



博客
2016/05/27
我的 PCollection.map() 在哪里?
你是否曾经想过为什么 Beam 对所有内容都有 PTransforms,而不是在 PCollection 上拥有方法?看一下导致这种(和其他)设计决定的历史。
虽然 Beam 相对较新,但其设计借鉴了多年来对真实世界管道的经验。其中一个主要灵感来自 FlumeJava,它是 Google 内部在 2009 年首次推出的 MapReduce 的继任者。
原始的 FlumeJava API 在 PCollections 上具有诸如 count 和 parallelDo 之类的方法。虽然略微简洁,但这种方法在可扩展性方面有很多缺点。每个新用户都希望为 FlumeJava 添加转换,而将它们添加为 PCollection 的方法 simply doesn’t scale well. 相反,Beam 中的 PCollection 只有一个 apply 方法,它接受任何 PTransform 作为参数。
| FlumeJava | Beam |
|---|---|
PCollection<T> input = …
PCollection<O> output = input.count()
.parallelDo(...);
| PCollection<T> input = …
PCollection<O> output = input.apply(Count.perElement())
.apply(ParDo.of(...));
|
这是一种更可扩展的方法,原因如下。
在哪里划清界限?
向 PCollection 添加方法迫使我们在“有用”到足以值得这种特殊待遇的操作和不值得的操作之间划清界限。对 flat map、按键分组和按键合并来说很容易辩护。但过滤器呢?计数呢?近似计数呢?近似分位数呢?最常出现的内容呢?WriteToMyFavoriteSource 呢?如果沿着这条路走得太远,最终会导致一个包含几乎所有操作的单个庞大类。(FlumeJava 的 PCollection 类超过 5000 行,大约有 70 种不同的操作,如果我们接受每个建议,它可能更大得多。)此外,由于 Java 不允许向类添加方法,因此在添加到 PCollection 的操作和未添加到 PCollection 的操作之间存在明显的语法差异。一个传统的方式是使用函数库来共享代码,但函数(至少在像 Java 这样的传统语言中)是使用前缀样式编写的,这与流式构建器样式不兼容(例如 input.operation1().operation2().operation3() vs. operation3(operation1(input).operation2()))。
相反,在 Beam 中,我们选择了将所有转换(无论它们是基本操作、SDK 中捆绑的复合操作还是外部库的一部分)置于平等地位的样式。这也方便了可互换的替代实现(甚至可能采用不同的选项)。
| FlumeJava | Beam |
|---|---|
PCollection<O> output =
ExternalLibrary.doStuff(
MyLibrary.transform(input, myArgs)
.parallelDo(...),
externalLibArgs);
| PCollection<O> output = input
