



博客
2017/08/16
Apache Beam 中使用可拆分的 DoFn 实现强大的模块化 IO 连接器
Apache Beam 生态系统中最重要的部分之一是其快速增长的连接器集,这些连接器允许 Beam 管道读取和写入各种数据存储系统(“IO”)。目前,Beam 附带了 20 多个 IO 连接器,还有更多连接器正在积极开发中。随着用户对 IO 连接器的需求不断增长,我们在改进相关 Beam API(特别是 Source API)方面的工作取得了意想不到的结果:对 Beam 最基本的基本原语 DoFn 的泛化。
致读者
尊敬的读者!这篇博客是对可拆分 DoFn 的一个很好的介绍,但它是编写文档时的草稿。阅读完这篇博客后,你可以继续学习什么是可拆分 DoFn 以及如何在官方 Beam 文档 中实现一个可拆分 DoFn。
连接器作为微管道
这个充满活力的 IO 连接器生态系统的主要原因之一是开发一个基本的 IO 相对简单:许多连接器实现只是由基本 Beam ParDo 和 GroupByKey 原语组成的微管道(复合 PTransform)。例如,ElasticsearchIO.write() 扩展 成一个具有批量处理以提高性能的 ParDo;JdbcIO.read() 扩展 成 Create.of(query)、一个重新洗牌以 防止融合 以及 ParDo(execute sub-query)。有些 IO 构建 了更为复杂的管道。
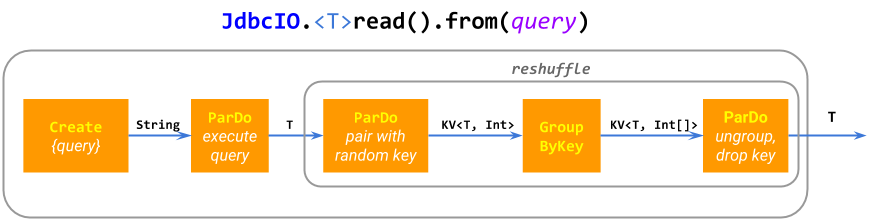
这种“微管道”方法很灵活,模块化,并且可以泛化到从动态计算的 PCollection 位置读取数据的源,例如 SpannerIO.readAll() 从 Cloud Spanner 中读取 PCollection 查询的结果,与 SpannerIO.read() 执行单个查询相比。我们相信这种动态数据源是一个非常有用的功能,通常被其他数据处理框架忽略。
当 ParDo 和 GroupByKey 不够用时
尽管 ParDo、GroupByKey 及其衍生物很灵活,但在某些情况下,构建一个高效的 IO 连接器需要额外的功能。
例如,想象一下使用序列 ParDo(filepattern → expand into files)、ParDo(filename → read records) 读取文件,或者使用 ParDo(topic → list partitions)、ParDo(topic, partition → read records) 读取 Kafka 主题。这种方法有两个主要问题
在文件示例中,一些文件可能比其他文件大得多,因此第二个
ParDo可能具有非常长的单个@ProcessElement调用。结果,由于落后者,管道可能会因性能低下而受到影响。在 Kafka 示例中,使用常规
DoFn实现第二个ParDo根本不可能,因为它需要为每个输入元素topic, partition输出无限数量的记录 (有状态处理 很接近,但它有其他限制,使其不足以完成此任务)。
Beam Source API
Apache Beam 从历史上来说提供了一个 Source API(BoundedSource 和 UnboundedSource),它没有这些限制,允许开发用于批处理和流式系统的有效数据源。管道通过 Read.from(Source) 内置 PTransform 使用此 API。
Source API 在很大程度上类似于大多数其他数据处理框架的 API,并允许系统使用多个工作器并行读取数据,以及检查点和从无界数据源恢复读取。此外,Beam BoundedSource API 提供了高级功能,如进度报告和 动态重新平衡(它们共同支持自动扩展),以及 UnboundedSource 支持报告源的水印和积压量 (在 SDF 出现之前,我们认为“批处理”和“流式”数据源在本质上是不同的,因此需要不同的 API)。
