



博客
2017/08/28
Apache Beam 的及时(且有状态)处理
在我的一篇之前的博文中,我介绍了 Apache Beam 中有状态处理的基础知识,重点介绍了向每个元素处理添加状态。所谓及时处理是对 Beam 中有状态处理的补充,它允许您设置计时器以在将来某个时间请求(有状态)回调。
在 Beam 中,您可以用计时器做什么?以下是一些示例
- 您可以在处理一段时间后输出缓冲在状态中的数据。
- 当水印估计您已接收到所有数据(直到事件时间中的某个特定点)时,您可以采取特殊措施。
- 您可以创建具有超时的工作流,这些工作流会根据在一段时间内没有额外的输入而更改状态并在响应中发出输出。
这些只是一些可能性。状态和计时器一起形成了一个强大的编程范例,可以进行细粒度控制以表达各种各样的工作流。Beam 中的有状态和及时处理可跨数据处理引擎移植,并与 Beam 在流式处理和批处理中统一的事件时间窗口模型集成。
什么是基于状态和基于时间的处理?
在我之前的文章中,我通过与关联、可交换组合器的对比,理解了基于状态的处理。在这篇文章中,我将重点介绍一个我之前只简要提到的观点:即具有每个键和窗口状态以及计时器的元素级处理代表了一种“令人尴尬地并行”计算的基本模式,不同于 Beam 中的其他模式。
事实上,基于状态和基于时间的计算是其他模式的基础的底层计算模式。正因为它是低级的,它允许您真正微观管理您的计算以解锁新的用例和效率。这需要您手动管理状态和计时器 - 这不是魔法!让我们首先再次看一下 Beam 中的两种主要计算模式。
元素级处理(ParDo、Map 等)
最基本令人尴尬地并行模式只是使用一堆计算机对大型集合的每个输入元素应用相同的功能。在 Beam 中,这种按元素处理表示为一个基本 ParDo - 与 MapReduce 中的“Map”类似 - 它类似于函数式编程中增强的“map”、“flatMap”等。
下图说明了按元素处理。输入元素是正方形,输出元素是三角形。元素的颜色代表它们的键,这将在后面发挥作用。每个输入元素完全独立地映射到相应的输出元素。处理可以在任何方式的计算机上分布,从而产生几乎无限的并行性。
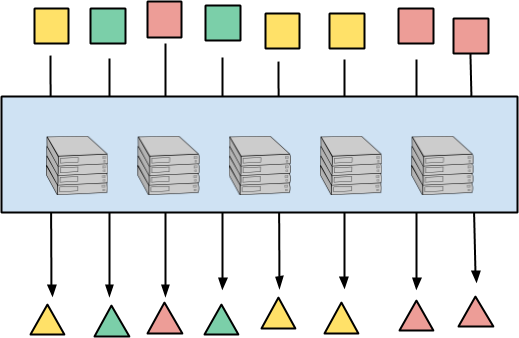
这种模式很明显,存在于所有数据并行范式中,并且有一个简单的无状态实现。每个输入元素可以独立处理或以任意捆绑处理。在计算机之间平衡工作实际上是困难的部分,可以通过拆分、进度估计、工作窃取等方法解决。
按键(和窗口)聚合(Combine、Reduce、GroupByKey 等)
Beam 核心中的另一个令人尴尬地并行设计模式是按键(和窗口)聚合。共享一个键的元素会放在一起,然后使用某个关联和可交换运算符进行组合。在 Beam 中,这表示为 GroupByKey 或 Combine.perKey,对应于 MapReduce 中的洗牌和“Reduce”。有时将按键 Combine 视为基本操作,并将原始 GroupByKey 视为仅连接输入元素的组合器是有帮助的。输入元素的通信模式相同,只是针对 Combine 可能有一些优化。
在下面的图示中,请记住每个元素的颜色代表键。因此,所有红色方块都被路由到同一个位置,在那里它们被聚合,红色三角形是输出。黄色和绿色方块也是如此。在实际应用程序中,您可能拥有数百万个键,因此并行性仍然非常大。
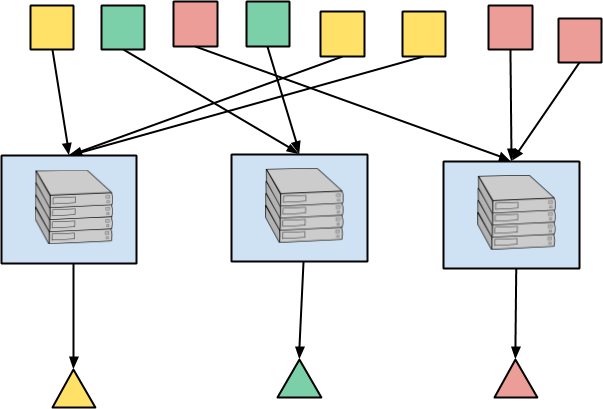
在抽象级别上,底层数据处理引擎将使用状态来执行跨所有到达某个键的元素的聚合。特别是,在流式执行中,聚合过程可能需要等待更多数据到达,或等待水印估计某个事件时间窗口的所有输入已完成。这需要某种方法来存储输入元素之间的中间聚合,以及在需要发出结果时接收回调的方法。因此,流式处理引擎按键聚合的执行从根本上涉及状态和计时器。
但是,您的代码只是聚合运算符的声明性表达式。运行器可以选择多种方法来执行您的运算符。我在之前专注于状态的文章中详细介绍了这一点。由于您不会以任何定义的顺序观察元素,也不会直接操作可变状态或计时器,因此我称之为非基于状态和非基于时间的处理。
按键和窗口的基于状态和基于时间的处理
