




“我知道一件事:Beam 非常强大,其抽象是其最重要的特性。有了正确的抽象,我们就可以灵活地根据需要运行工作负载。多亏了 Beam,我们没有绑定到任何供应商,如果我们进行切换,也不需要更改任何其他内容。”

Palo Alto Networks 大规模实时事件流处理
背景
Palo Alto Networks, Inc. 是一家全球网络安全领导者,拥有全面的企业产品组合。Palo Alto Networks 为 超过 85,000 个客户 提供保护,并提供跨云、网络和设备的可见性、可信情报、自动化和灵活性。
Palo Alto Networks 的集成安全运营平台 - Cortex™ - 应用人工智能和机器学习来为 Palo Alto Networks 的客户提供安全自动化、高级威胁情报和有效的快速安全响应。 Cortex™ 数据湖 基础设施收集、集成和规范化企业安全数据,并结合数万亿个多来源的工件。
Cortex™ 数据基础设施目前每秒处理约 1000 万个安全日志事件,每天约 3 PB,这在行业中处于实时流处理规模的顶端。Palo Alto Networks 的高级首席软件工程师 Talat Uyarer 分享了 Apache Beam 如何提供高性能、可靠和弹性的数据处理框架来支持这种规模。
大规模流式基础设施
在从头开始构建数据基础设施时,Palo Alto Networks 的 Cortex 数据湖团队面临着一项具有挑战性的任务。我们需要确保 Cortex 平台能够以低延迟和完美的质量将来自客户防火墙、网络和各种设备的 PB 级数据流式传输和处理到客户和内部应用程序。
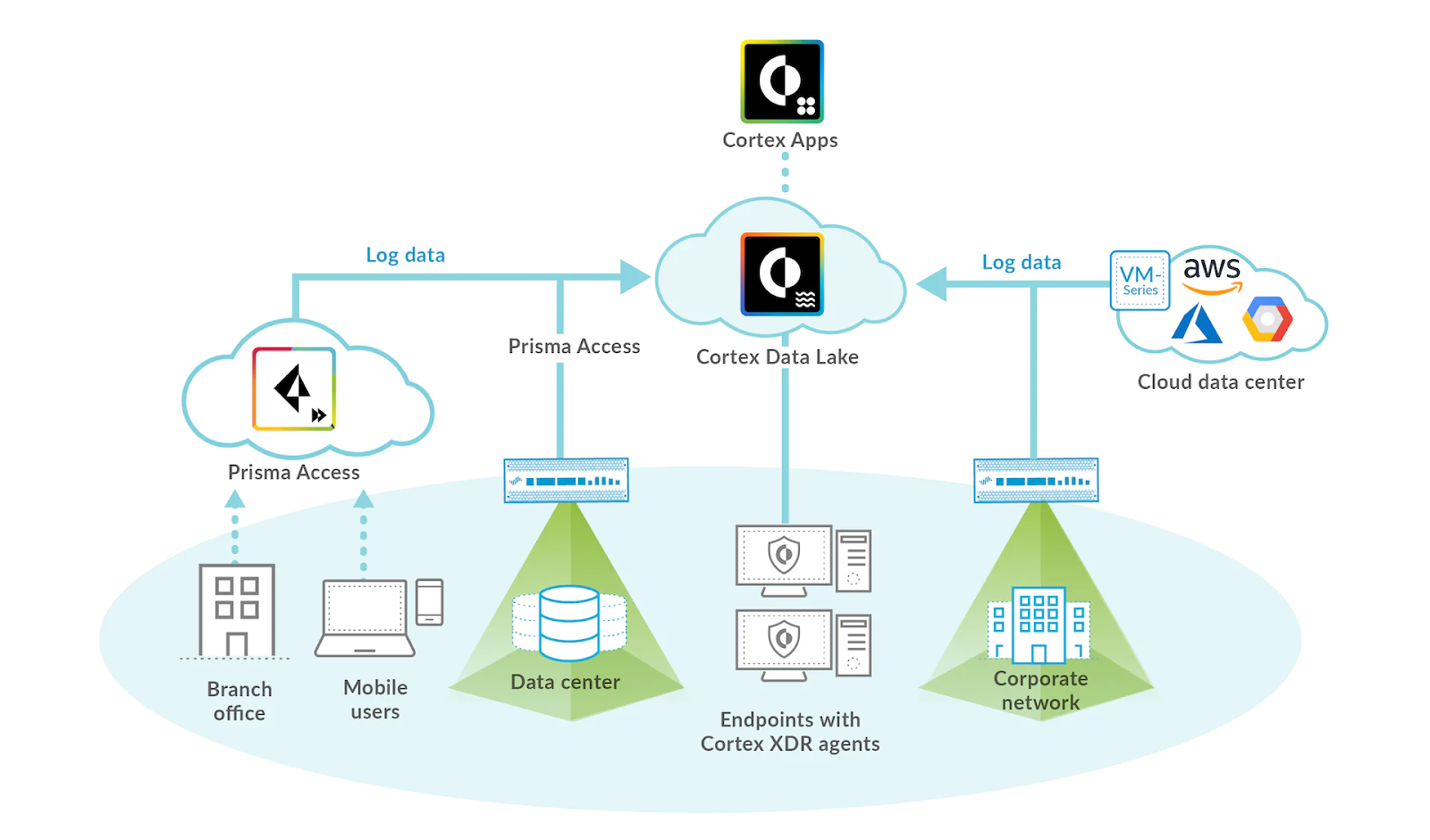
为了满足 SLA,Cortex 数据湖团队不得不设计一个用于实时处理的大规模数据基础设施,并减少价值实现时间。他们最初的架构决策之一是利用 Apache Beam,这是统一分布式处理的行业标准,因为它具有可移植性和抽象性。
Beam 非常灵活,它与分布式数据处理的实现细节的抽象对于快速交付概念验证非常有用。
Apache Beam 提供了各种运行器,提供了在不同数据处理引擎之间进行选择的自由。Palo Alto Networks 的数据基础设施完全托管在 Google Cloud Platform 上,并且 使用 Apache Beam Dataflow 运行器,我们可以轻松地从 Google Cloud Dataflow 的托管服务和 自动调整 功能中获益。Apache Kafka 被选为后端的消息代理,所有事件都以二进制数据形式存储在具有公共模式的多个 Kafka 集群中。
