



博客
2017/02/13
Apache Beam 的有状态处理
Beam 允许您使用可移植的高级管道处理无界、乱序、全球范围的数据。有状态处理是 Beam 模型的一项新功能,它扩展了 Beam 的功能,开辟了新的用例和新的效率。在这篇文章中,我将指导您完成 Beam 中的有状态处理:它如何工作,它如何与 Beam 模型的其他功能相适应,您可能会使用它做什么,以及它在代码中的样子。
注意:这篇文章已于 2019 年 5 月更新,以包含 Python 代码片段!
警告:前方有新功能!:这是 Beam 模型中一个非常新的方面。运行器仍在添加支持。您可以今天在多个运行器上试用它,但请查看 运行器功能矩阵 以了解每个运行器的当前状态。
首先,快速回顾一下:在 Beam 中,一个大数据处理管道是一个有向无环图,由称为PTransforms 的并行操作组成,这些操作处理来自PCollections 的数据。我将通过逐步介绍这个插图来扩展这一点。
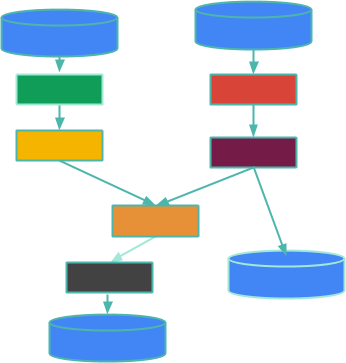
方框是PTransforms,边表示从一个PTransform 流到下一个PTransform 的PCollections 中的数据。一个PCollection 可能是有界的(这意味着它是有限的,并且您知道它)或无界的(这意味着您不知道它是有限的还是无限的 - 基本上,它就像一个可能永远不会终止的传入数据流)。圆柱体是您管道边缘的数据源和接收器,例如有界日志文件集合或通过 Kafka 主题无界数据流。这篇博客文章不是关于源或接收器,而是关于它们之间发生的事情 - 您的数据处理。
Beam 中处理数据的两个主要构建块是:ParDo,用于对所有元素并行执行操作,以及GroupByKey(以及我很快将谈到的密切相关的CombinePerKey),用于聚合您已分配相同键的元素。在下图(出现在我们许多演示文稿中)中,颜色表示元素的键。因此,GroupByKey/CombinePerKey 变换收集所有绿色方块以生成单个输出元素。
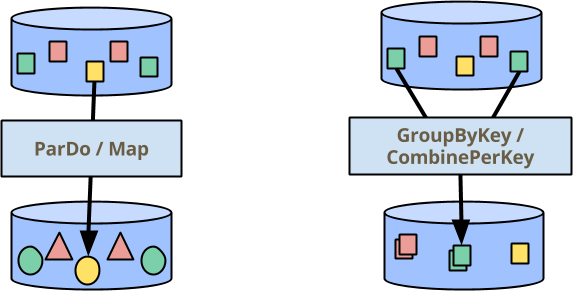
但并非所有用例都容易表示为简单 ParDo/Map 和 GroupByKey/CombinePerKey 变换的管道。这篇博客文章的主题是 Beam 编程模型的新扩展:使用可变状态增强每个元素的操作。
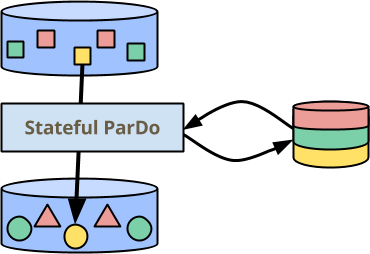
在上图中,ParDo 现在在旁边有一点持久、一致的状态,可以在处理每个元素时读取和写入它。状态按键进行分区,因此它被绘制为每个颜色都有独立的部分。它也按窗口进行分区,但我认为格子 ![]() 会有点过分:-)。我将在稍后通过我的第一个例子谈论为什么状态以这种方式进行分区。
会有点过分:-)。我将在稍后通过我的第一个例子谈论为什么状态以这种方式进行分区。
在本帖的剩余部分,我将详细介绍 Beam 的这项新功能 - 它在高级别上的工作原理,它与现有功能的不同之处,以及如何确保它仍然具有大规模可扩展性。在模型级别的介绍之后,我将逐步介绍一个如何在 Beam Java SDK 中使用它的简单示例。
Beam 中的有状态处理是如何工作的?
