



博客
2024/01/03
在 Apache Beam 上扩展流式工作负载,每秒 100 万个事件及更高

扩展流式工作负载对于确保管道能够处理大量数据,同时最大限度地减少延迟并高效执行至关重要。如果没有适当的扩展,管道可能会遇到性能问题,甚至完全失败,从而延迟业务洞察的获取时间。
鉴于 Apache Beam 对工作负载所需源和接收器的支持,开发流式管道可能很容易。您可以专注于处理(转换、丰富或聚合)以及为每种情况设置正确的配置。
但是,您需要确定关键的性能瓶颈,并确保管道拥有有效处理负载所需的资源。这可能涉及调整工作程序的数量、了解管道源和接收器所需的设置、优化处理逻辑,甚至确定传输格式。
本文说明了如何管理在 Apache Beam 中开发并在 Google Cloud 上使用 Dataflow 运行的流式工作负载的扩展和优化问题。目标是达到每秒 100 万个事件,同时最大限度地减少执行过程中的延迟和资源使用。工作负载使用 Pub/Sub 作为流式源,使用 BigQuery 作为接收器。我们描述了用于帮助工作负载实现所需规模及其后的配置设置和代码更改背后的推理。
本文中描述的进展对应于现实世界工作负载的演变,并进行了一些简化。在实现管道最初的业务需求后,重点转移到了优化性能并减少管道执行所需的资源。
执行设置