Cortex 数据湖团队考虑了为每个客户提供独立的数据处理基础设施的选项,其中多个上游应用程序创建自己的流式作业,直接从 Kafka 消费和处理事件。因此,我们正在构建一个多租户系统。但是,该团队预计可能存在与 Kafka 迁移和分区创建相关的潜在问题,以及缺乏对租户用例的可见性,这些问题可能会在拥有多个基础设施时出现。
因此,Cortex 数据湖团队采用了通用的流式基础设施方法。在通用数据基础设施的核心,Apache Beam 作为统一的编程模型,用于为所有内部和客户租户应用程序仅实现一次业务逻辑。
Cortex 数据湖团队实现的第一个数据工作流很简单:从 Kafka 读取,创建批处理作业,并将结果写入接收器。 具有 SQL 支持的 Apache Beam 版本 的发布开辟了新的可能性。 Beam Calcite SQL 为 复杂的 Apache Calcite 数据类型(包括嵌套行)在 SQL 语句中提供了完全支持,因此开发人员可以在 Apache Beam 管道中使用 SQL 查询进行复合转换。Cortex 数据湖团队决定利用 Beam SQL 来编写带有标准 SQL 语句的 Beam 管道。
通用基础设施的主要挑战是支持各种业务逻辑自定义和用户定义函数,并将它们转换为各种接收器格式。租户应用程序需要从动态变化的 Kafka 集群消费数据,并且如果作业的源已更新,则必须重新生成流式管道 DAG。
Cortex 数据湖团队开发了自己的“订阅”模型,该模型允许租户应用程序在将作业部署请求发送到 REST API 服务时“订阅”流式作业。订阅服务通过在元数据服务中存储基础设施特定的信息来将租户应用程序与 DAG 中的更改抽象出来。这样,流式作业与动态 Kafka 基础设施保持同步。
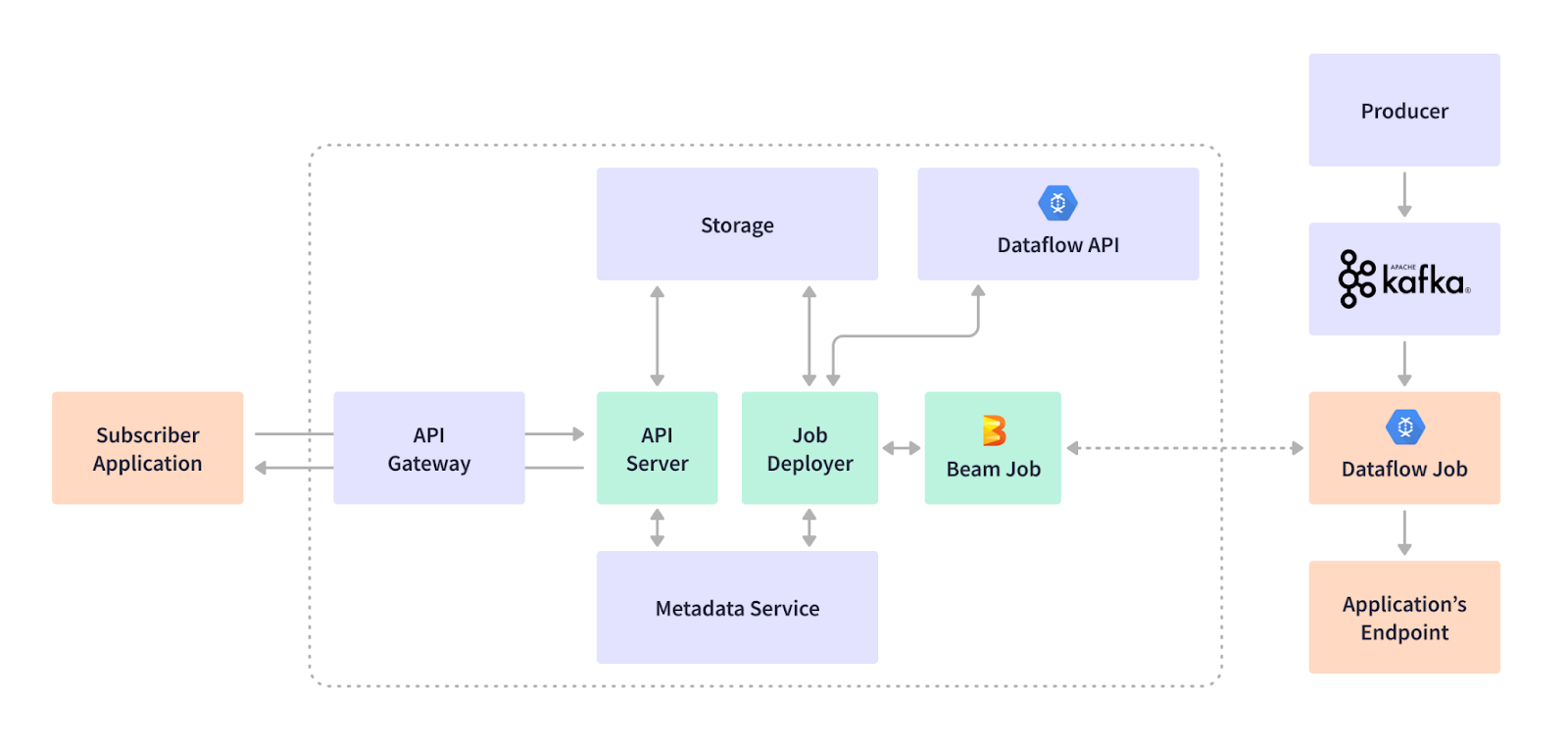