ParDo 和 Combine.perKey 都是数十年前用于并行的标准模式。当在大型分布式数据处理引擎中实现这些模式时,我们可以突出显示一些特别重要的特征。
让我们考虑 ParDo 的这些特征
- 您编写单线程代码来处理一个元素。
- 元素以任意顺序处理,元素的处理之间没有依赖关系或交互作用。
以及 Combine.perKey 的这些特征
- 用于公共键和窗口的元素被收集在一起。
- 用户定义的运算符将应用于这些元素。
通过组合无限制并行映射和按键和窗口组合的一些特征,我们可以识别出构建基于状态和基于时间的处理的元基元
- 用于公共键和窗口的元素被收集在一起。
- 元素以任意顺序处理。
- 您编写单线程代码来处理一个元素或计时器,可能访问状态或设置计时器。
在下图中,红色方块被收集并逐个馈送到基于状态、基于时间、DoFn。当处理每个元素时,DoFn 能够访问状态(右侧的彩色分隔圆柱体)并可以设置计时器以接收回调(左侧的彩色时钟)。
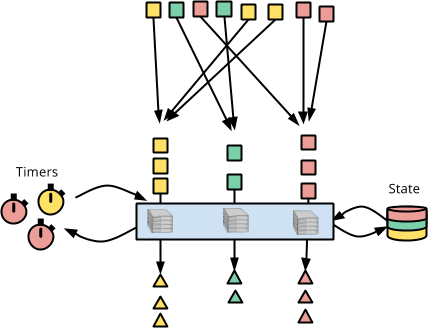
这就是 Apache Beam 中按键和窗口的基于状态、基于时间的处理的抽象概念。现在让我们看看编写访问状态、设置计时器和接收回调的代码是什么样子。
示例:批处理 RPC
为了演示基于状态和基于时间的处理,让我们使用代码逐步完成一个具体示例。
假设您正在编写一个用于分析事件的系统。您有大量数据进来,需要通过 RPC 对外系统进行丰富以完善每个事件。您不能只为每个事件发出一个 RPC。这样做不仅性能很差,而且还可能超出您与外部系统配额。因此,您希望收集一些事件,对它们进行一次 RPC,然后输出所有丰富的事件。
状态
让我们设置我们需要跟踪元素批次的状态。每个元素进来时,我们将其写入缓冲区,同时跟踪我们缓冲的元素数量。以下是代码中的状态单元
new DoFn<Event, EnrichedEvent>() {
@StateId("buffer")
private final StateSpec<BagState<Event>> bufferedEvents = StateSpecs.bag();
@StateId("count")
private final StateSpec<ValueState<Integer>> countState = StateSpecs.value();
… TBD …
}class StatefulBufferingFn(beam.DoFn):
BUFFER_STATE = BagStateSpec('buffer', EventCoder())
COUNT_STATE = CombiningValueStateSpec('count',
VarIntCoder(),
combiners.SumCombineFn())逐步浏览代码,我们有
- 状态单元
"buffer"是一个无序的缓冲事件包。 - 状态单元
"count"跟踪缓冲了多少个事件。
接下来,回顾一下读写状态,让我们编写 @ProcessElement 方法。我们将选择缓冲区大小的限制,MAX_BUFFER_SIZE。如果缓冲区达到此大小,我们将执行一个 RPC 来丰富所有事件并输出。
new DoFn<Event, EnrichedEvent>() {
private static final int MAX_BUFFER_SIZE = 500;
@StateId("buffer")
private final StateSpec<BagState<Event>> bufferedEvents = StateSpecs.bag();
@StateId("count")
private final StateSpec<ValueState<Integer>> countState = StateSpecs.value();
@ProcessElement
public void process(
ProcessContext context,
@StateId("buffer") BagState<Event> bufferState,
@StateId("count") ValueState<Integer> countState) {