为了本文,我们创建了一个测试套件,用于创建管道执行所需的组件。您可以在 此 Github 存储库 中找到代码。您可以在 此文件夹 中找到每次运行中引入的后续配置更改,作为您可以运行以获得类似结果的脚本。
所有执行脚本还可以执行基于 Terraform 的自动化,以创建 Pub/Sub 主题和订阅以及 BigQuery 数据集和表格以运行工作负载。此外,它还启动两个管道:一个数据生成管道,它将事件推送到 Pub/Sub 主题,以及一个摄取管道,它展示了潜在的改进点。
在所有情况下,管道都从一个空的 Pub/Sub 主题和订阅以及一个空的 BigQuery 表格开始。计划是每秒生成 100 万个事件,并在几分钟后查看摄取管道如何随着时间的推移而扩展。自动生成的数据基于给定配置的提供方案或 IDL(或接口描述语言),目标是让消息大小在 800 字节到 2 KB 之间,总计约 1 GB/s 的体积吞吐量。此外,摄取管道在所有运行中使用相同的工作程序类型配置 (n2d-standard-4 GCE 机器),并将最大工作程序数量限制在一定范围内,以避免规模过大的集群。
所有执行都在 Google Cloud 上使用 Dataflow 运行,但您可以在其他受支持的 Apache Beam 运行器上执行时将所有配置和格式更改应用于套件。更改和建议不特定于运行器。
本地环境要求
在启动启动脚本之前,请在您的本地环境中安装以下项目:
