




“Apache Beam 对我们来说是理想的解决方案。扩展、回填历史数据、尝试新的 ML 模型和新的用例……用 Beam 做这一切都很容易。”

“Apache Beam 使我们的数据科学家能够进行自助式 ML。他们可以插入代码片段,这些转换将自动附加到模型上,而无需任何工程参与。在几秒钟内,我们的数据科学团队就可以从实验转移到生产。”

自助机器学习工作流和使用 Apache Beam 扩展 MLOps
背景
Credit Karma 是一家美国跨国个人理财公司,成立于 2007 年,现在是 Intuit 的一部分。凭借免费的信用和财务管理平台,Credit Karma 通过为近 1.3 亿名会员提供个性化的财务见解和建议,帮助他们实现财务进步。
Credit Karma 的数据科学和工程团队利用机器学习为会员提供与每个会员的财务状况和目标相匹配的最相关内容和优惠。Credit Karma 的高级数据工程师 Avneesh Pratap 和 Raj Katakam 分享了 Apache Beam 如何帮助他们构建一个健壮、弹性和可扩展的数据和 ML 基础设施。他们还分享了统一的 Apache Beam 数据处理如何缩短尝试新 ML 管道并将其部署到生产环境之间的差距。
民主化和扩展 MLOps
2018 年之前,Credit Karma 使用基于 PHP 的 ETL 管道从多个金融服务合作伙伴摄取数据,执行不同的转换并将输出记录到他们自己的数据仓库中。随着合作伙伴和会员数量的不断增长,Credit Karma 的数据团队发现难以扩展他们的 MLOps。进行任何更改和尝试新的管道和属性都需要大量的工程开销。例如,仅接入一个新的合作伙伴就需要数周时间。他们的数据工程团队正在寻找方法来克服在摄取数据和对 ML 模型进行评分时的性能缺陷,并在同一管道中回填新功能。2018 年,Credit Karma 开始设计他们的新数据和 ML 平台 - Vega - 以跟上不断增长的规模,更好地了解会员,并通过高度个性化的优惠来提高他们对产品的参与度。
Apache Beam 作为统一分布式处理的行业标准,已成为 Vega 的核心。
当我们开始探索 Apache Beam 时,我们发现这种编程模型非常有希望。起初,我们只迁移了一个合作伙伴[到 Apache Beam 管道]。我们对结果印象深刻,并立即迁移到其他合作伙伴管道。
使用 Apache Beam Dataflow 运行器,Credit Karma 得益于 Google Cloud Dataflow 托管服务以确保更高的可扩展性和效率。Apache Beam 内置的 I/O 连接器 为各种接收器和来源提供原生支持,这使得 Credit Karma 可以将 Beam 无缝集成到他们的生态系统中,并与各种 Google Cloud 工具和服务集成,包括 Pub/Sub、BigQuery 和 Cloud Storage。