Apache Beam 非常灵活,它允许动态创建流式作业,即时创建。Apache Beam 结构允许通用管道编码,使管道能够处理数据,即使模式事先没有完全定义。Cortex 的订阅服务根据租户应用程序的 REST 负载生成 Apache Beam 管道 DAG,并将作业提交给运行器。当作业运行时, Apache Beam SDK 的 Kafka I/O 返回一个 Kafka 记录的无界集合作为 PCollection。 Apache Avro 将二进制 Kafka 表示转换为通用记录,这些记录被进一步转换为 Apache Beam Row 格式。行结构支持基本类型、字节数组和容器,并允许按与模式定义相同的顺序组织值。
Apache Beam 的跨语言转换允许 Cortex 数据湖团队使用 Java 执行 SQL。在 Apache Beam 管道内部执行的 SQL 转换 的输出被顺序地从 Beam 行格式转换为通用记录,然后转换为订阅者应用程序所需的输出格式,例如 Avro、JSON、CSV 等。
一旦基本用例得到实现,Cortex 数据湖团队就开始转向更复杂的转换,例如直接在 Apache Beam 管道内部过滤事件子集,并不断探索自定义和优化。
我们有超过 10 个用例在客户和应用程序之间运行。更多用例即将推出,比如机器学习用例……对于这些用例,Beam 提供了一个非常好的编程模型。
Apache Beam 提供了一个可插拔的数据处理模型,它与各种工具和技术无缝集成,这使得 Cortex 数据湖团队能够将数据处理定制为性能要求和特定用例。
为用例定制序列化
Palo Alto Networks 的流式数据基础设施每天处理数千亿个实时安全事件,即使是亚秒级差异的处理时间也是至关重要的。
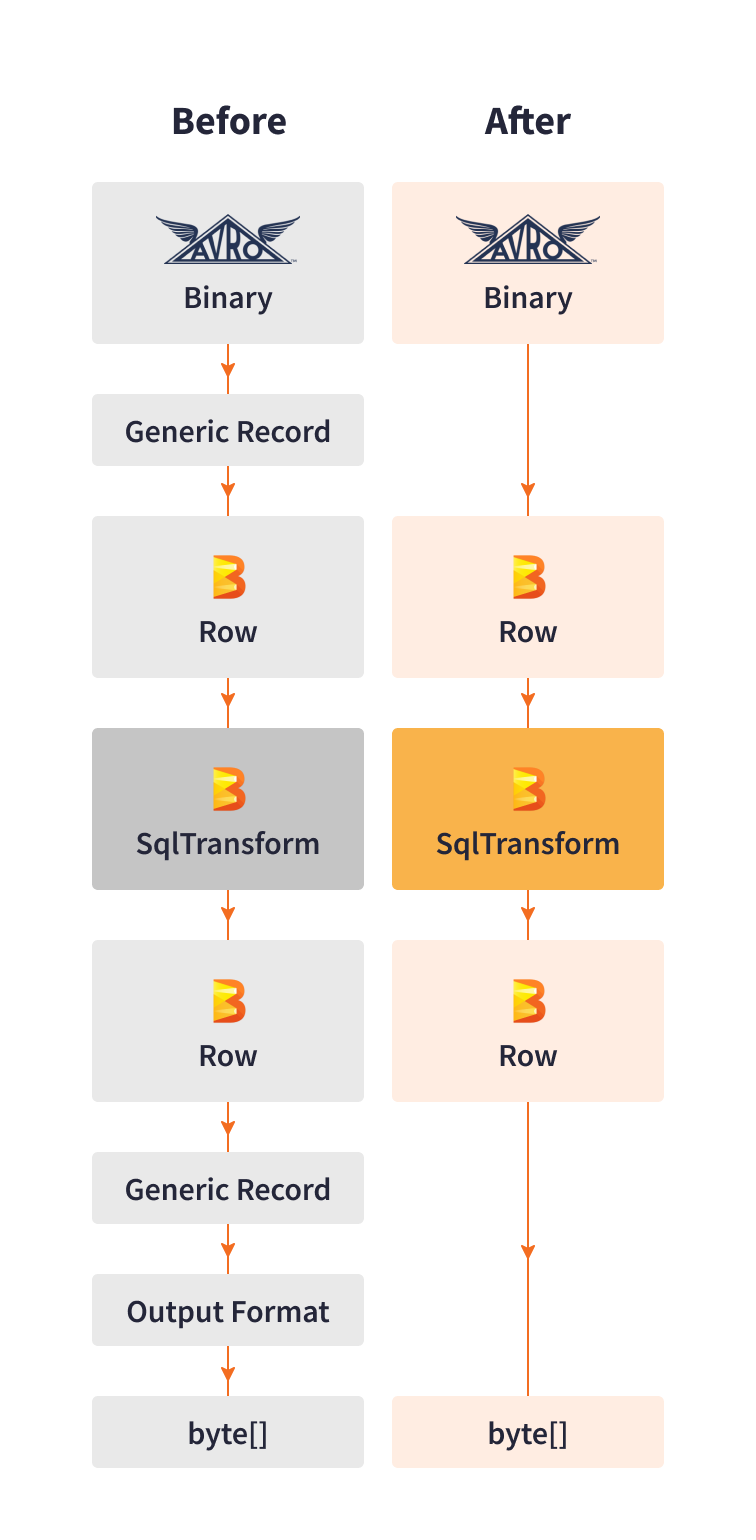
为了提高性能,Cortex 数据湖团队开发了自己的库用于直接序列化和反序列化。该库从 Kafka 读取 Avro 二进制记录,并将它们转换为 Beam 行格式,然后将 Beam 行格式管道输出转换为所需的接收器格式。
这个自定义库用针对 Palo Alto Networks 的特定用例优化的步骤替换了将数据序列化为通用记录的步骤。直接序列化消除了混洗和创建额外的内存副本,这些副本来自处理步骤。
这种自定义将序列化性能提高了 10 倍,允许每个 vCPU 每秒处理高达 3,000 个事件,并降低延迟和基础设施成本。
在运行时的流式作业更新
在数千个作业同时运行的规模下,Cortex 数据湖团队遇到了需要改进管道代码或修复正在运行的作业的错误的情况。Google Cloud Dataflow 提供了一种方法来 用运行更新的 Apache Beam 管道代码的新作业替换“正在运行的”流式作业。但是,Palo Alto Networks 需要扩展支持的场景。