gcloud,以及正确的权限- Terraform
- JDK 17 或更高版本
- Maven 3.6 或更高版本
有关更多信息,请参阅 GitHub 存储库中的 要求 部分。
此外,请查看 Google Cloud 项目中可用的服务配额和资源。具体而言:Pub/Sub 区域容量、BigQuery 摄取配额以及测试中所选区域中可用的 Compute Engine 实例。
工作负载说明
专注于摄取管道,我们的 工作负载 很简单。它完成以下步骤:
- 从 Pub/Sub 中读取特定格式的数据(在本例中为 Apache Thrift)
- 处理潜在的压缩和批处理设置(默认情况下未启用)
- 执行 UDF(默认情况下为标识函数)
- 将输入格式转换为
BigQueryIO变换支持的格式之一 - 将数据写入配置的表格
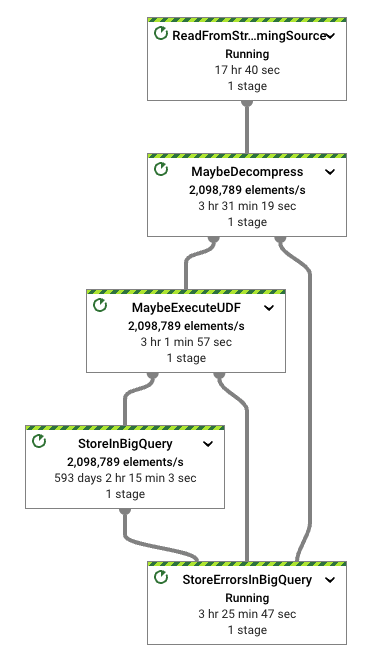
我们用于测试的管道高度可配置。有关如何调整摄取的更多详细信息,请参阅文件中的 选项。我们的任何步骤都不需要进行代码更改。执行脚本负责处理所需的配置。
尽管这些测试专注于从 Pub/Sub 读取数据,但摄取管道能够从通用的流式源读取数据。存储库包含其他 示例,展示了如何启动这个相同的测试套件,从 Pub/Sub Lite 和 Kafka 读取数据。在所有情况下,管道自动化都会设置流式基础设施。