Credit Karma 利用 Apache Beam 内核和 Jupyter Notebook 在 Vega 中创建了一个探索性环境,并使他们的数据科学家能够在没有工程参与的情况下创建新的实验性数据管道。
Credit Karma 的数据科学家主要使用 SQL 和 Python 来创建新的管道。Apache Beam 提供强大的 用户定义函数,具有多种语言功能,允许在 Java 或 Scala 中编写标量或聚合函数,并在 SQL 查询中调用它们。为了使他们的数据科学团队能够使用 Scala 转换,Credit Karma 的工程师抽象出了 UDF、Tensorflow Transforms 和其他具有众多组件的复杂转换——可重复使用和可共享的“构建块”——来创建 Credit Karma 的数据和 ML 平台。Apache Beam 和自定义抽象允许数据科学家在创建实验性管道和转换时操作这些组件,这些组件可以在暂存和生产环境中轻松复制。Credit Karma 的数据科学团队将其代码更改提交到一个公共 GitHub 存储库,然后将管道合并到一个暂存环境中,并组合到一个生产应用程序中。
Apache Beam 抽象层在将假设和实验操作化为生产管道方面发挥着至关重要的作用,尤其是在处理财务和敏感信息时。Apache Beam 允许在将数据写入数据仓库之前,直接在数据管道内对数据进行掩盖和过滤。Credit Karma 使用 Apache Thrift 注释来标记列元数据,Apache Beam 管道根据 Thrift 注释从数据中过滤特定元素,然后再将其写入数据仓库。Credit Karma 的数据科学团队可以使用可用的抽象或在其之上编写数据转换来计算新的指标并验证 ML 模型,而无需查看实际数据。
Apache Beam 帮助我们“黑盒化”财务方面和不可公开的信息,以便团队可以处理成本和财务,而无需实际访问所有数据。
目前,大约有 20 个 Apache Beam 管道在生产环境中运行,超过 100 个实验性管道正在进行中。许多即将推出的实验性管道利用 Apache Beam 有状态处理,直接在流管道中计算用户聚合,而不是在数据仓库中计算它们。Credit Karma 的数据科学团队还计划利用 Beam SQL 直接在流处理管道中使用 SQL 语法,并轻松创建聚合。Apache Beam 对执行引擎的抽象和各种运行器允许 Credit Karma 使用不同引擎在模拟数据上测试数据管道性能,创建基准并比较不同数据生态系统的结果,以根据特定用例优化性能。
统一流和批处理数据摄取
Apache Beam 使 Credit Karma 能够彻底改造他们最重要的用例之一——数据摄取管道。Credit Karma 的许多合作伙伴通过网关将有关其金融产品和服务的 data 发送到 Pub/Sub,以便进行下游处理。用 Scio 编写的流式 Apache Beam 管道实时使用 Pub/Sub 主题,并处理深度嵌套的 JSON 数据,将其展平成数据库行格式。该管道还会对数据进行结构化和分区,然后将结果写入 BigQuery 数据仓库,以进行 ML 模型训练。