不幸的是,这些功能是有代价的。针对 Source API 编码涉及很多样板代码,并且容易出错,而且它与 Beam 模型的其他部分不能很好地组合,因为 Source 只能出现在管道的根部。例如
使用 Source API,无法读取
PCollection文件模式。Source无法读取侧输入,也无法等待另一个管道步骤生成数据。Source无法发出额外的输出(例如,无法解析的记录),等等。
Source API 甚至不能与自身组合。例如,假设 Alice 实现了一个无界 Source 来监视一个目录以查找新的匹配文件,而 Bob 实现了一个无界 Source 来尾随一个文件。Source API 不允许他们简单地将这些源链接在一起并获得一个 Source,该 Source 返回目录中新日志文件中的新记录(这是一个非常常见的用户请求)。相反,这样的源必须从头开始开发,我们的经验表明,对这样的 Source 进行功能齐全的整体实现非常困难且容易出错。
Source API 的另一类问题来自其严格的无界/有界二分法
在看似非常相似的有界和无界源之间重用代码很困难或不可能,例如,生成序列
[a, b)的BoundedSource和生成序列[a, inf)的UnboundedSource在 Beam Java SDK 中没有共享任何代码。目前还不清楚如何对非常大且不断增长的数据集的摄取进行分类。摄取其“已可用”部分似乎需要一个
BoundedSource:运行器可以从知道其大小中获益,并且可以执行动态重新平衡。但是,摄取不断到达的新数据似乎需要一个UnboundedSource来提供水印。从这个角度来看,SourceAPI 具有 与 Lambda 架构相同的问题。
大约两年前,我们开始思考如何解决 Source API 的局限性,最终,令人惊讶的是,我们解决了 DoFn 的局限性。
引入可拆分的 DoFn
可拆分的 DoFn(SDF)是 DoFn 的泛化,它赋予了 DoFn Source 的核心功能,同时保留了 DoFn 的语法、灵活性、模块化和编码的便捷性。结果,开发比以前更强大的 IO 连接器成为可能,并且代码更短、更简单、更可重用。
请注意,与 Source 不同,SDF 没有不同的有界/无界 API,就像普通的 DoFn 一样:只有一个 API,它涵盖了这两种用例以及两者之间的任何情况。因此,SDF 弥合了 Apache Beam 统一批处理/流式编程模型的最后差距。
阅读下面对 SDF 的解释时,请记住一个 DoFn 的运行示例,该 DoFn 以文件名作为输入并输出该文件中的记录。熟悉 Source API 的人可能会发现,将 SDF 视为一种读取 PCollection 源的方法,将源本身视为管道中的另一块数据 (实际上,这是早期设计迭代中导致创建 SDF 的工作之一)。
Source 相对于普通 DoFn 的两个优势在于
可拆分性:将
DoFn应用于单个元素是 整体式 的,但从Source读取是 非整体式 的。不必一次读取整个Source;相反,它是分部分读取的,称为 包。例如,一个大文件通常被分成多个包来读取,每个包读取文件中一些偏移量子范围。同样,Kafka 主题(当然,永远无法“完全”读取)被分成无限多个包来读取,每个包读取有限数量的元素。与运行器的交互:运行器将
DoFn应用于单个元素作为“黑盒”,但与Source的交互非常丰富。Source向运行器提供信息,如其估计大小(或其泛化,“积压量”)、读取包的进度、水印等。运行器使用此信息来调整执行并控制将Source分解成包。例如,一个进展缓慢的大文件包可能会由一个专注于批处理的运行器 动态拆分,以防止它成为落后者,而一个专注于延迟的流式运行器可能会控制它在每个包中从源读取多少元素,以优化延迟与每个包的开销之间的权衡。