您的 ParDo 变换的处理逻辑通过它应用于每个元素的 DoFn 来表达。在没有有状态增强的情况下,DoFn 是一个主要由输入到一个或多个输出的纯函数组成,对应于 MapReduce 中的 Mapper。有了状态,DoFn 能够在处理每个输入元素时访问持久可变状态。请考虑这个插图
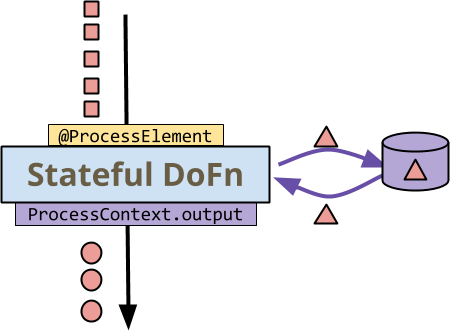
首先要注意的是所有数据 - 小方块、圆圈和三角形 - 都是红色的。这是为了说明有状态处理发生在单个键的上下文中 - 所有元素都是具有相同键的键值对。您选择的 Beam 运行器对 DoFn 的调用用黄色表示,而 DoFn 对运行器的调用用紫色表示。
- 运行器为每个键+窗口调用
DoFn的@ProcessElement方法。 DoFn读取和写入状态 - 到/从侧面存储的弯曲箭头。DoFn像往常一样通过ProcessContext.output(分别为ProcessContext.sideOutput)向运行器发出输出(或侧输出)。
在如此高的层次上,它非常直观:在您的编程经验中,您可能在某个时候写了一个循环遍历元素,在执行其他操作的同时更新了一些可变变量。有趣的问题是如何将其融入 Beam 模型:它如何与其他功能相关联?它如何扩展,因为状态意味着某种同步?什么时候应该使用它,而不是其他功能?
有状态处理如何融入 Beam 模型?
要了解有状态处理如何融入 Beam 模型,请考虑另一种在处理许多元素时可以保留一些“状态”的方法:CombineFn。在 Beam 中,您可以在 Java 或 Python 中编写 Combine.perKey(CombineFn),以对具有共同键(和窗口)的所有元素应用关联、可交换的累积操作。
这是一个图,说明了 CombineFn 的基础知识,这是运行器可能在每键基础上调用它的最简单方法,以构建累加器并从最终累加器中提取输出。
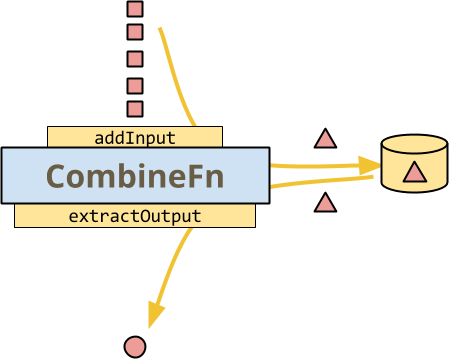
与有状态 DoFn 的插图一样,所有数据都是红色的,因为这是对单个键的 Combine 的处理。图示方法调用用黄色表示,因为它们都由运行器控制:运行器对每个方法调用 addInput 将其添加到当前累加器中。
- 运行器在选择时会持久化累加器。
- 运行器在准备发出输出元素时调用
extractOutput。
此时,CombineFn 的图看起来非常像有状态 DoFn 的图。实际上,数据的流动确实非常相似。但即使如此,也存在重要的差异。
- 运行器控制这里的所有调用和存储。您不能决定何时或如何持久化状态,何时丢弃累加器(基于触发),或何时从累加器中提取输出。
- 您只能拥有一个状态 - 累加器。在有状态的 DoFn 中,您只能读取您需要知道的内容,并写入已更改的内容。
- 您没有
DoFn的扩展功能,例如每个输入的多个输出或侧输出。(这些可以通过足够复杂的累加器来模拟,但这不自然也不高效。DoFn的一些其他功能,如侧输入和对窗口的访问,对于CombineFn来说非常有意义)
但CombineFn 允许运行器执行的主要事情是mergeAccumulators,这是CombineFn 的关联性的具体表达。这打开了一些巨大的优化:运行器可以在多个输入上调用 CombineFn 的多个实例,然后在经典的分治架构中将它们组合在一起,如下图所示。
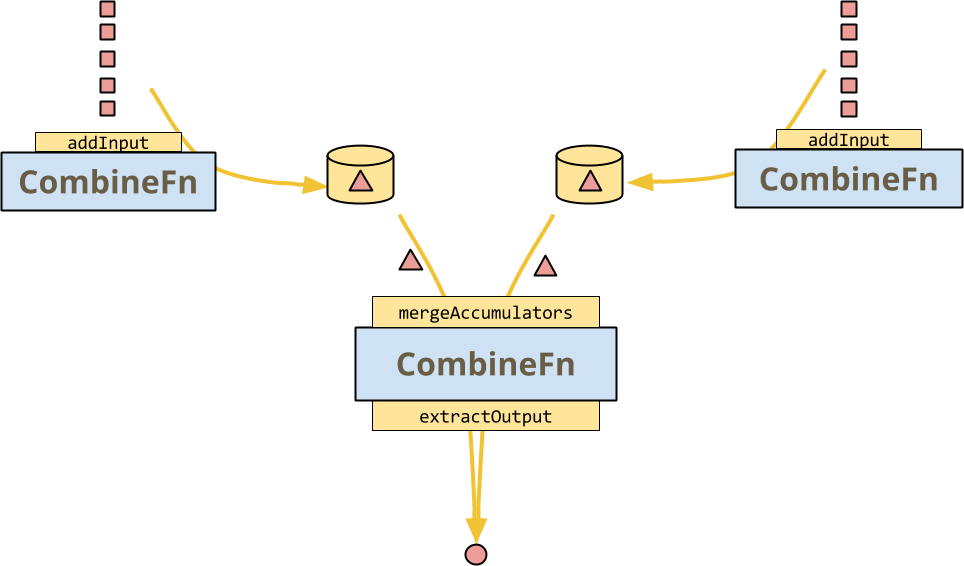