最后,您可以在 配置选项 中看到,管道支持许多针对输入的传输格式选项,例如 Thrift、Avro 和 JSON。本套件侧重于 Thrift,因为它是一种常见的开源格式,并且因为它会生成格式转换需求。目的是给工作负载处理带来一些压力。您可以对 Avro 和 JSON 输入数据运行类似的测试。流式数据生成器管道可以通过直接遍历提供的方案 (Avro 和 JSON) 或 IDL (Thrift) 来生成三种支持格式的 随机数据,用于执行。
首次运行:默认设置
执行的默认值使用 STREAMING_INSERTS 模式将数据写入 BigQuery,用于 BigQueryIO。此模式与 BigQuery 的 tableData insertAll API 相对应。此 API 支持 JSON 格式的数据。从 Apache Beam 的角度来看,使用 BigQueryIO.writeTableRows 方法可以让我们将写入解析到 BigQuery 中。
对于我们的摄取管道,需要将 Thrift 格式转换为 TableRow。为此,我们需要将 Thrift IDL 转换为 BigQuery 表格方案。这可以通过将 Thrift IDL 转换为 Avro 方案,然后使用 Beam 实用程序来转换 BigQuery 的表格方案来实现。我们可以在启动时执行此操作。方案转换在 DoFn 级缓存。