具有限制条件的非整体式元素处理
可拆分的 DoFn 通过允许单个元素的处理是非整体式来支持类似 Source 的功能。
SDF 处理一个元素被分解成(可能无限的)多个 限制,每个限制描述了要为整个元素完成的一些工作。SDF 的 @ProcessElement 调用的输入是元素和限制的配对(与只接受元素的普通 DoFn 相比)。
每个元素的处理从创建一个 初始限制 开始,该限制描述了所有工作,然后初始限制被进一步拆分成子限制,这些子限制在逻辑上必须加起来等于原始限制。例如,对于一个名为 ReadFn 的可拆分的 DoFn,它接收文件名并输出文件中的记录,限制可以是一对起始和结束字节偏移量,ReadFn 可以将其解释为 读取起始偏移量在给定范围内的记录。
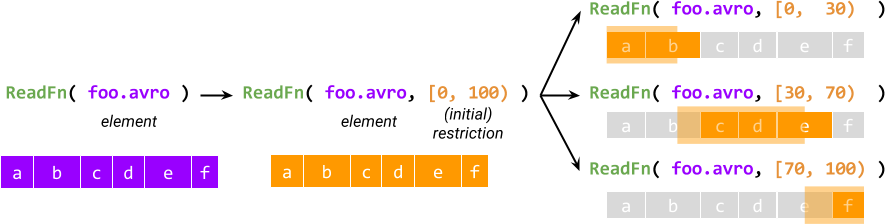
限制的概念提供了非整体式执行——与 Source 相当的第一个要素。另一个要素是 与运行器的交互:运行器可以访问 SDF 的每个活动 @ProcessElement 调用的限制,可以查询调用进度,最重要的是,它可以 在处理限制时拆分限制(因此得名 可拆分的 DoFn)。
拆分会产生一个主限制和一个残余限制,它们加起来等于被拆分的原始限制:当前的@ProcessElement调用继续处理主限制,残余限制将由另一个@ProcessElement调用处理。例如,一个运行器可以将残余限制安排在另一个工作程序上并行处理。
正在运行的@ProcessElement调用的拆分有两个至关重要的用途
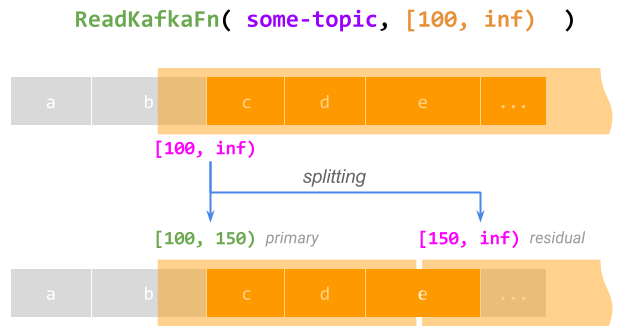
- 支持每个元素的无限工作。 一般来说,限制不需要描述有限量的工作。例如,从偏移量100开始读取 Kafka 主题可以用限制[100, inf)表示。一个处理此整个限制的
@ProcessElement调用当然永远不会完成。但是,在这样的调用运行时,一个运行器可以将限制拆分为一个有限的主限制[100, 150)(让当前调用完成这部分)和一个无限的残余限制[150, inf) 以便稍后处理,有效地检查点并恢复调用;这可以无限期地重复。
- 动态重新平衡。 当一个(通常是面向批处理的)运行器检测到
@ProcessElement调用将花费太长时间并成为落后者时,它可以按比例拆分限制,以便主限制足够短,不会成为落后者,并且可以安排残余限制在另一个工作程序上并行处理。有关详细信息,请参阅 No Shard Left Behind。
从逻辑上讲,SDF 在元素上的执行按照以下图表工作,其中“魔法”代表运行器特定的拆分限制和安排残余处理的能力。
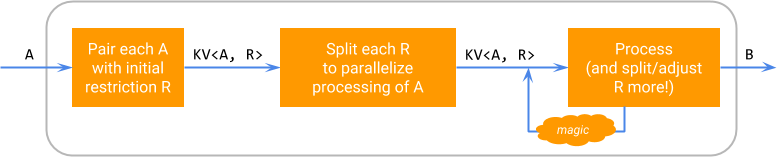
此图表强调,可拆分性是特定DoFn的实现细节:一个可拆分的DoFn对于其用户来说仍然像一个DoFn<A, B>,并且可以通过ParDo应用于一个PCollection<A>,从而生成一个PCollection<B>。
哪些 DoFn 需要是可拆分的
请注意,将元素分解为元素/限制对不是自动的或“魔法的”:SDF 是一个用于编写DoFn的新 API,而不是一个执行现有DoFn的新方法。在使DoFn可拆分时,作者需要
考虑它对每个元素执行的工作的结构。
想出一个使用限制描述此工作部分的方案。
编写代码来创建初始限制、拆分它并执行元素/限制对。
用户管道中绝大多数DoFn不需要被设置为可拆分的:SDF 是一个高级的、强大的 API,主要针对新的 IO 连接器的作者(尽管它也有一些有趣的非 IO 应用:参见 非 IO 示例)。
限制的执行和数据一致性
Splittable DoFn 设计中最重要的部分之一与它如何在拆分时实现数据一致性有关。例如,当运行器准备拆分活动@ProcessElement调用的限制时,它如何确保调用不会同时超过拆分点?
