




“我们的数据量非常庞大,Apache Beam 帮助我们管理这些数据。对于每天数百万笔交易中的每一笔,我们都会生成一个模拟其市场估值演变的模拟,并在未来的时间增量上进行细粒度划分,然后通过扫描多个可能的市场情景,将这些海量数据汇总成有意义的统计数据。Apache Beam 帮助我们利用所有这些数据,并使数据分发比以前更加轻松。”

“Apache Beam Python SDK 将数学引入到编排级别,为汇丰银行的模型开发团队提供了一种简单的方法,可以模拟业务逻辑工作流程中节点之间复杂的数学依赖关系,这些工作流程是用 Python 编写的管道。我们过去至少要花 6 个月才能将即使是最小的系统方程变更部署到生产环境。通过 Apache Beam 推动的新团队结构,我们现在可以在 1 周内完成变更部署。”

汇丰银行使用 Apache Beam 进行高性能定量风险分析
背景
汇丰控股有限公司 是汇丰银行的母公司,总部位于伦敦。汇丰银行在 62 个国家和地区设有办事处,为全球客户提供服务。截至 2023 年 3 月 31 日,汇丰银行的资产规模为 2.99 万亿美元,是全球最大的银行和金融服务机构之一。汇丰银行的 全球银行与市场业务 为跨国公司、政府和金融机构提供广泛的金融服务和产品。
汇丰银行 XVA 和 CCR 资本分析副总裁 Chup Cheng 和首席助理副总裁 Andrzej Golonka 分享了 Apache Beam 如何作为计算平台和风险引擎,帮助汇丰银行管理其客户投资组合的对手方信用风险和 XVA,这些风险来自每天无数对手方之间数万亿美元的交易量。Apache Beam 使汇丰银行能够 将现有的 C++ HPC 工作负载集成到批处理 Apache Beam 管道中,以简化数据分发并提高处理性能。Apache Beam 还使以前无法实现的新管道成为可能,并提高了开发效率。
大规模风险管理
为了了解 Apache Beam 支持的汇丰银行数据处理的规模和价值,让我们深入探讨为什么金融机构的对手方信用风险计算需要特别极端的计算能力。
投资组合的价值随着金融市场的波动而波动,并受到各种外部因素的影响。为了抵消风险并确定监管机构要求的资本储备,投资银行需要估计风险敞口并对单个交易和投资组合的价值进行相应的调整。 XVA(X 值调整)模型 在分析金融行业的对手方信用风险方面发挥着至关重要的作用,涵盖了不同的估值调整,例如 信用估值调整 (CVA)、资金估值调整 (FVA) 和 资本估值调整 (KVA)。计算 XVA 涉及复杂的模型、多层矩阵和 蒙特卡罗模拟,以根据可能的未来情景来考虑风险。估值函数处理多个 随机微分方程 (SDE) 矩阵,这些矩阵代表特定时间范围内(最长可能为 70 年)的可能交易价值,然后输出 MTM(市值) 矩阵,这些矩阵代表了金融资产当前市场价值根据未来情景的分布。折叠后的 MTM 矩阵确定了未来风险敞口的向量和所需的 XVA 调整。