为了解决在动态变化的 Kafka 基础设施中更新作业的问题,Cortex 数据湖团队在他们的部署服务中创建了一个额外的工作流,如果 Dataflow 更新 排空作业 不允许,则启动一个具有完全相同名称的新作业。这个内部作业替换工作流允许 Cortex 数据湖自动更新所有用例的作业和有效负载。
处理 Beam SQL 中的模式变更
Palo Alto Networks 解决的另一个用例是处理正在运行的作业的数据模式变更。Apache Beam 允许 PCollection 具有 模式,该模式具有在管道构造步骤中验证的命名字段。当提交作业时,将根据最新模式生成以 Beam 管道片段形式存在的执行计划。Beam SQL 尚未为运行作业提供对松散模式兼容性的内置支持。为了优化性能,Beam SQL 的模式 RowCoder 具有固定的数据格式,并且不处理模式演变,因此必须重新启动作业才能重新生成它们的执行计划。在 10,000 多个流式作业的规模下,Cortex 数据湖团队希望尽可能避免重新提交作业。
我们创建了一个内部工作流程来识别与模式变更相关的 SQL 查询作业。模式更新工作流程将每个作业的读取器模式(Avro 模式)和每个 Kafka 消息的写入器模式(Kafka 头部的元数据)存储在内部模式注册中心中,并将它们与正在运行的作业的 SQL 查询进行比较,仅重新启动受影响的作业。这种优化使他们能够更有效地利用资源。
针对 Kafka 变更进行性能微调
在 Kafka 中拥有多个集群和主题,以及超过 10 万个分区,Palo Alto Networks 需要确保正在运行的作业不会受到频繁的 Kafka 基础设施变更的影响,例如集群迁移或分区数量的变化。
Cortex Data Lake 团队开发了几个内部 Kafka 生命周期支持工具,包括一个“自我修复”服务。根据特定租户从特定主题接收的流量量,内部服务会增加分区数量或创建具有较少分区的新主题。“自我修复”服务会比较数据存储中的 Kafka 状态,然后自动查找并更新所有相关的流式 Apache Beam 作业到 Cloud Dataflow。