这是通过要求处理限制遵循某种模式来实现的。我们将限制视为一系列块 - 基本不可分割的工作单位,由位置标识。@ProcessElement调用一个接一个地处理块,首先声明块的位置,以原子方式检查它是否仍在限制范围内,直到整个限制都被处理。
下图说明了这一点,ReadFn(一个可拆分的DoFn,读取 Avro 文件)使用限制[30, 70)处理元素foo.avro。此@ProcessElement调用从偏移量30开始扫描 Avro 文件以查找数据块,并在此范围内声明每个块的位置。如果成功声明一个块,则调用将输出此数据块中的所有记录,否则,它将终止。
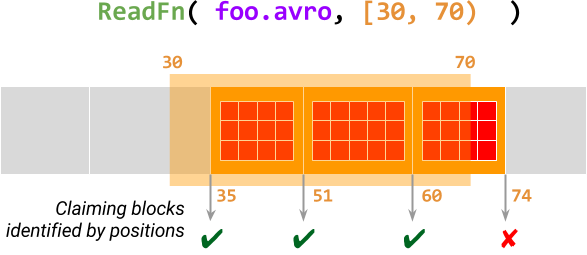
有关更多详细信息,请参阅设计提案文档中的 限制、块和位置。
代码示例
让我们看一些 SDF 代码的示例。这些示例使用 Beam Java SDK,它将可拆分的DoFn表示为灵活的 基于注释的DoFn 机制的一部分,以及建议用于 Python 的 SDF 语法。
一个可拆分的
DoFn是一个DoFn- 不需要新的基类。任何 SDF 都从DoFn类派生,并具有一个@ProcessElement方法。@ProcessElement方法除了当前元素之外,还接受一个额外的RestrictionTracker参数,该参数可以访问当前限制。一个 SDF 需要定义一个
@GetInitialRestriction方法,该方法可以创建一个描述给定元素的完整工作的限制。还有一些不太重要的可选方法,例如用于将初始限制预先拆分为几个较小的限制的
@SplitRestriction,以及其他一些方法。
SDF 的“Hello World”是一个计数器,它将(x, N)对作为输入,并生成(x, 0), (x, 1), …, (x, N-1)对作为输出。
class CountFn<T> extends DoFn<KV<T, Long>, KV<T, Long>> {
@ProcessElement
public void process(ProcessContext c, OffsetRangeTracker tracker) {
for (long i = tracker.currentRestriction().getFrom(); tracker.tryClaim(i); ++i) {
c.output(KV.of(c.element().getKey(), i));
}
}
@GetInitialRestriction
public OffsetRange getInitialRange(KV<T, Long> element) {
return new OffsetRange(0L, element.getValue());
}
}
PCollection<KV<String, Long>> input = …;
PCollection<KV<String, Long>> output = input.apply(
ParDo.of(new CountFn<String>());class CountFn(DoFn):
def process(element, tracker=DoFn.RestrictionTrackerParam)
for i in xrange(*tracker.current_restriction()):
if not tracker.try_claim(i):
return
yield element[0], i
def get_initial_restriction(element):
return (0, element[1])这个简短的DoFn包含了CountingSource的功能,但更灵活:CountingSource只生成在管道构建时指定的单个序列,而此DoFn可以生成动态的序列族,每个输入集合中的元素一个(输入集合是有界还是无界都没关系)。
但是,CountingSource中特定于Source的功能仍然可以在CountFn中使用。例如,如果一个序列有很多元素,一个面向批处理的运行器仍然可以对其应用动态重新平衡,并通过拆分OffsetRange并行生成序列的不同子范围。同样,一个面向流的运行器可以使用相同的拆分逻辑来检查点并恢复序列的生成,即使它在实际上是无限的(例如,当应用于KV(..., Long.MAX_VALUE)时)。
一个稍微复杂的示例是上面考虑的ReadFn,它从 Avro 文件读取数据并说明了块的概念:我们提供伪代码来说明这种方法。
class ReadFn extends DoFn<String, AvroRecord> {
@ProcessElement
void process(ProcessContext c, OffsetRangeTracker tracker) {
try (AvroReader reader = Avro.open(filename)) {
// Seek to the first block starting at or after the start offset.
reader.seek(tracker.currentRestriction().getFrom());
while (reader.readNextBlock()) {
// Claim the position of the current Avro block
if (!tracker.tryClaim(reader.currentBlockOffset())) {
// Out of range of the current restriction - we're done.