由于涉及大量的矩阵数据和很长的时段,XVA 计算需要大量的计算能力。为了计算一个交易的 MTM 矩阵,估值函数需要通过多个 SDE 矩阵迭代数十万次,这些矩阵重达几兆字节,每个矩阵包含数十万个元素。
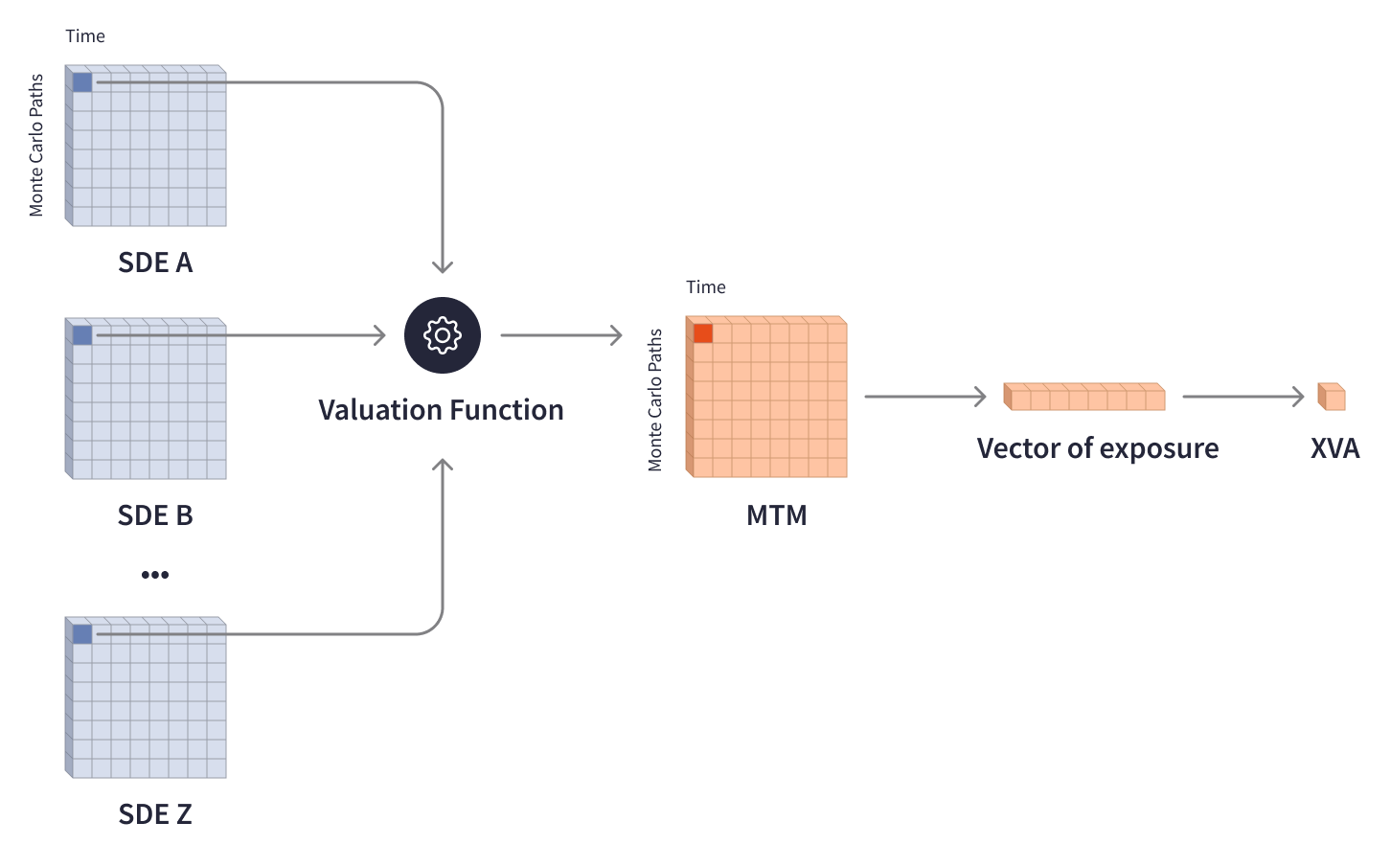
对多对手方投资组合进行 XVA 计算涉及在一个大型方程组中进行更复杂的计算。估值函数会遍历数百 GB 的 SDE 矩阵,生成数百万个交易级别的 MTM 矩阵,将其聚合到对手方级别的矩阵,然后计算每个对手方的未来风险敞口和 XVA。
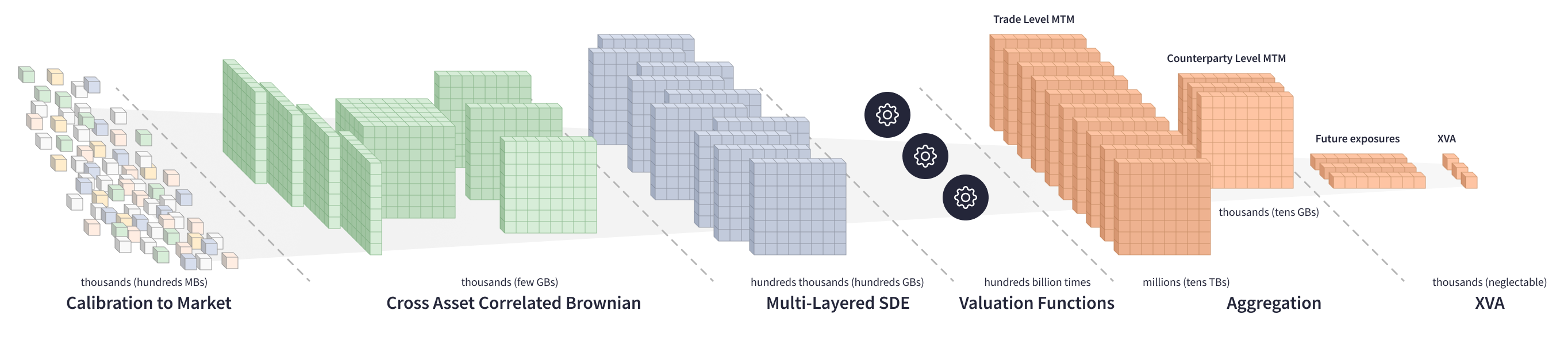
当处理对众多市场因素敏感的 XVA 时,技术挑战会升级。为了抵消对手方投资组合中的所有市场风险,投资银行需要计算数百个市场因素的 XVA 敏感度。主要有两种方法来计算 XVA 敏感度
- 通过反向传播分析输入
- 通过观察 XVA 的梯度移动进行数值计算
为了获得 XVA 方差,估值函数必须通过庞大的方程组迭代数千亿次,这是一个非常计算密集的过程。
XVA 模型对于了解金融行业的对手方信用风险不可或缺,准确计算 XVA 对于评估衍生品的全价至关重要。由于涉及大量数据和复杂的计算,这些计算的有效和及时执行对于确保交易者能够做出明智的决策至关重要。
迈向 Beam 之旅
NOLA 是汇丰银行内部用于 XVA 计算的数据基础设施。其以前的版本 - NOLA1 - 是一种内部部署的解决方案,使用 10 TB 的文件服务器作为介质,在单个批次中处理数 PB 的数据,遍历每个方程组内的巨大网络互依赖关系,然后重复此过程。汇丰银行的模型开发团队正在创建新的统计模型并构建量化库,而他们的 IT 团队则将必要的数据提取到该库中,两个团队共同努力将方程组之间的编排布局出来。
2007 年至 2008 年的金融危机凸显了在整个行业内对稳健高效的 XVA 计算的需求,并在金融领域引入了额外的监管规定,这些规定要求进行指数级的计算。因此,汇丰银行寻求了一种数值解决方案来计算数百个市场因素的 XVA 敏感度。在单个批次中处理数据已成为一个阻碍和吞吐量瓶颈。NOLA1 基础设施及其密集的 I/O 利用率当时不利于扩展。
汇丰银行的工程师开始寻找一种新方法,该方法能够扩展数据处理、最大程度地提高吞吐量并满足关键的业务时间线。