设置好数据生成和摄取管道后,让管道运行几分钟后,我们发现管道无法维持所需的吞吐量。
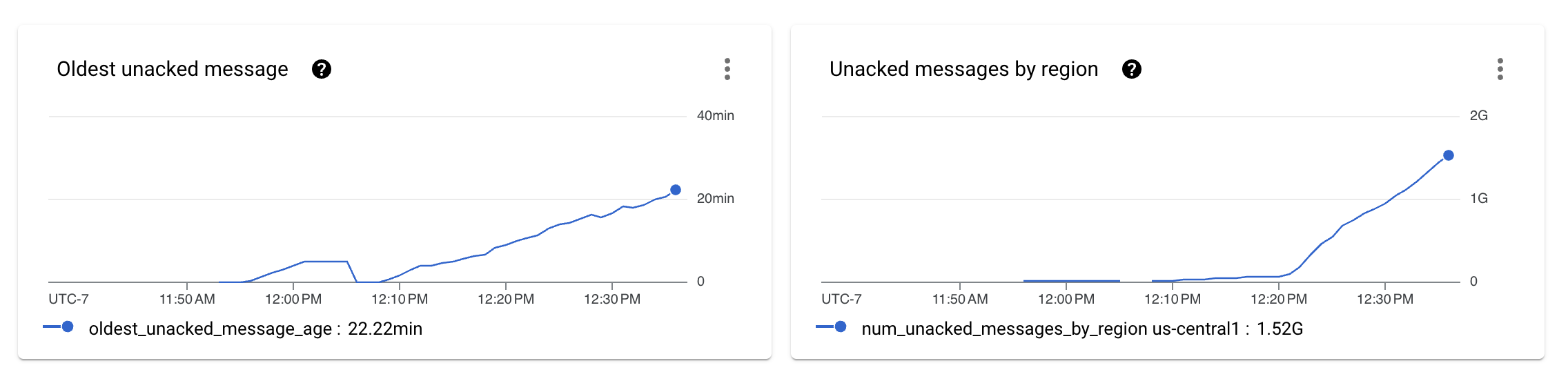
上图显示,摄取管道未处理的消息数量开始在 Pub/Sub 指标中显示为未确认的消息。
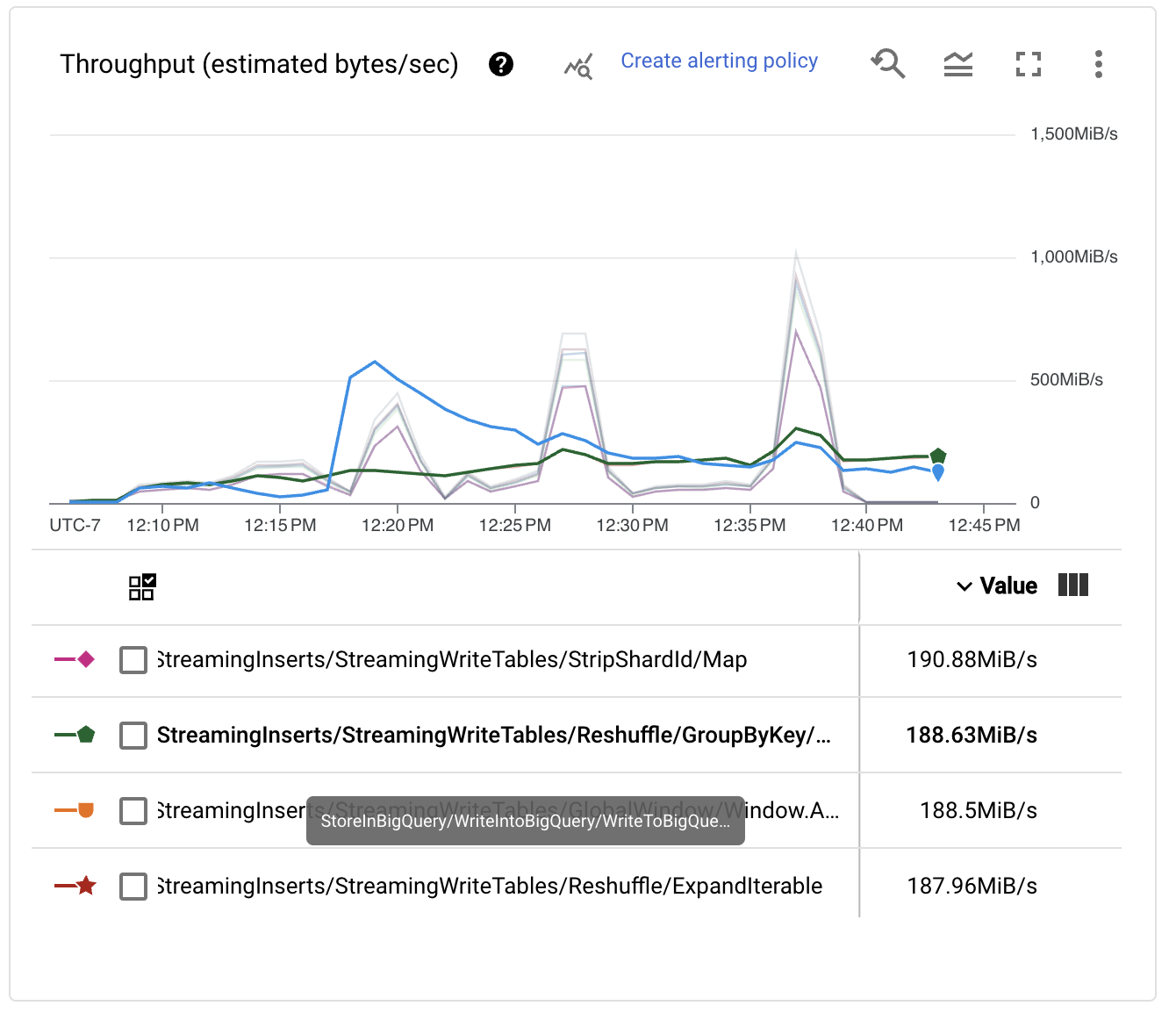
查看每个阶段的性能指标,我们发现管道显示出锯齿状,这通常与 Dataflow 运行器在某些阶段充当吞吐量瓶颈时使用的节流机制相关联。此外,我们还发现 BigQueryIO 写入变换上的 Reshuffle 步骤无法按预期扩展。
出现这种行为的原因是,默认情况下,BigQueryOptions 使用 50 个不同的键来对数据进行混洗,以便在对 BigQuery 进行写入之前将其发送到工作程序。为了解决这个问题,我们可以在启动脚本中添加一个配置,使写入操作能够扩展到更多工作程序,从而提高性能。
第二次运行:改进写入瓶颈
将流式键的数量增加到更高的数量(在本例中为 512 个键)后,我们重新启动了测试套件。Pub/Sub 指标开始改善。在回退大小的初始斜坡之后,曲线开始变得平缓。
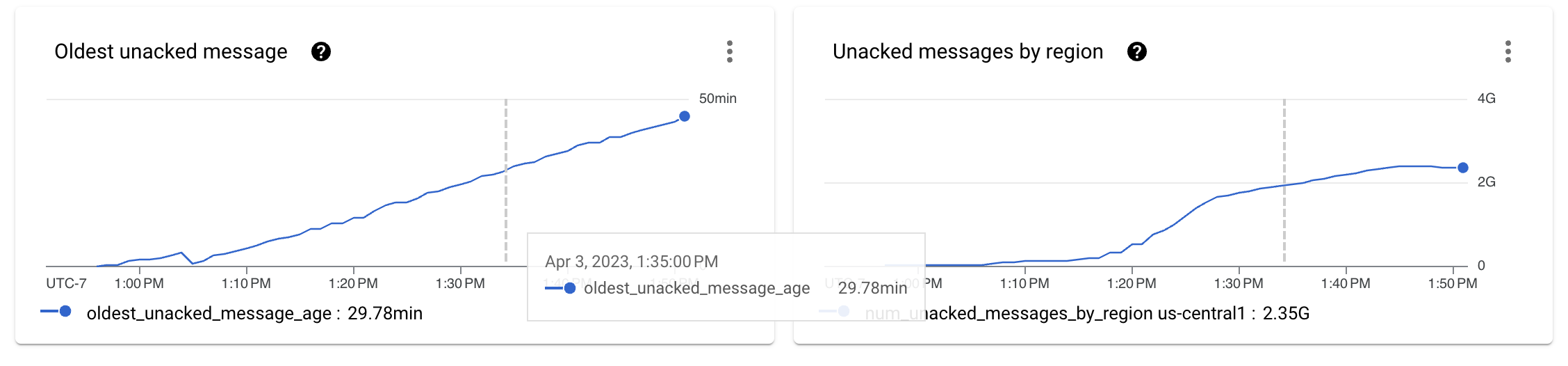
这很好,但我们应该查看每个阶段的吞吐量数字,以了解我们是否实现了为本练习设定的目标。