int count = firstNonNull(countState.read(), 0);
count = count + 1;
countState.write(count);
bufferState.add(context.element());
if (count >= MAX_BUFFER_SIZE) {
for (EnrichedEvent enrichedEvent : enrichEvents(bufferState.read())) {
context.output(enrichedEvent);
}
bufferState.clear();
countState.clear();
}
}
… TBD …
}class StatefulBufferingFn(beam.DoFn):
MAX_BUFFER_SIZE = 500;
BUFFER_STATE = BagStateSpec('buffer', EventCoder())
COUNT_STATE = CombiningValueStateSpec('count',
VarIntCoder(),
combiners.SumCombineFn())
def process(self, element,
buffer_state=beam.DoFn.StateParam(BUFFER_STATE),
count_state=beam.DoFn.StateParam(COUNT_STATE)):
buffer_state.add(element)
count_state.add(1)
count = count_state.read()
if count >= MAX_BUFFER_SIZE:
for event in buffer_state.read():
yield event
count_state.clear()
buffer_state.clear()以下是一个用于配合代码的图示
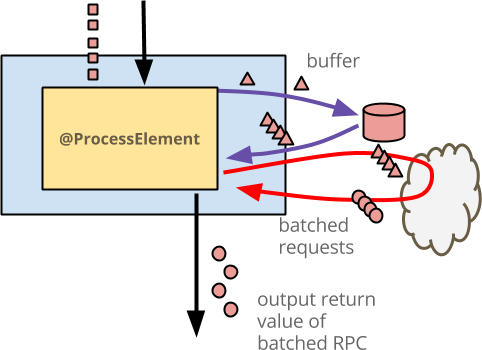
- 蓝色框是
DoFn。 - 它内部的黄色框是
@ProcessElement方法。 - 每个输入事件都是一个红色方块 - 此图仅显示单个键(由颜色红色表示)的活动。您的
DoFn将并行地为所有键运行相同的工作流,这些键可能代表用户 ID。 - 每个输入事件都写入缓冲区作为红色三角形,这代表您可能实际缓冲的内容可能不仅仅是原始输入,即使此代码没有这样做。
- 外部服务以云的形式绘制。当有足够的缓冲事件时,
@ProcessElement方法从状态中读取事件并发出一个 RPC。 - 每个输出的丰富事件都以红色圆圈绘制。对于此输出的使用者,它看起来就像按元素操作。
到目前为止,我们只使用了状态,但没有使用计时器。您可能已经注意到,存在一个问题 - 缓冲区中通常会有剩余数据。如果不再有输入到达,则这些数据将永远不会被处理。在 Beam 中,每个窗口在事件时间中都有一些点,在此之后,该窗口的任何进一步输入都被认为太晚而被丢弃。此时,我们说该窗口已“过期”。由于不再有输入到达以访问该窗口的状态,因此该状态也会被丢弃。对于我们的示例,我们需要确保所有剩余事件在窗口过期时输出。
事件时间计时器
事件时间计时器在输入 PCollection 的水印达到某个阈值时请求回调。换句话说,您可以使用事件时间计时器在事件时间的特定时刻采取操作 - PCollection 的特定完成点 - 例如,当窗口过期时。
对于我们的示例,让我们添加一个事件时间计时器,以便在窗口过期时,处理缓冲区中剩余的任何事件。
new DoFn<Event, EnrichedEvent>() {
…
@TimerId("expiry")
private final TimerSpec expirySpec = TimerSpecs.timer(TimeDomain.EVENT_TIME);
@ProcessElement
public void process(
ProcessContext context,
BoundedWindow window,