然后,汇丰银行的工程团队选择了 Apache Beam 作为 NOLA 的风险引擎,因为它具有可扩展性、灵活性和能够并行处理大量数据的能力。他们发现 Apache Beam 是 XVA 计算的转换、有向无环图过程的自然过程执行器。 Apache Beam Python SDK 提供了一个简单的 API 来使用 Python 构建新的数据管道,而它的抽象提供了一种方法来 重用流行的 C++ 分析。各种 Apache Beam 运行器提供了可移植性,汇丰银行的工程师使用 Apache Beam 管道构建了其数据基础设施的新版本 - NOLA2,该管道在 Apache Flink 和 Cloud Dataflow 上运行。
数据分发比以前更轻松
Apache Beam 极大地简化了 XVA 计算的数据分发,并允许使用工作器之间的分布式处理来处理相互关联的蒙特卡罗模拟。
Apache Beam SDK 使用户能够构建表达性 DAG,并轻松创建流或批处理多阶段管道,在这些管道中,可以使用 旁路输入 或 连接 将并行流水线阶段合并在一起。数据移动由运行器处理,数据以 PCollection 对象的形式表示,PCollection 对象是不可变的并行元素集合。
Apache Beam 提供了几种方法来分发 C++ 组件
- 将 C++ 组件侧载到自定义工作器容器映像(例如,自定义 Apache Beam 或 Cloud Dataflow 容器),然后使用 DoFns 与 C++ 组件开箱即用地交互
- 将 C++ 与 Apache Beam 中的 JAR 文件捆绑在一起,其中 C++ 元素(二进制文件、配置等)在 DoFn 中的设置/拆卸过程中提取到本地磁盘
- 将 C++ 组件包含在 PCollection 中作为旁路输入,然后将其部署到本地磁盘
Apache Beam 与 C++ 的无缝集成使汇丰银行的工程师能够重用流行的分析(依赖于 NAG 和 MKL 库),并根据用例和部署环境在逻辑分发方法之间进行选择。汇丰银行发现,当 PCollection 从 Java 或 Python 管道将调用和输入数据传递到 C++ 库时,protobuf 在数据交换方面特别有用。Protobuf 数据可以通过磁盘、网络或直接使用诸如 pybind11 之类的工具来共享。
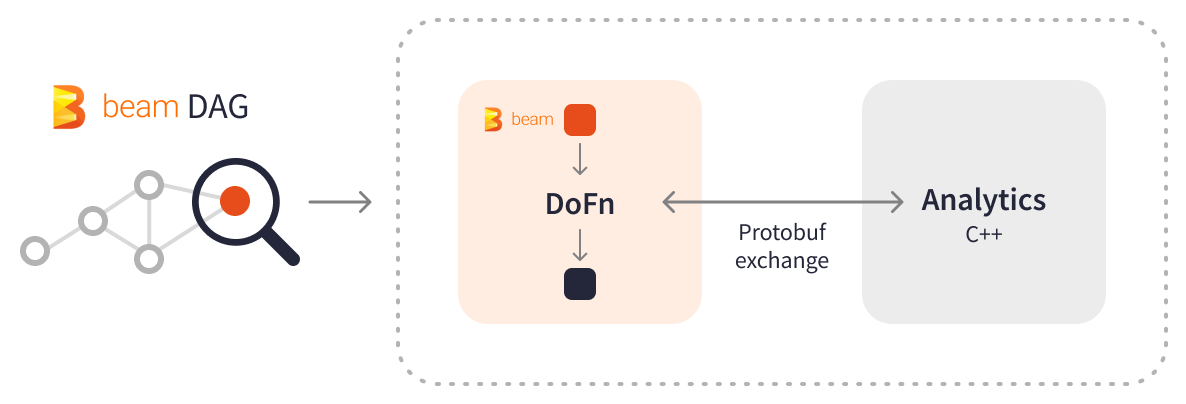
汇丰银行将其 XVA 计算迁移到批处理 Apache Beam 管道。每天,XVA 管道在短短 1 小时内计算超过数千亿次估值,消耗大约 2 GB 的外部输入数据,在方程组中处理 10 到 20 TB 的数据,并生成约 4 GB 的输出报告。Apache Beam 将 XVA 计算分布到多个带任务的 PCollection 中,独立并行执行必要的转换,并生成地图减少的结果 - 所有这些都一步到位。