尽管性能明显提高,Pub/Sub 回退不再单调增加,但我们距离摄取管道每秒处理 100 万个事件(1 GB/s)的目标还很远。事实上,吞吐量指标一直在跳动,表明瓶颈阻止了处理的进一步扩展。
第三次运行:释放自动扩展
幸运的是,在写入 BigQuery 时,我们可以自动扩展写入。此步骤简化了配置,这样我们就不必猜测正确的分片数量。我们切换了管道的配置,并在接下来的 启动脚本 中启用了此设置。
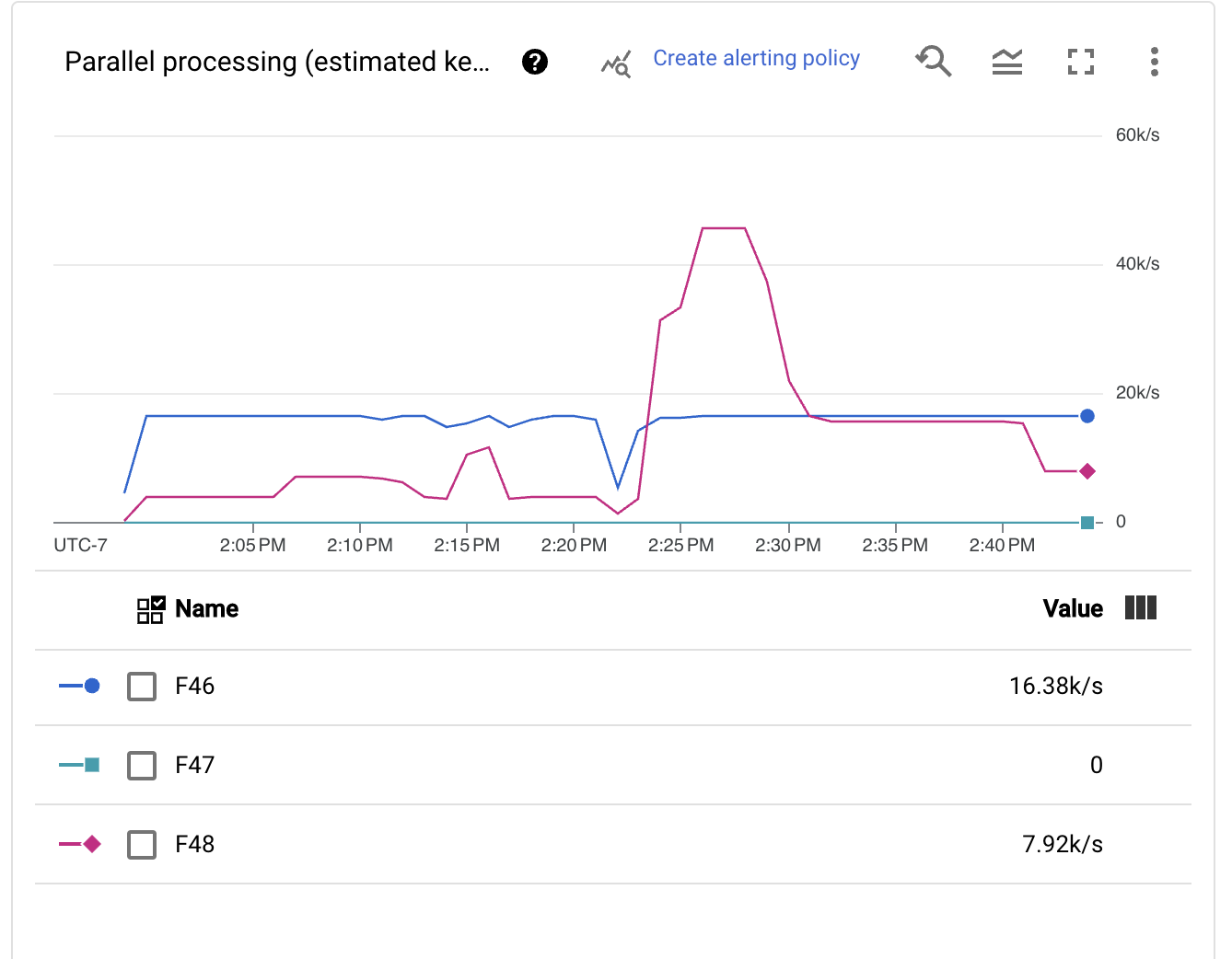
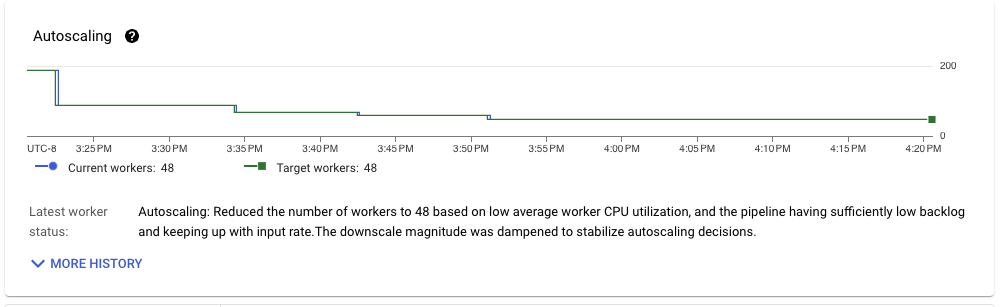
我们立即发现,自动分片机制非常积极地以动态方式调整键的数量。这种变化很好,因为时间的不同时刻可能具有不同的扩展需求,例如早期回退恢复和执行峰值。
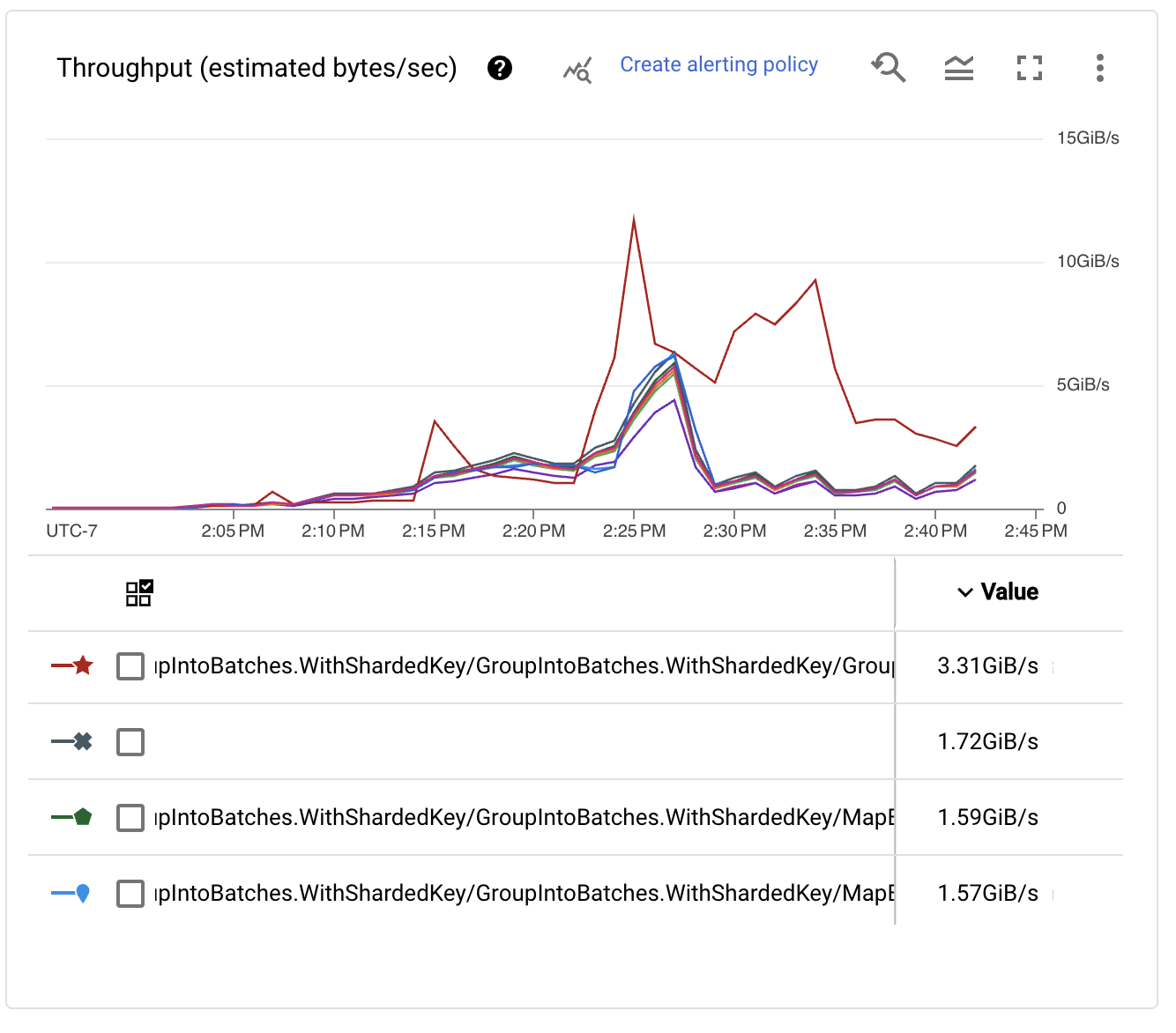
检查每个阶段的吞吐量性能,我们发现,随着键数量的增加,写入的性能也随之提高。事实上,它达到了非常高的数字!
在最初的回退被消耗并且管道稳定后,我们发现所需的性能数字已经实现。管道能够每秒持续处理超过 100 万个事件,并且能够从 Pub/Sub 摄取多个 GB/s 的 BigQuery 数据。太棒了!