CombineFn 的约定是,无论运行器是否决定实际执行此操作,或者甚至执行更复杂的树(带有热键扇出等),结果都应该完全相同。
此合并操作不是(一定)由有状态的 DoFn 提供:运行器不能自由地分支其执行并重新组合状态。请注意,输入元素仍然以任意顺序接收,因此 DoFn 应该对排序和捆绑不敏感,但这并不意味着输出必须完全相等。(有趣且易于理解的事实:如果输出实际上总是相等,则 DoFn 是一个关联和可交换的操作符)
所以现在您可以看到有状态的 DoFn 如何与 CombineFn 不同,但我希望退一步,将此推断为 Beam 中状态如何与使用其他功能来实现相同或类似目标的高级图:在很多情况下,有状态处理代表了一个机会,让我们“深入了解”Beam 的高度抽象的、主要由确定性功能构成的范式,并进行潜在的非确定性命令式风格的编程,这些编程很难用其他方式表达。
示例:任意但一致的索引分配
假设您想要为每个传入的键和窗口元素分配一个索引。您不关心索引是什么,只要它们是唯一的且一致即可。在深入研究如何在 Beam SDK 中执行此操作的代码之前,我将从模型级别概述此示例。在图片中,您想要编写一个将输入映射到输出的变换,如下所示。
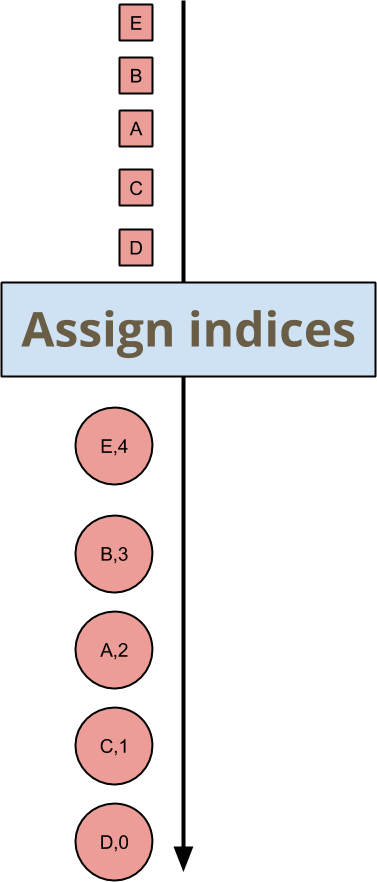
元素 A、B、C、D、E 的顺序是任意的,因此它们分配的索引是任意的,但下游变换只需要对此保持一致即可。就实际值而言,没有关联性或可交换性。此变换的顺序不敏感性仅扩展到确保输出的必要属性:没有重复的索引,没有间隙,并且每个元素都获得一个索引。
从概念上讲,将其表达为一个有状态的循环就像您能想象的那样微不足道:您应该存储的状态是下一个索引。
- 当一个元素进来时,输出它以及下一个索引。
- 递增索引。
这提供了一个很好的机会来谈论大数据和并行处理,因为那些要点中的算法根本无法并行化!如果你想将这种逻辑应用于整个PCollection,你将不得不逐个处理PCollection中的每个元素……这显然不是一个好主意。Beam 中的状态是严格限定范围的,因此大多数情况下,有状态的ParDo转换仍然可以让运行器并行执行,尽管你仍然需要仔细考虑它。
Beam 中的状态单元的作用域限定为键值+窗口对。当你的 DoFn 通过名称"index"读取或写入状态时,它实际上正在访问由"index"指定的可变单元,以及当前正在处理的键值和窗口。因此,在考虑状态单元时,将你的转换的完整状态视为一个表格可能会有所帮助,其中行根据你在程序中使用的名称命名,例如"index",而列是键值+窗口对,例如
| (键值, 窗口)1 | (键值, 窗口)2 | (键值, 窗口)3 | … | |
|---|---|---|---|---|
"index" | 3 | 7 | 15 | … |
"fizzOrBuzz?" | "fizz" | "7" | "fizzbuzz" | … |
| … | … | … | … | … |
(如果你有超强的空间感,可以随意想象这是一个立方体,其中键值和窗口是独立的维度)
你可以通过确保该表格有足够的列来为并行化提供机会。你可能有很多键值和窗口,或者你可能有很多只是其中之一
- 例如,在少数窗口中有很多键值,这是一种由用户 ID 作为键的全局窗口化有状态计算。
- 例如,在少数键值上有很多窗口,这是一种针对全局键值的固定窗口化有状态计算。
注意:今天所有 Beam 运行器都只在键值上并行化。