随着 Apache Beam 2.28.0 版本 在 2021 年初发布,预构建的 Kafka I/O 动态读取功能 提供了一个开箱即用的解决方案,用于检测 Kafka 分区变化,从而实现成本节约和性能提升。Kafka I/O 使用 WatchKafkaTopicPartitionDoFn 来发出新的 TopicPartitions,并在添加特定分区时允许动态地从 Kafka 主题读取,或者在删除特定分区时停止读取。此功能消除了创建内部 Kafka 监控工具的必要性。
除了性能优化之外,Cortex Data Lake 团队一直在探索优化 Cloud Dataflow 成本的方法。我们研究了在流式作业消耗很少的传入事件的情况下,资源使用优化的方案。为了提高成本效益,Google Cloud Dataflow 提供了 流式自动缩放 功能,该功能会根据负载和资源利用率的变化自适应地改变工作者的数量。对于 Cortex Data Lake 团队的一些用例,其中输入数据流可能会在长时间内静止,我们实现了一个内部“冷启动”服务,该服务会分析 Kafka 主题流量,并将输入数据流枯竭的管道休眠,并在输入数据流恢复后重新激活它们。
Talat Uyarer 在 Beam Summit 2021 上介绍了 Cortex Data Lake 构建和定制大规模流式基础设施的经验。
我真的很喜欢使用 Beam。如果你了解它的内部机制,这种理解将使你能够微调开源软件,对其进行定制,从而为你的特定用例提供最佳性能。
结果
Apache Beam 的抽象级别使 Cortex Data Lake 团队能够在其内部应用程序和数万个客户之间创建通用的基础设施。使用 Apache Beam,我们只需实现一次业务逻辑,就可以动态生成 10,000 多个并行运行的流式管道,用于 10 多个用例。
Cortex Data Lake 团队利用 Apache Beam 的可移植性和可插拔性,使用自定义库和服务来微调和增强其数据处理基础设施。Palo Alto Networks 最终实现了高性能和低延迟,每个 vCPU 每秒处理 3,000 多个流式事件。结合开源 Apache Beam 和 Cloud Dataflow 托管服务的优势,我们能够实现特定于用例的定制,并将他们的成本降低了 60% 以上。
Apache Beam 开源社区欢迎并鼓励其众多成员(例如 Palo Alto Networks)的贡献,这些成员利用了 Apache Beam 的强大功能,带来了新的优化,并通过分享他们的专业知识和积极参与社区来促进未来的创新。
这些信息有用吗?