然而,我们想知道是否可以做得更好。我们可以对管道进行一些改进,以使执行更加高效。在大多数情况下,改进都是配置更改。我们只需要知道下一步要专注于哪里。
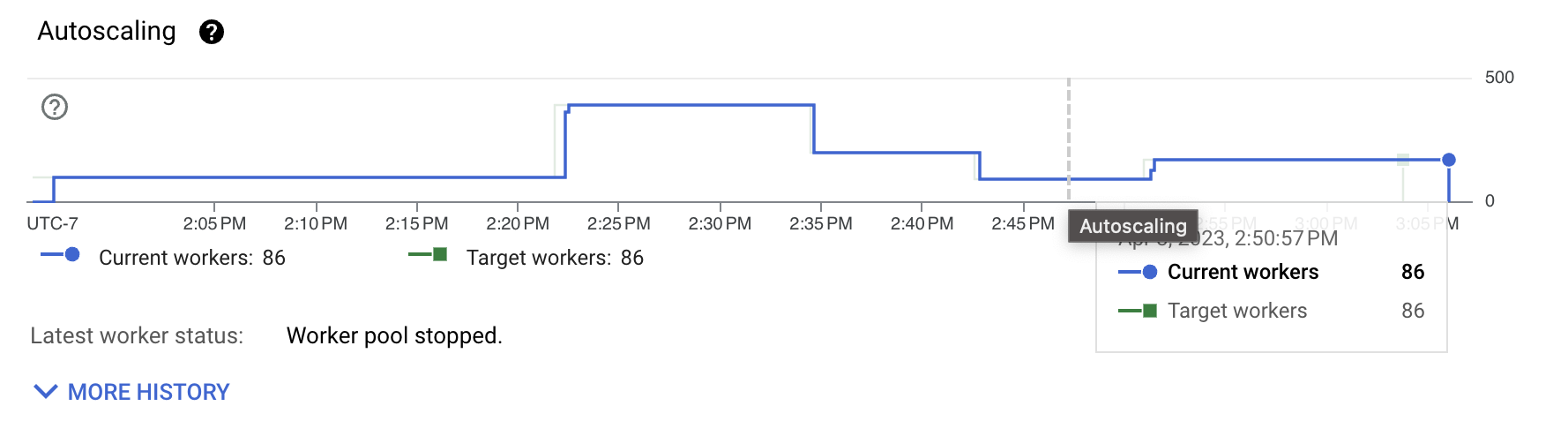
上图显示,维持这种吞吐量所需的工作程序数量仍然相当高。工作负载本身并不占用大量 CPU。大部分成本花在了格式转换以及 I/O 交互上,例如混洗和实际写入。为了了解要改进什么,我们首先研究传输格式。
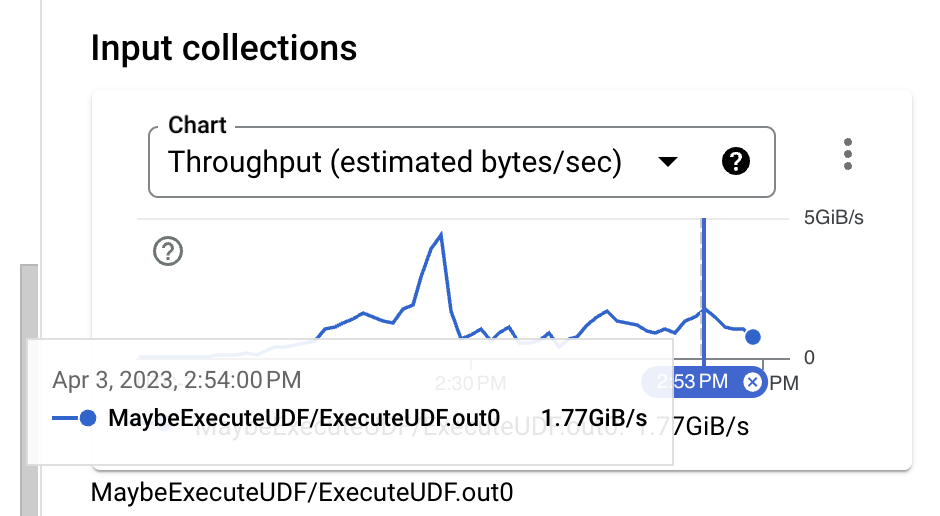
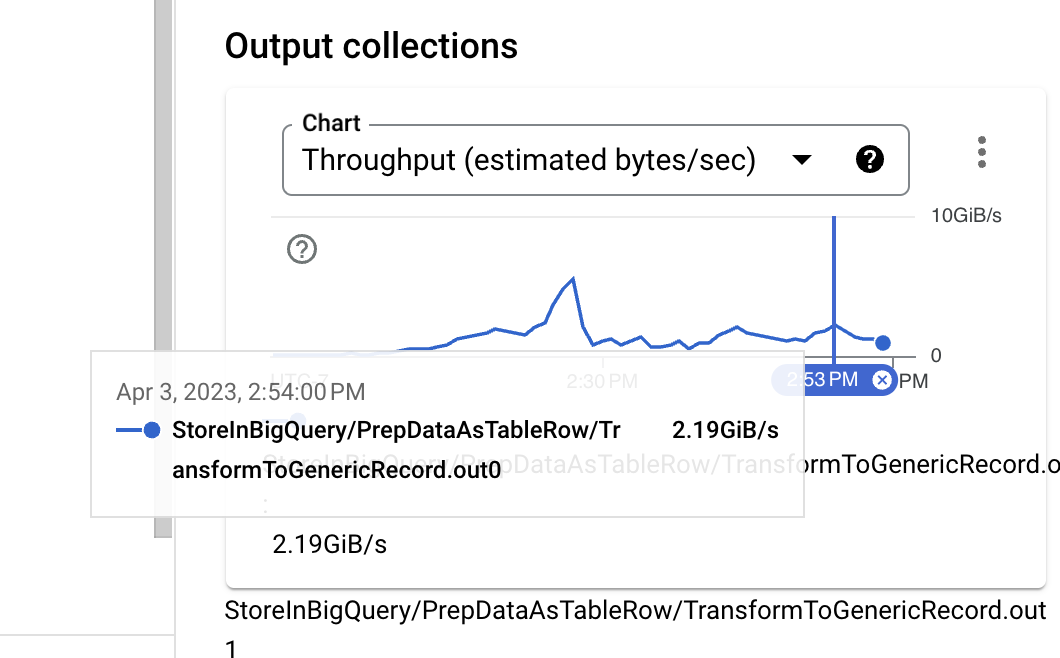
查看输入大小,在身份 UDF 执行之前,数据格式为二进制 Thrift,即使在没有使用压缩的情况下,它也是一种相当紧凑的格式。但是,在将 PCollection 的近似大小与 BigQuery 摄取所需的 TableRow 格式进行比较时,可以明显看到大小增加了。我们可以通过更改使用的 BigQuery 写入 API 来改进这一点。
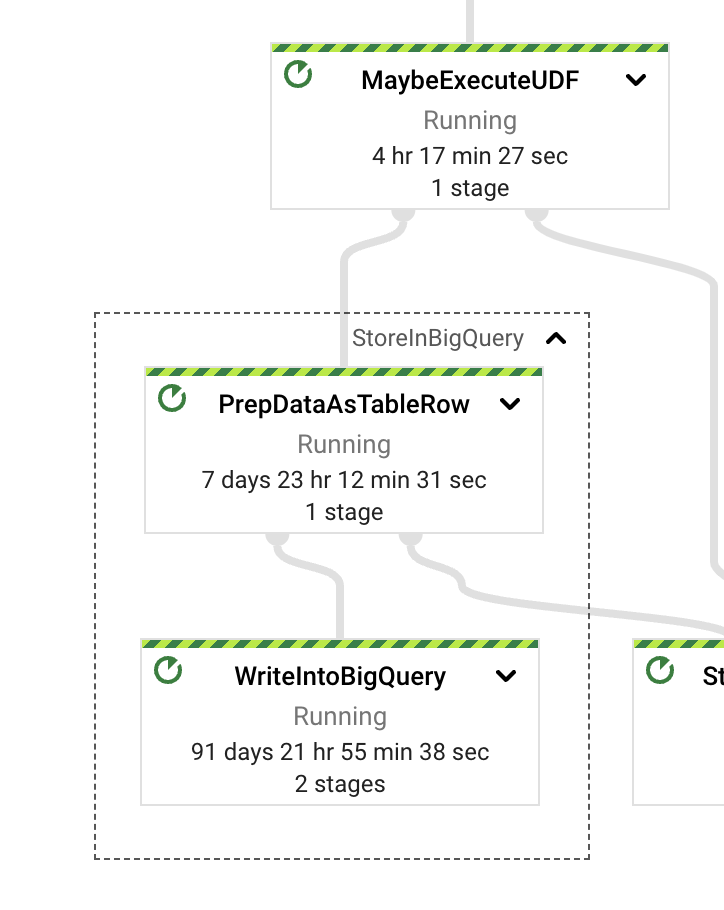
当我们检查 StoreInBigQuery 变换时,我们看到大部分的墙上时间都花在了实际写入上。此外,将数据转换为目标格式(TableRows)所花费的墙上时间与实际写入所花费的时间相比非常大:写入时间大 13 倍。为了改善这种行为,我们可以切换管道写入模式。