Apache Beam 统一的编程模型执行批处理和流式用例的业务逻辑,这使得 Credit Karma 可以开发一个统一的管道。数据摄取管道处理实时数据和批处理数据摄取,以将合作伙伴的历史数据回填到数据仓库中。Credit Karma 的一些合作伙伴使用 GCS 或 S3 等对象存储发送历史数据,而另一些则使用 Pub/Sub。Apache Beam 通过在同一管道中创建有界和 无界 PCollection 来统一批处理和流式处理,具体取决于用例。从批处理对象存储读取会创建一个有界 PCollection。从流式和持续更新的 Pub/Sub 读取会创建一个无界 PCollection。在仅为过去日期回填新功能的情况下,Credit Karma 的数据工程团队会配置相同的流式 Apache Beam 管道以按批处理方式处理合作伙伴发送的历史数据块:读取整个数据集一次,并将历史数据元素与特定日期的数据合并,在一个有限长度的作业中。
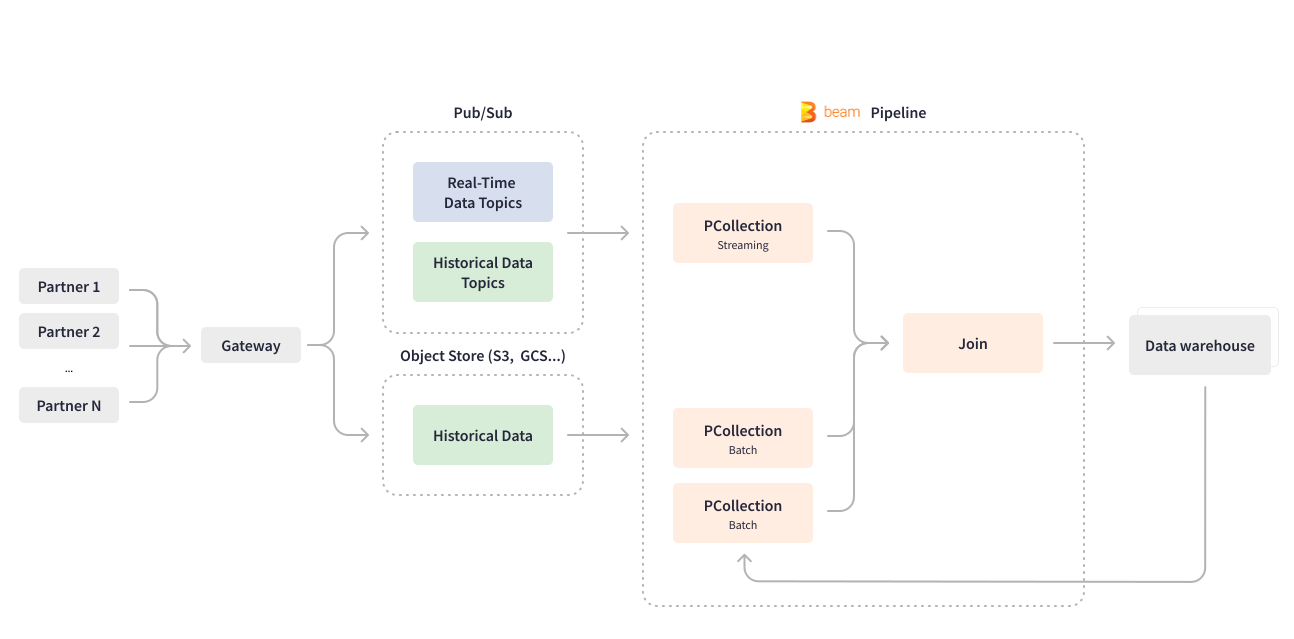
Apache Beam 很灵活,它的结构允许对管道进行通用编码,并易于配置以添加新的数据属性、来源和合作伙伴,而无需更改管道代码。Cloud Dataflow 服务提供了高级功能,例如动态 用新管道替换正在进行的流式作业。Apache Beam Dataflow 运行器使 Credit Karma 的数据工程团队能够部署管道代码更新,而无需耗尽正在进行的作业。
Credit Karma 为第三方数据提供商合作伙伴提供了一种方法,让他们可以部署自己的模型,以进行内部决策和预测。其中一些模型需要回填过去 3 到 8 个月的自定义属性,以便进行模型训练,这会产生巨大的数据峰值。Apache Beam 抽象层及其 Dataflow 运行器有助于在处理这些定期峰值时最大程度地减少基础设施管理工作。
使用 Apache Beam,您可以轻松添加复杂的处理逻辑,例如,您可以在处理时间上添加可配置的触发器。同时,Dataflow 运行器将为您管理执行,它会自动上传您的可执行代码和依赖项。并且您具有开箱即用的 Dataflow 自动缩放功能。您不必担心横向扩展。
目前,数据摄取管道处理和转换超过 1 亿条消息,以及定期回填,相当于大约 5-10 TB 的数据。
自助机器学习
在 Credit Karma,数据科学家处理数据建模和分析,对公司来说,赋予他们权力和灵活性,让他们能够轻松创建、测试和部署新模型至关重要。Apache Beam 提供了一个抽象,使数据科学家能够在原始特征空间上编写自己的转换,以实现高效的 ML 工程,同时使模型服务层独立于任何自定义代码。
Apache Beam 有助于自动化 Credit Karma 的机器展示工作流,链接和评分模型,以及准备用于 ML 模型训练的数据。Apache Beam 提供 Beam DataFrame API,以识别和实施所需的 预处理 步骤,以更快地迭代到生产环境。Apache Beam 的内置 I/O 转换允许原生读取和写入 TensorFlow TFRecord 文件,Credit Karma 利用这种连接来预处理数据、评分模型,并使用模型分数来推荐财务优惠和内容。