.apply(MyLibrary.transform(myArgs))
.apply(ParDo.of(...))
.apply(ExternalLibrary.doStuff(externalLibArgs));
|
可配置性
让值(PCollections)成为传递和操作的对象(即延迟执行图的句柄)是一种流畅的风格,但操作本身需要是可组合、可配置和可扩展的。在操作中使用 PCollection 方法在这里效果不好,尤其是在没有默认参数或关键字参数的语言中。例如,ParDo 操作可以有任意数量的边输入和边输出,或者写入操作可能具有处理编码和压缩的配置。一种选择是将这些操作分成多个重载,甚至方法,但这会加剧上述问题。(FlumeJava 演化出 parallelDo 方法的十多个重载!)另一种选择是为每个方法传递一个配置对象,该配置对象可以使用更流畅的习语(如构建器模式)来构建,但在这一点上,人们可能不如将配置对象本身视为操作,这就是 Beam 所做的。
类型安全
许多操作只能应用于元素类型为特定类型的集合。例如,GroupByKey 操作应该只应用于 PCollection<KV<K, V>>s。至少在 Java 中,无法仅根据元素类型参数来限制方法。在 FlumeJava 中,这导致我们添加了一个 PTable<K, V> 子类,它继承自 PCollection<KV<K, V>>,以包含特定于键值对 PCollections 的所有操作。这会带来同样的问题,即哪些元素类型足够特殊,值得用 PCollection 子类来捕捉。这对第三方来说不可扩展,通常需要手动向下转换/转换(在 Java 中无法安全地链接)以及产生这些 PCollection 特殊化的特殊操作。
这对元素类型与其输入的元素类型相同(或相关)的转换来说尤其不方便,需要额外的支持来生成正确的子类(例如,对 PTable 的过滤器应该产生另一个 PTable,而不仅仅是键值对的原始 PCollection)。
使用 PTransforms 使我们能够绕过整个问题。我们可以根据转换输入的类型,对转换可能使用的上下文施加任意约束;例如,GroupByKey 静态类型化,只能应用于 PCollection<KV<K, V>>。这种方式可以推广到任意形状,而无需引入像 PTable 这样的专门类型。
可重用性和结构
虽然 PTransforms 通常是在它们使用的地方构造的,但通过将它们提取为独立的对象,就可以存储它们并将它们传递出去。
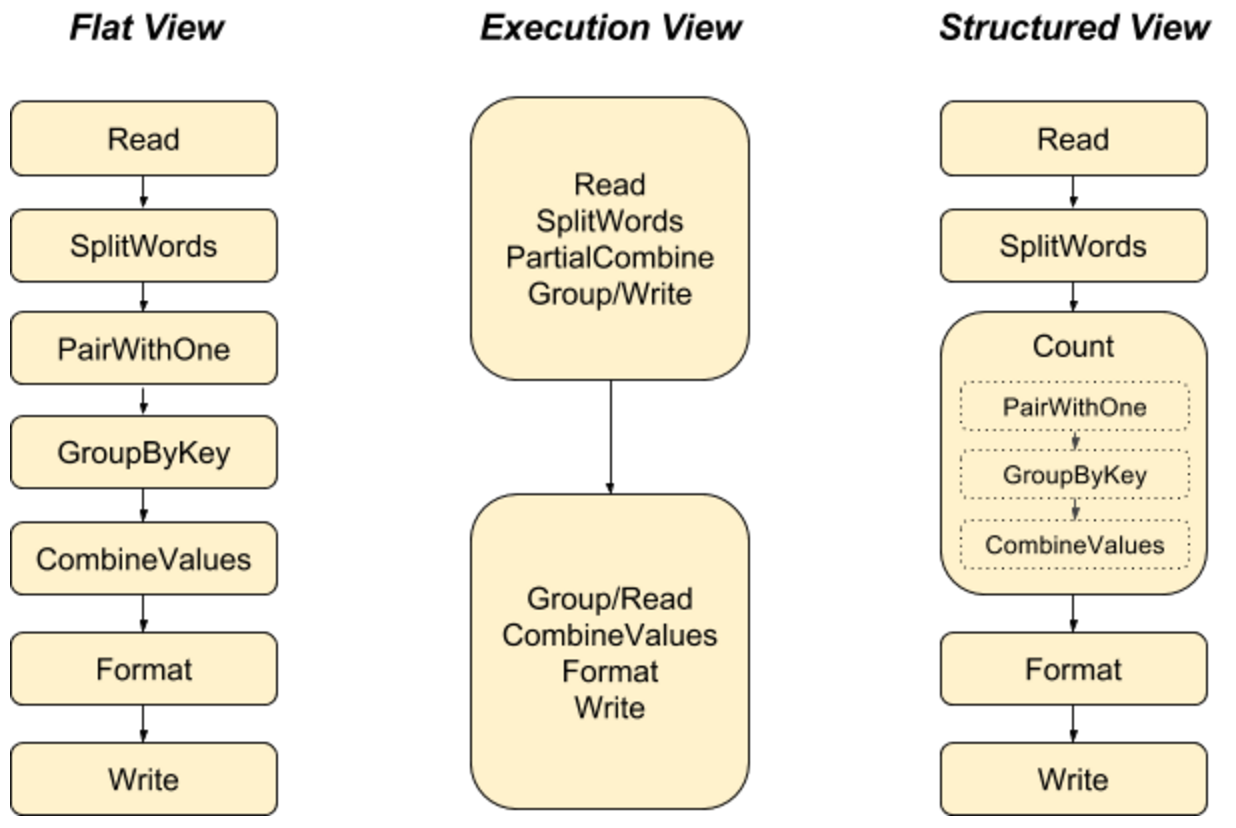
随着管道的发展和演变,将管道构建成模块化、通常可重用的组件非常有用,而 PTransforms 允许人们在数据处理管道中很好地做到这一点。此外,模块化 PTransforms 还将代码的逻辑结构暴露给系统(例如,用于监控)。在下面三种不同的 WordCount 管道表示形式中,只有结构化视图捕获了管道的总体意图。即使让简单的操作成为 PTransforms 也意味着将事物打包成复合操作的边缘不再那么突然了。
总结
虽然向 PCollections 添加方法很诱人,但这种方法不可扩展、不可扩展,也缺乏足够的表达能力。在 PCollection 上放置一个 apply 方法,并将所有逻辑放在操作本身中,让我们可以同时拥有两全其美的优点,并避免由于在简单和复杂管道之间以及预定义和用户定义操作之间采用单一一致的风格而造成的复杂性陡峭的边缘。