大多数情况下,你对状态的思维模型可以只关注表格的单列,即单个键值+窗口对。跨列交互不会直接发生,这是有意为之的。
Beam 的 Java SDK 中的状态
现在我已经稍微讨论了 Beam 模型中的有状态处理,并完成了抽象示例的分析,我想向你展示使用 Beam 的 Java SDK 来编写有状态处理代码是什么样子的。以下是为每个元素在每个键值和窗口的基础上分配任意但一致索引的有状态DoFn的代码
new DoFn<KV<MyKey, MyValue>, KV<Integer, KV<MyKey, MyValue>>>() {
// A state cell holding a single Integer per key+window
@StateId("index")
private final StateSpec<ValueState<Integer>> indexSpec =
StateSpecs.value(VarIntCoder.of());
@ProcessElement
public void processElement(
ProcessContext context,
@StateId("index") ValueState<Integer> index) {
int current = firstNonNull(index.read(), 0);
context.output(KV.of(current, context.element()));
index.write(current+1);
}
}class IndexAssigningStatefulDoFn(DoFn):
INDEX_STATE = CombiningStateSpec('index', sum)
def process(self, element, index=DoFn.StateParam(INDEX_STATE)):
unused_key, value = element
current_index = index.read()
yield (value, current_index)
index.add(1)让我们来分析一下
- 首先要关注的是一对
@StateId("index")注释的存在。这表明你在这个DoFn中使用了名为“index”的可变状态单元。Beam Java SDK,以及从那里选择运行器,也会注意到这些注释并使用它们来正确地连接你的 DoFn。 - 第一个
@StateId("index")注释在类型为StateSpec(表示“状态规范”)的字段上。这声明并配置了状态单元。类型参数ValueState描述了你可以从这个单元中获取的类型的状态——ValueState只存储单个值。请注意,规范本身不是一个可用的状态单元——你需要运行器在管道执行期间提供该状态单元。 - 为了完全指定
ValueState单元,你需要提供运行器将使用(如有必要)来序列化你将要存储的值的编码器。这是调用StateSpecs.value(VarIntCoder.of())。 - 第二个
@StateId("index")注释在你的@ProcessElement方法的参数上。这表示访问之前指定的 ValueState 单元。 - 状态以最简单的方式访问:使用
read()读取它,使用write(newvalue)写入它。 DoFn的其他功能以通常的方式提供,例如context.output(...)。你也可以使用侧输入、侧输出、访问窗口等等。