@StateId("buffer") BagState<Event> bufferState,
@StateId("count") ValueState<Integer> countState,
@TimerId("expiry") Timer expiryTimer) {
expiryTimer.set(window.maxTimestamp().plus(allowedLateness));
… same logic as above …
}
@OnTimer("expiry")
public void onExpiry(
OnTimerContext context,
@StateId("buffer") BagState<Event> bufferState) {
if (!bufferState.isEmpty().read()) {
for (EnrichedEvent enrichedEvent : enrichEvents(bufferState.read())) {
context.output(enrichedEvent);
}
bufferState.clear();
}
}
}class StatefulBufferingFn(beam.DoFn):
…
EXPIRY_TIMER = TimerSpec('expiry', TimeDomain.WATERMARK)
def process(self, element,
w=beam.DoFn.WindowParam,
buffer_state=beam.DoFn.StateParam(BUFFER_STATE),
count_state=beam.DoFn.StateParam(COUNT_STATE),
expiry_timer=beam.DoFn.TimerParam(EXPIRY_TIMER)):
expiry_timer.set(w.end + ALLOWED_LATENESS)
… same logic as above …
@on_timer(EXPIRY_TIMER)
def expiry(self,
buffer_state=beam.DoFn.StateParam(BUFFER_STATE),
count_state=beam.DoFn.StateParam(COUNT_STATE)):
events = buffer_state.read()
for event in events:
yield event
buffer_state.clear()
count_state.clear()让我们拆解这段代码片段
我们使用
@TimerId("expiry")声明一个事件时间计时器。我们将使用标识符"expiry"来识别计时器,以设置回调时间以及接收回调。变量
expiryTimer使用@TimerId注解,其值为TimerSpecs.timer(TimeDomain.EVENT_TIME),表示我们希望根据输入元素的事件时间水位线来触发回调。在
@ProcessElement元素中,我们使用@TimerId("expiry")注解了一个名为Timer的参数。Beam 运行器会自动提供此Timer参数,通过它我们可以设置(和重置)计时器。重复重置计时器成本很低,因此我们只需在每个元素上设置它即可。我们定义了
onExpiry方法,使用@OnTimer("expiry")注解,该方法执行最终的事件丰富 RPC 并输出结果。Beam 运行器通过匹配其标识符将回调传递给此方法。
下图展示了此逻辑。
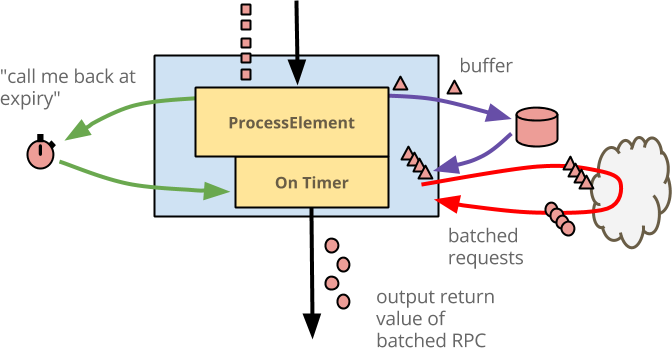
@ProcessElement和@OnTimer("expiry")方法都执行对缓冲状态的相同访问,执行相同的批量 RPC,并输出丰富的元素。
现在,如果我们以流式实时方式执行此操作,我们仍然可能对特定缓冲数据有无限延迟。如果水位线推进非常缓慢,或者事件时间窗口被选为非常大,那么在根据足够多的元素或窗口到期发出输出之前,可能会经过很多时间。我们还可以使用计时器来限制处理缓冲元素之前的挂钟时间量,即处理时间。我们可以选择合理的时间量,以便即使我们发出的 RPC 并不像它们可能的那样大,但仍然足够少,以避免用外部服务耗尽我们的配额。