Apache Beam 提供了强大的 转换 和编排功能,帮助汇丰银行工程师优化了 XVA 敏感性计算的分析方法,并实现了之前无法实现的数值计算。 而不是将估值函数遍历整个方程组,汇丰工程师将方程组视为计算图,将其分解为具有可重用元素的集群,并遍历最小计算图。 他们使用 Apache Beam 编排来有效地处理每个投资组合的数万个集群,方法是调用 C++“可执行文件”。 Apache Beam 使汇丰能够使用 KV PCollections 将 PCollection 的每个输入元素与一个键关联,并在单个 Apache Beam 批量管道中计算数百个市场因素的 XVA 敏感性。
执行分析和数值 XVA 敏感性计算的 Apache Beam 管道每天以两个独立批次运行。 第一个批次管道在午夜运行,确定交易员的信贷额度消耗和资本利用率,直接影响他们第二天交易量。 第二个批次在早上 8 点之前完成,计算可能影响交易员风险管理和对冲策略的 XVA 敏感性。 该管道每天消耗约 2 GB 的外部市场数据,处理方程组中高达 400 TB 的内部数据,并将数据聚合到仅约 4 GB 的输出报告中。 在每个月结束时,该管道会处理方程组中超过 5 PB 的月度数据,以生成全面的 XVA 敏感性报告。 Apache Beam 解决数据分布和热点问题,协助管理复杂计算中涉及的数据。
Apache Beam 为汇丰提供了传统风险引擎的所有特性,甚至更多,使汇丰能够通过分布式处理扩展基础设施并最大限度地提高吞吐量。
Apache Beam 使数据分布比以前容易得多。 蒙特卡罗方法显着增加了要处理的数据量。 Apache Beam 帮助我们利用了所有这些数据量。
Beam 作为平台
Apache Beam 不仅仅是一个数据处理框架。 它也是一个计算平台,它能够进行实验,加快新开发的上市时间,并简化部署。
Apache Beam 的数据集抽象作为 PCollection 通过提供组织组件所有权和减少组织依赖关系和瓶颈的方法,提高了汇丰的模型开发效率。 模型开发团队现在拥有数据管道:实现新的方程组,以黑盒模式定义方程组内的数据传输,并将其发送给 IT 团队。 IT 团队获取、控制和编排方程组所需的外部数据。
通常,我们至少需要 6 个月才能将即使是最小的方程组更改部署到生产环境中。 借助 Apache Beam 推动的全新团队结构,我们现在可以在 1 周内快速部署更改。
通过利用 Apache Beam 统一编程模型提供的抽象,汇丰的模型开发团队可以无缝创建新的数据管道,选择合适的运行器,并在无需底层基础设施的情况下对大数据进行实验。 Apache Beam 模型规则确保实验代码的质量,并使生产级管道从实验到生产非常容易。