关于 SDK 和运行器如何看待这个 DoFn 的一些注意事项
- 你的所有状态单元都已明确声明,因此 Beam SDK 或运行器可以推断它们,例如在窗口过期时清除它们。
- 如果你声明了一个状态单元,然后使用错误的类型使用它,Beam Java SDK 将为你捕获该错误。
- 如果你使用相同的 ID 声明了两个状态单元,SDK 也会捕获该错误。
- 运行器知道这是一个有状态的
DoFn,并且可能会以完全不同的方式运行它,例如通过额外的数据混洗和同步来避免对状态单元的并发访问。
让我们再来看一个如何使用这个 API 的示例,这次更贴近实际情况。
示例:异常检测
假设你将用户的一系列操作馈送到某个复杂模型中,以预测他们所采取的操作类型的某种定量表达,例如检测欺诈行为。你将从事件中构建模型,并将传入事件与最新的模型进行比较,以确定是否有任何变化。
如果你试图将模型的构建表达为CombineFn,你可能会遇到mergeAccumulators的问题。假设你可以表达它,它可能看起来像这样
class ModelFromEventsFn extends CombineFn<Event, Model, Model> {
@Override
public abstract Model createAccumulator() {
return Model.empty();
}
@Override
public abstract Model addInput(Model accumulator, Event input) {
return accumulator.update(input); // this is encouraged to mutate, for efficiency
}
@Override
public abstract Model mergeAccumulators(Iterable<Model> accumulators) {
// ?? can you write this ??
}
@Override
public abstract Model extractOutput(Model accumulator) {
return accumulator; }
}class ModelFromEventsFn(apache_beam.core.CombineFn):
def create_accumulator(self):
# Create a new empty model
return Model()
def add_input(self, model, input):
return model.update(input)
def merge_accumulators(self, accumulators):
# Custom merging logic
def extract_output(self, model):
return model现在你有了为特定窗口计算特定用户的模型的方法,即Combine.perKey(new ModelFromEventsFn())。你将如何将这个模型应用于生成它的相同事件流?使用Combine转换的结果并在处理PCollection的元素时使用它的标准方法是将其作为ParDo转换的侧输入读取。因此,你可以侧输入模型并检查事件流,并输出预测结果,如下所示
PCollection<KV<UserId, Event>> events = ...