Apache Beam 使信用 Karma 能够处理海量数据,包括用于 预处理和模型验证 的数据,以及在预处理过程中进行数据实验。他们使用 TensorFlow Transforms 对数据进行批处理和实时模型推断的转换。TensorFlow Transforms 的输出被导出为 TensorFlow 图并附加到模型中,使预测服务独立于任何转换。信用 Karma 能够通过对原始数据进行实时转换来卸载预测服务的临时更改,而不是依赖需要数据工程团队参与的聚合数据。现在,他们的数据科学家可以在原始数据上使用 SQL 编写任何类型的转换,并部署新模型,而无需对基础设施进行任何更改。
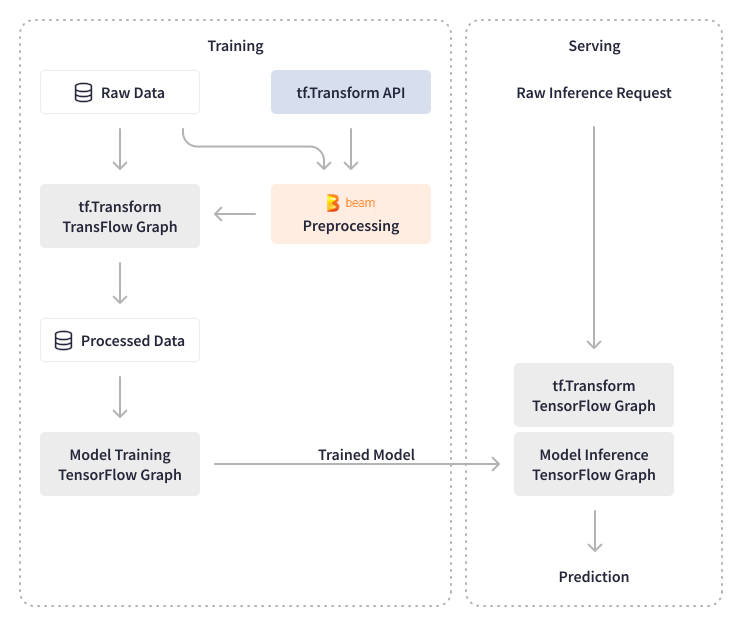
Apache Beam 和自定义抽象使信用 Karma 的数据科学团队能够创建新模型,特别是为信用 Karma 的推荐提供动力,而无需工程开销。数据科学家创建的代码片段会自动编译成 Airflow DAG,并部署到预发布沙盒,然后部署到生产环境。在模型训练和干扰方面,信用 Karma 的数据工程师使用基于 Apache Beam 的 Tensorflow 库 - TensorFlow Model Analysis (TFMA) 和 TensorFlow Data Validation (TFDV) - 来执行 ML 模型和特征的验证,并实现自动化的 ML 模型刷新。对于模型分析,他们利用原生的 Apache Beam 转换来计算统计数据,并构建了内部库转换,用于验证新模型的性能和准确性。例如,批处理 Apache Beam 管道计算 ML 模型的算法特征(分数)。
Apache Beam 为我们的数据科学家实现了自助式机器学习。他们可以插入代码片段,这些转换将自动附加到模型中,而无需任何工程参与。我们的数据科学团队可以在几秒钟内将 DAG 从实验迁移到生产,只需更改部署路径即可。
基于 Apache Beam 的 ML 管道已被证明非常可靠,每天处理超过 1 亿个事件,并使用最新数据更新 ML 模型。
启用实时数据可用性
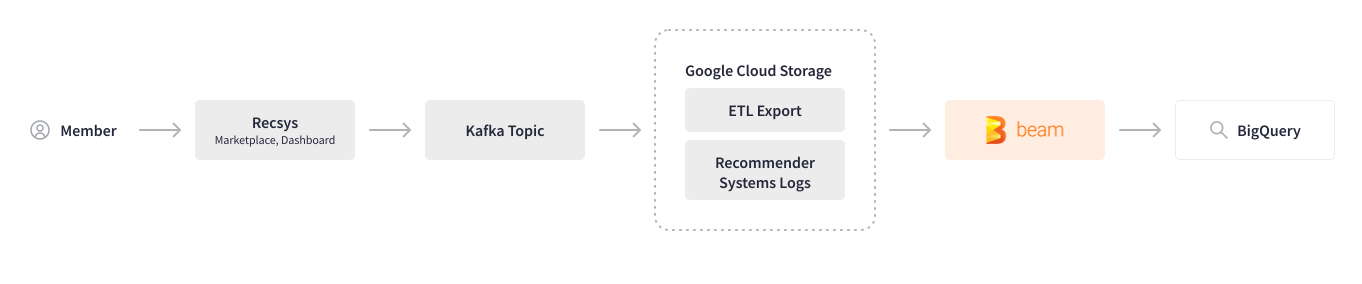
信用 Karma 利用机器学习分析用户行为,并推荐最相关的优惠和内容。在使用 Apache Beam 之前,跨多个系统收集用户行为(日志)需要大量的手动步骤和多个工具,这导致了处理性能下降,并且在每次需要更改时,团队之间都需要来回沟通。Apache Beam 有助于自动化此日志管道。跨系统用户会话日志记录在 Kafka 主题中,并存储在 Google Cloud Storage 中。用 Scio 编写的批处理 Apache Beam 管道解析特定跟踪 ID 的用户行为,转换和清理数据,并将其写入 BigQuery。
现在我们已经将日志管道迁移到 Apache Beam,我们对它的速度和性能非常满意,并且我们计划将这个批处理管道转换为流式管道。