处理时间计时器
处理时间(管道执行时经过的时间)中的计时器直观地很简单:您希望等待一定时间,然后收到回调。
为了完善我们的示例,我们将尽快设置一个处理时间计时器,只要有数据被缓冲。请注意,我们只在当前缓冲区为空时设置计时器,这样我们就不会不断地重置计时器。当第一个元素到达时,我们将计时器设置为当前时刻加上MAX_BUFFER_DURATION。在分配的处理时间过去后,将触发回调并丰富并发出任何缓冲的元素。
new DoFn<Event, EnrichedEvent>() {
…
private static final Duration MAX_BUFFER_DURATION = Duration.standardSeconds(1);
@TimerId("stale")
private final TimerSpec staleSpec = TimerSpecs.timer(TimeDomain.PROCESSING_TIME);
@ProcessElement
public void process(
ProcessContext context,
BoundedWindow window,
@StateId("count") ValueState<Integer> countState,
@StateId("buffer") BagState<Event> bufferState,
@TimerId("stale") Timer staleTimer,
@TimerId("expiry") Timer expiryTimer) {
if (firstNonNull(countState.read(), 0) == 0) {
staleTimer.offset(MAX_BUFFER_DURATION).setRelative();
}
… same processing logic as above …
}
@OnTimer("stale")
public void onStale(
OnTimerContext context,
@StateId("buffer") BagState<Event> bufferState,
@StateId("count") ValueState<Integer> countState) {
if (!bufferState.isEmpty().read()) {
for (EnrichedEvent enrichedEvent : enrichEvents(bufferState.read())) {
context.output(enrichedEvent);
}
bufferState.clear();
countState.clear();
}
}
… same expiry as above …
}class StatefulBufferingFn(beam.DoFn):
…
STALE_TIMER = TimerSpec('stale', TimeDomain.REAL_TIME)
MAX_BUFFER_DURATION = 1
def process(self, element,
w=beam.DoFn.WindowParam,
buffer_state=beam.DoFn.StateParam(BUFFER_STATE),
count_state=beam.DoFn.StateParam(COUNT_STATE),
expiry_timer=beam.DoFn.TimerParam(EXPIRY_TIMER),
stale_timer=beam.DoFn.TimerParam(STALE_TIMER)):
if count_state.read() == 0:
# We set an absolute timestamp here (not an offset like in the Java SDK)
stale_timer.set(time.time() + StatefulBufferingFn.MAX_BUFFER_DURATION)
… same logic as above …