final PCollectionView<Map<UserId, Model>> userModels = events
.apply(Combine.perKey(new ModelFromEventsFn()))
.apply(View.asMap());
PCollection<KV<UserId, Prediction>> predictions = events
.apply(ParDo.of(new DoFn<KV<UserId, Event>>() {
@ProcessElement
public void processElement(ProcessContext ctx) {
UserId userId = ctx.element().getKey();
Event event = ctx.element().getValue();
Model model = ctx.sideinput(userModels).get(userId);
// Perhaps some logic around when to output a new prediction
… c.output(KV.of(userId, model.prediction(event))) …
}
}));# Events is a collection of (user, event) pairs.
events = (p | ReadFromEventSource() | beam.WindowInto(....))
user_models = beam.pvalue.AsDict(
events
| beam.core.CombinePerKey(ModelFromEventsFn()))
def event_prediction(user_event, models):
user = user_event[0]
event = user_event[1]
# Retrieve the model calculated for this user
model = models[user]
return (user, model.prediction(event))
# Predictions is a collection of (user, prediction) pairs.
predictions = events | beam.Map(event_prediction, user_models)在这个管道中,Combine.perKey(...)为每个用户、每个窗口只发射一个模型,然后由View.asMap()转换准备用于侧输入。ParDo在事件上的处理将阻塞,直到该侧输入准备就绪,缓冲事件,然后将检查每个事件与模型是否匹配。这是一个高延迟、高完整性的解决方案:模型考虑了窗口中所有用户的行为,但在窗口完成之前无法输出任何结果。
假设你想要更早地获得一些结果,或者甚至没有自然的窗口化,只是想要对“迄今为止的模型”进行持续分析,即使你的模型可能并不完整。你如何控制用来检查事件的模型的更新?触发器是用于管理完整性与延迟权衡的通用 Beam 功能。因此,以下是在管道中添加了一个触发器,该触发器在输入到达后一秒钟输出一个新模型
PCollection<KV<UserId, Event>> events = ...
PCollectionView<Map<UserId, Model>> userModels = events
// A tradeoff between latency and cost
.apply(Window.triggering(
AfterProcessingTime.pastFirstElementInPane(Duration.standardSeconds(1)))
.apply(Combine.perKey(new ModelFromEventsFn()))
.apply(View.asMap());events = ...
user_models = beam.pvalue.AsDict(
events
| beam.WindowInto(GlobalWindows(),
trigger=trigger.AfterAll(
trigger.AfterCount(1),
trigger.AfterProcessingTime(1)))
| beam.CombinePerKey(ModelFromEventsFn()))这通常是延迟和成本之间相当不错的权衡:如果在一秒钟内有大量事件涌入,那么你只会发射一个新模型,因此你不会被无法在过时之前使用的模型输出淹没。实际上,新模型可能需要很多秒才能出现在侧输入通道中,这是因为缓存和处理延迟正在准备侧输入。许多事件(也许是整个活动批次)将通过ParDo并根据之前的模型计算它们的预测。如果运行器对缓存过期时间设置了足够紧密的限制,并且你使用了更积极的触发器,你可能能够以额外的成本提高延迟。
但还有另外一个成本要考虑:你正在从ParDo输出许多无趣的输出,这些输出将在下游被处理。如果输出的“有趣性”只是相对于之前的输出而言定义的,那么你无法使用Filter转换来减少下游的数据量。
有状态处理可以解决侧输入的延迟问题和过度无趣输出的成本问题。以下是代码,只使用了我已经介绍过的功能
new DoFn<KV<UserId, Event>, KV<UserId, Prediction>>() {
@StateId("model")
private final StateSpec<ValueState<Model>> modelSpec =
StateSpecs.value(Model.coder());
@StateId("previousPrediction")
private final StateSpec<ValueState<Prediction>> previousPredictionSpec =
StateSpecs.value(Prediction.coder());
@ProcessElement