return;
}
// Emit all records in this block
for (AvroRecord record : reader.currentBlock()) {
c.output(record);
}
}
}
}
@GetInitialRestriction
OffsetRange getInitialRestriction(String filename) {
return new OffsetRange(0, new File(filename).getSize());
}
}class AvroReader(DoFn):
def process(filename, tracker=DoFn.RestrictionTrackerParam)
with fileio.ChannelFactory.open(filename) as file:
start, stop = tracker.current_restriction()
# Seek to the first block starting at or after the start offset.
file.seek(start)
block = AvroUtils.get_next_block(file)
while block:
# Claim the position of the current Avro block
if not tracker.try_claim(block.start()):
# Out of range of the current restriction - we're done.
return
# Emit all records in this block
for record in block.records():
yield record
block = AvroUtils.get_next_block(file)
def get_initial_restriction(self, filename):
return (0, fileio.ChannelFactory.size_in_bytes(filename))这个假设的DoFn从单个 Avro 文件读取记录。值得注意的是缺少扩展文件模式的代码:它不再需要成为此DoFn的一部分!相反,SDK 包含一个FileIO.matchAll() 变换,用于将文件模式扩展为PCollection 文件名,不同的文件格式 IO 可以重用相同的变换,使用不同的DoFn读取文件。
此示例演示了 SDF 允许的模块化增强的优势:FileIO.matchAll() 支持使用.continuously() 在流式管道中连续摄取新文件,并且此功能会自动提供给各种文件格式 IO。例如,TextIO.read().watchForNewFiles() 在后台使用FileIO.matchAll()。
当前状态
Splittable DoFn 是一个主要的新的 API,它的交付和广泛采用涉及 Apache Beam 生态系统不同部分的大量工作。其中一些工作已经完成,并通过新的 IO 连接器为用户提供了直接的益处。但是,还有大量的工作正在进行或计划中。
截至 2017 年 8 月,SDF 可用于 Beam Java Direct 运行器和 Dataflow 流式运行器,并且正在 Flink 和 Apex 运行器中实施;请参阅 功能矩阵 了解当前状态。Python SDK 中对 SDF 的支持正在 积极开发中。
几个基于 SDF 的变换和 IO 连接器可供 Beam 用户在 HEAD 中使用,并将包含在 Beam 2.2.0 中。TextIO 和 AvroIO 最终通过.watchForNewFiles() 提供了文件的连续摄取(最常请求的功能之一),它由实用程序变换FileIO.matchAll().continuously() 和更通用的 Watch.growthOf() 支持。这些实用程序变换对于“高级用户”用例也很有用。
为了支持目前基于 Source API 的 IO 更灵活的用例,我们将更改它们以使用 SDF。这种转变由 TextIO 领导,并且涉及暂时 通过 Source API 执行 SDF 以支持缺乏直接运行 SDF 能力的运行器。
除了启用新的 IO 之外,关于 SDF 的工作还影响了我们对 Beam 编程模型其他部分的思考
SDF 统一了 Beam 编程模型中最后剩下的不是批处理/流式无关的部分(
SourceAPI)。这使我们考虑了无法纯粹描述为批处理或流式处理的用例(例如,摄取大量历史数据并继续处理实时到达的更多数据),并开发了一个 “进度”和“积压”的统一概念。The Fn API - Beam 未来支持跨语言管道的基础 - 使用 SDF 作为唯一表示数据摄取的概念。
SDF 的实现导致 正式化管道终止语义,并使其在运行器之间保持一致。
SDF 为模块化 IO 连接器可以达到的程度设定了新的标准,激发了为一些非 SDF 基连接器创建类似 API(例如,
SpannerIO.readAll()和计划中的JdbcIO.readAll())。
行动呼吁
Apache Beam 依靠拥有庞大的贡献者社区而蓬勃发展。以下是一些你可以参与 SDF 工作并帮助使 Beam IO 连接器生态系统更加模块化的方法
使用当前可用的基于 SDF 的 IO 连接器,提供反馈,提交错误,并建议或实施改进。
提出或开发一个基于 SDF 的新 IO 连接器。
在您最喜欢的运行器中实施或改进对 SDF 的支持。
订阅并参与 user@beam.apache.org(Beam 用户邮件列表)和 dev@beam.apache.org(Beam 开发者邮件列表)上偶尔发生的与 SDF 相关的讨论!