使用 Apache Beam,可以轻松地对“如果”问题进行实验。 如果我们想知道更改某些参数的影响,我们可以编写一个简单的 Apache Beam 代码,运行管道,并在几分钟内获得答案。
Apache Beam 用于蒙特卡罗模拟和对手信用风险分析的关键优势之一是它能够在各种环境中运行相同的复杂模拟逻辑,无论是在本地还是在云中,都使用不同的运行器。 这种灵活性在需要在不同国家和合规区进行本地风险分析的情况下尤其重要,在这种情况下,敏感的财务数据和信息不能在本地边界之外传输。 使用 Apache Beam,汇丰可以轻松地在运行器之间切换,并可以为其数据处理未来做好准备,以应对任何变化。 汇丰在 Cloud Dataflow 中运行大部分工作流,得益于其强大的托管服务和自动扩展功能,可以管理每天两次运行批次管道时的峰值,高达 18,000 个 vCPU。 在一些国家,他们还使用 Apache Beam Flink 运行器来遵守与数据存储和处理相关的当地法规。
结果
Apache Beam 利用海量的金融市场数据和指标,生成数十亿笔交易估值,以扫描可行的未来情景,这些情景涵盖了大约 70 年,并将这些情景聚合到有意义的统计数据中,使汇丰能够模拟其未来情景,并定量地说明预测和决策中存在的风险。
使用 Apache Beam,汇丰工程师实现了数据处理性能的 2 倍增长,并将 XVA 批量管道的规模扩大了 100 倍,与原始解决方案相比。 Apache Beam 抽象开辟了一种在生产中实现 XVA 敏感性计算数值方法的方法,这在以前是不可能的。 批次 Apache Beam 管道计算数百个市场因素的 XVA 敏感性,每天处理约 400 TB 的内部数据,每月处理高达 5 PB 的数据。
Apache Beam 的可移植性使汇丰能够根据当地数据处理要求在不同地区使用不同的运行器,并为其数据处理未来做好准备,以应对监管变化。
Apache Beam 提供与高度优化的 C++ 计算组件的无缝集成和开箱即用的交互,这使汇丰节省了将多年积累的 C++ 分析重写为 Python 的工作量。
Apache Beam Python SDK 通过为汇丰的模型开发团队提供一种轻松构建新的 Python 管道的方法,将数学带到了编排级别。 Apache Beam 推动的全新工作结构将上市时间缩短了 24 倍,使汇丰团队能够在短短几周内将更改和新模型部署到生产环境中。
通过利用 Apache Beam 多功能且可扩展的特性来计算处理大型微分方程组和蒙特卡罗模拟的直接无环图,金融机构可以有效地评估和管理对手信用风险,即使在需要本地分析和严格遵守数据安全法规的情况下也是如此。
了解更多
这些信息对您有用吗?