public void processElement(
ProcessContext c,
@StateId("previousPrediction") ValueState<Prediction> previousPredictionState,
@StateId("model") ValueState<Model> modelState) {
UserId userId = c.element().getKey();
Event event = c.element().getValue()
Model model = modelState.read();
Prediction previousPrediction = previousPredictionState.read();
Prediction newPrediction = model.prediction(event);
model.add(event);
modelState.write(model);
if (previousPrediction == null
|| shouldOutputNewPrediction(previousPrediction, newPrediction)) {
c.output(KV.of(userId, newPrediction));
previousPredictionState.write(newPrediction);
}
}
};class ModelStatefulFn(beam.DoFn):
PREVIOUS_PREDICTION = BagStateSpec('previous_pred_state', PredictionCoder())
MODEL_STATE = CombiningValueStateSpec('model_state',
ModelCoder(),
ModelFromEventsFn())
def process(self,
user_event,
previous_pred_state=beam.DoFn.StateParam(PREVIOUS_PREDICTION),
model_state=beam.DoFn.StateParam(MODEL_STATE)):
user = user_event[0]
event = user_event[1]
model = model_state.read()
previous_prediction = previous_pred_state.read()
new_prediction = model.prediction(event)
model_state.add(event)
if (previous_prediction is None
or self.should_output_prediction(
previous_prediction, new_prediction)):
previous_pred_state.clear()
previous_pred_state.add(new_prediction)
yield (user, new_prediction)让我们来分析一下它:
- 你声明了两个状态单元,
@StateId("model")用于保存用户的模型的当前状态,以及@StateId("previousPrediction")用于保存之前输出的预测结果。 - 在
@ProcessElement方法中,通过注释访问这两个状态单元与之前一样。 - 你通过
modelState.read()读取当前模型。对于每个键值和窗口,这只是一个针对当前正在处理的 Event 的 UserId 的模型。 - 你推导出一个新的预测
model.prediction(event),并将其与你最后输出的预测结果进行比较,该预测结果可以通过previousPredicationState.read()访问。 - 然后你更新模型
model.update(),并通过modelState.write(...)写入它。对从状态中提取的值进行变异是完全没有问题的,只要你记得写入变异的值,就像鼓励你对CombineFn累加器进行变异一样。 - 如果预测结果与上次输出的结果发生了很大变化,你将通过
context.output(...)发射它,并使用previousPredictionState.write(...)保存预测结果。这里的决策是相对于之前输出的预测结果,而不是最后计算的预测结果——实际上,你可能在这里有一些复杂条件。
上面大部分内容都是关于 Java 的!但在你开始将所有管道转换为使用有状态处理之前,我想讨论一些关于它是否适合你的用例的考虑因素。
性能考虑因素
要决定是否使用每个键值和窗口的状态,你需要考虑它如何执行。你可以深入了解特定运行器如何管理状态,但有一些普遍事项需要牢记
- 每个键值和窗口的划分:也许最重要的考虑因素是运行器可能需要对你的数据进行混洗,以便将特定键值+窗口的所有数据放在一起。如果数据已经按正确方式混洗,运行器可能会利用这一点。
- 同步开销:API 的设计是为了让运行器处理并发控制,但这意味着即使在其他情况下有利于并行化,运行器也无法并行化对特定键值+窗口的元素的处理。
- 状态的存储和容错性:由于状态是每个键值和窗口的,因此你期望同时处理的键值和窗口越多,你将产生的存储空间就越多。由于状态受益于 Beam 中其他数据的容错性/一致性属性,因此它还会增加提交处理结果的成本。
- 状态过期:由于状态是每个窗口的,因此运行器可以在窗口过期时(当水位线超过其允许的延迟时)回收资源,但这可能意味着运行器需要跟踪每个键值和窗口的额外计时器,以便执行回收代码。
去使用它!
如果你不熟悉 Beam,我希望你现在对看看是否有状态处理的 Beam 可以解决你的用例感兴趣。如果你已经使用 Beam,我希望这个模型的新增内容可以为你解锁新的用例。请查看功能矩阵,看看你最喜欢的后端(s)对这个新模型功能的支持程度。
并且请加入 user@beam.apache.org 的社区。我们很乐意收到你的消息。