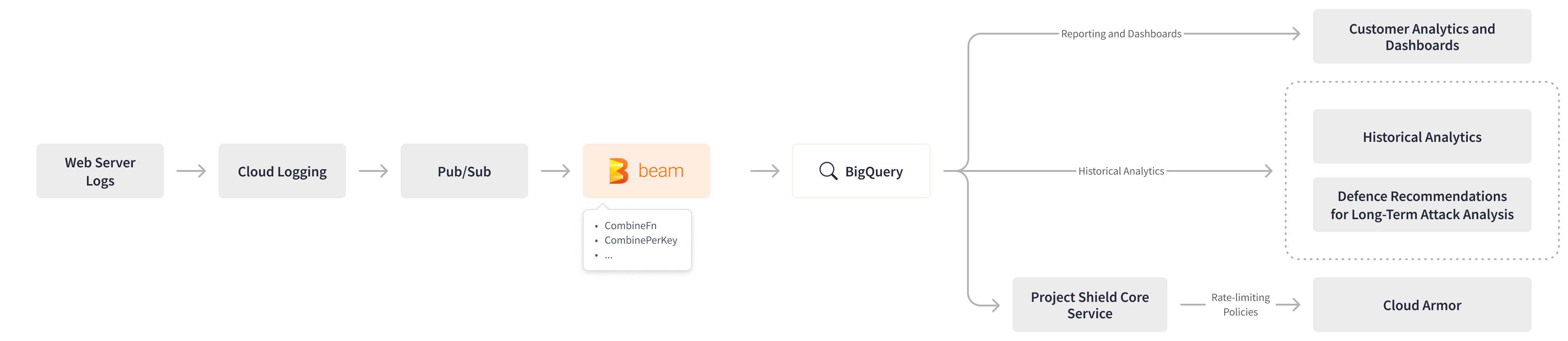 Apache Beam 流式日志分析
Apache Beam 流式日志分析Apache Beam 和 Cloud Dataflow 的结合极大地简化了 Project Shield 对流式管道的运营管理。Apache Beam 提供易于使用的流式处理基元,而 Dataflow 则支持 开箱即用的管道生命周期管理,并通过 消息去重和恰好一次、按顺序处理 来补充 Pub/Sub 的传递模型。Apache Beam Pub/Sub I/O 提供了根据 Pub/Sub 事件时间戳对日志数据进行键控的功能。此功能使 Project Shield 能够通过在所有相关日志到达后对日志数据进行窗口化来提高数据的总体准确性。 各种管理管道生命周期的选项 使 Project Shield 能够采用简单可靠的部署流程。Apache Beam Dataflow 运行器的 自动扩展和托管服务功能 有助于处理 DDoS 攻击期间资源消耗的急剧激增,并为客户提供即时可见性。
当攻击来临时,我们已准备好处理大量流量,并利用 Apache Beam 在关键窗口内按时交付指标。
结果
采用 Apache Beam 使 Project Shield 能够拥抱流式处理,扩展其管道,最大限度地提高效率并最小化延迟。流式 Apache Beam 管道每天处理约 3TB 的日志数据,每秒处理超过 10,000 个查询,以生成面向用户的分析、定制的流量速率限制,以及为全球超过 3000 名客户提供防御建议。Apache Beam 的流式处理和强大转换功能确保在短短 2 分钟内提供关键指标,使客户能够洞悉历史流量,与原始解决方案相比,计算效率提高了 91%。
Apache Beam 模型及其 Dataflow 运行器的自动伸缩功能有助于防止 DDoS 攻击期间的流量峰值对我们平台的效率和财务产生重大影响。
Apache Beam 数据处理框架支持 Project Shield 的目标,即消除 DDoS 攻击作为沉默记者和其他说出真相者声音的武器,使网络更加安全。
这些信息是否有用?