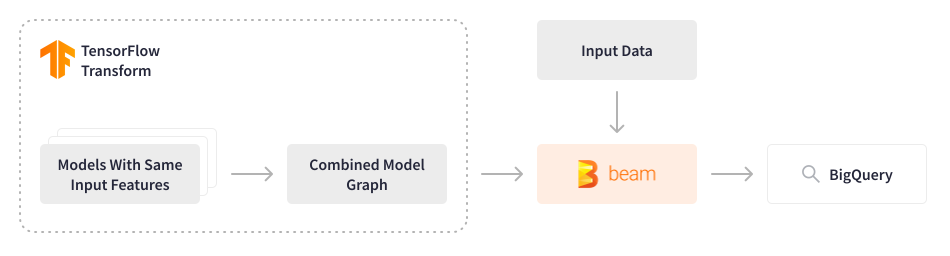
信用 Karma 的一部分 ML 模型为推荐提供动力并处理近 1.3 亿用户的數據,他们采用了 FinOps 文化,不断探索优化基础设施成本和提高处理性能的方法。信用 Karma 中使用的 Tensorflow 模型历来是逐个依次评分的,即使输入特征相同,这也导致了过度的计算成本。
Apache Beam 提供了一个重新考虑这种方法的机会。数据工程团队开发了一个 Apache Beam 批处理管道,该管道将多个 Tensorflow 模型合并到单个合并模型中,以 5,000 个事件/秒的速度处理过去 3-9 个月(~2-3 TB)的数据,并将输出存储在特征存储中。然后,这些特征用于轻量级模型,用于实时预测,以在会员登录平台的那一刻推荐相关内容。这种优雅的解决方案节省了计算资源,并大幅降低了相关成本,同时提高了处理性能。该配置是动态的,允许数据科学家无缝地进行实验和部署新模型。
结果
Apache Beam 使信用 Karma 的数据生态系统能够扩展和弹性,使他们能够管理由 200 个 ML 模型处理的 20,000 多个特征,每天为近 1.3 亿用户提供推荐。自采用 Apache Beam 以来,数据处理规模增长了 2 倍,他们的数据工程团队无需对基础设施进行任何重大更改。与使用 Apache Beam 之前需要几周的时间相比,加入新合作伙伴只需对管道进行最小的更改。Apache Beam 摄取管道将数据加载到仓库的时间从几天缩短到不到一小时,每天处理大约 5-10 TB 的数据。Apache Beam 批处理评分管道处理历史数据并为轻量级 ML 模型生成特征,从而为信用 Karma 会员提供实时体验。
Apache Beam 通过抽象基础设施的低级细节,并为统一的自服务 ML 工作流提供数据处理框架,为信用 Karma 打通了端到端数据科学流程和高效的 ML 工程。信用 Karma 的数据科学家现在可以对新模型进行实验,并将它们自动部署到生产环境中,而无需任何工程资源或基础设施更改。信用 Karma 在 Beam Summit 2022 上展示了他们使用 Apache Beam 构建自服务数据和 ML 平台以及扩展 MLOps 管道的经验。
影响
这些可扩展性计划使信用 Karma 能够为其会员提供以透明度、选择和个性化为基础的财务体验。人们的财务状况以及金融机构在批准消费者获取金融产品方面的资格标准始终处于波动状态,尤其是在经济不确定的时期。随着信用 Karma 不断扩展其数据生态系统,包括自动化的模型刷新,会员可以放心,当他们使用信用 Karma 时,他们可以更自信地购买金融产品,因为他们知道自己获得批准的可能性 - 无论时代多么不确定,这对会员和合作伙伴来说都是双赢的局面。
了解更多
Vega:使用 Apache Beam 和 Dataflow 在信用 Karma 中扩展 MLOps 管道
这些信息对您有帮助吗?