@on_timer(STALE_TIMER)
def stale(self,
buffer_state=beam.DoFn.StateParam(BUFFER_STATE),
count_state=beam.DoFn.StateParam(COUNT_STATE)):
events = buffer_state.read()
for event in events:
yield event
buffer_state.clear()
count_state.clear()以下是对最终代码的说明
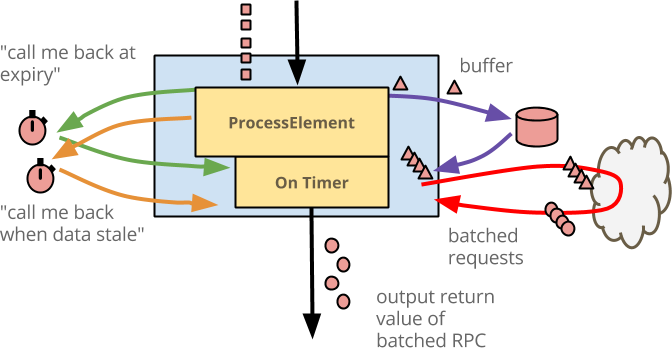
回顾整个逻辑
- 当事件到达
@ProcessElement时,它们被缓冲在状态中。 - 如果缓冲区的大小超过最大值,则事件会被丰富并输出。
- 如果缓冲区填充太慢,并且事件在达到最大值之前变得过时,则计时器会触发回调,该回调会丰富缓冲的事件并输出。
- 最后,当任何窗口即将到期时,该窗口中缓冲的任何事件都会在该窗口的状态被丢弃之前被处理并输出。
最终,我们得到一个完整的示例,它使用状态和计时器来显式地管理 Beam 中性能敏感转换的低级细节。随着我们添加越来越多的功能,我们的DoFn实际上变得相当大。这是有状态、及时处理的一个正常特征。您实际上是在深入挖掘并管理大量细节,而这些细节在您使用 Beam 的高级 API 表达逻辑时会自动处理。从这些额外的努力中,您可以获得解决用例和实现效率的能力,而这些用例和效率在其他情况下可能无法实现。
Beam 统一模型中的状态和计时器
Beam 用于跨流式和批处理处理的事件时间的统一模型对状态和计时器有新颖的意义。通常,您不需要对有状态、及时的DoFn做任何事情,它就能在 Beam 模型中正常工作。但了解以下注意事项会有所帮助,尤其是如果您之前在 Beam 之外使用过类似的功能。
事件时间窗口“自动工作”
Beam 的存在理由之一是正确处理乱序事件数据,而这几乎是所有事件数据。Beam 解决乱序数据的方案是事件时间窗口,其中事件时间的窗口会产生正确的结果,无论用户选择什么窗口,或者事件以什么顺序到达。
如果您编写了一个有状态、及时的转换,那么它应该无论周围管道如何选择对事件时间进行窗口化,都能正常工作。如果管道选择一小时的固定窗口(有时称为翻滚窗口)或以 10 分钟为步长滑动 30 分钟的窗口,有状态、及时的转换应该能够透明地正确地工作。
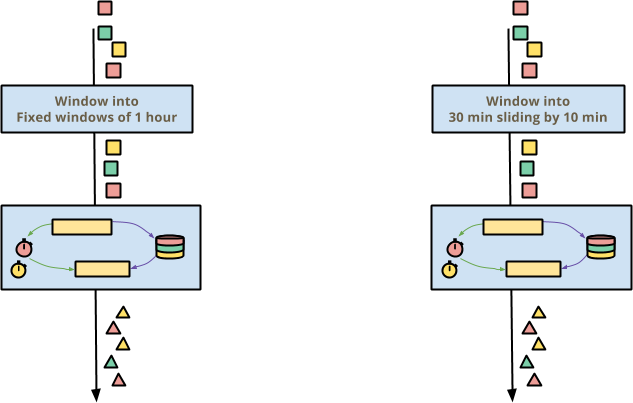
这在 Beam 中自动生效,因为状态和计时器按键和窗口进行分区。在每个键和窗口内,有状态、及时的处理基本上是独立的。作为额外的好处,事件时间的推移(即水位线的推进)允许在窗口到期时自动释放不可到达的状态,因此您通常不必担心清除旧状态。
统一的实时和历史处理
Beam 语义模型的第二个原则是在批处理和流式处理之间必须统一处理。这种统一的一个重要用例是能够对实时事件流和同一事件的存档存储应用相同的逻辑。
存档数据的共同特点是它可能以极度乱序的方式到达。存档文件的碎片化通常会导致处理顺序与近实时事件到达时的顺序完全不同。从您的管道来看,这些数据也都是可用的,因此会立即传递。无论是在过去的数据上运行实验,还是重新处理过去的结果以修复数据处理错误,您的处理逻辑能够轻松地应用于存档事件,就像应用于传入的近实时数据一样,这一点至关重要。
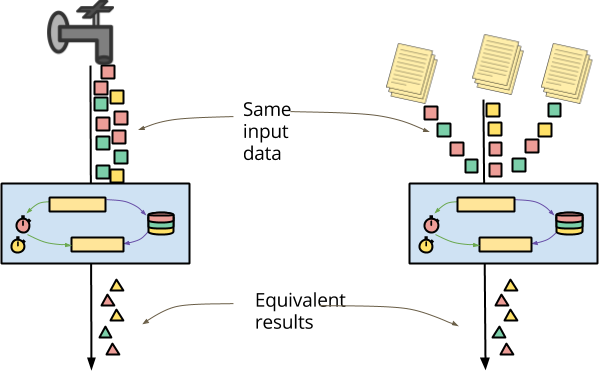
可以(有意地)编写一个有状态、及时的 DoFn,它提供的结果取决于顺序或传递时间,因此从这个意义上来说,您(DoFn 作者)需要承担额外的责任,以确保这种不确定性在文档允许的范围内。
去使用它!
我将以与上次结束相同的方式结束这篇文章。我希望您能尝试使用 Beam 进行有状态、及时的处理。如果它为您打开了新的可能性,那就太好了!如果不是,我们希望听到您的反馈。由于这是一个新功能,请查看功能矩阵,了解您首选的 Beam 后端(s)的 поддерживает уровень.
并请加入 Beam 社区,在 user@beam.apache.org,并在 Twitter 上关注@ApacheBeam。