第四次运行:使用新的
在此运行中,我们使用 StorageWrite API。为该管道启用 StorageWrite API 很简单。我们将写入模式设置为 STORAGE_WRITE_API 并定义写入触发频率。对于此测试,我们最多每十秒写入一次数据。写入触发频率控制每个流数据累积的时间。较高的数字定义了流分配后要写入的更大输出,但也为从 Pub/Sub 读取的每个元素带来了更大的端到端延迟。与 STREAMING_WRITES 配置类似,BigQueryIO 可以处理写入的自动分片,我们已经证明这是性能的最佳设置。
在两个管道都稳定之后,使用 BigQueryIO 中的 StorageWrite API 所见到的性能优势显而易见。启用新实现后,格式转换和写入操作之间的墙上时间比率下降。写入所花费的墙上时间仅比格式转换大 34%。
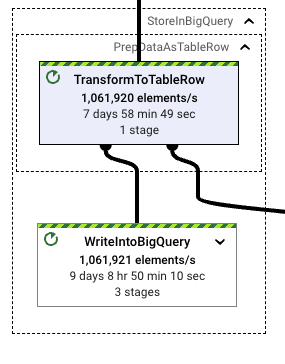
稳定之后,管道吞吐量也很平稳。运行器可以快速稳定地缩减维持所需吞吐量所需的管道资源。
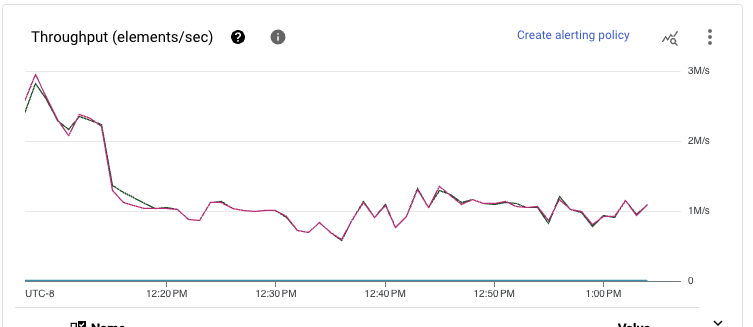
查看处理数据所需的资源规模,另一个显著的改进是可见的。基于流插入的管道需要超过 80 个工作进程才能维持吞吐量,而存储写入管道只需要 49 个,提高了 40%。
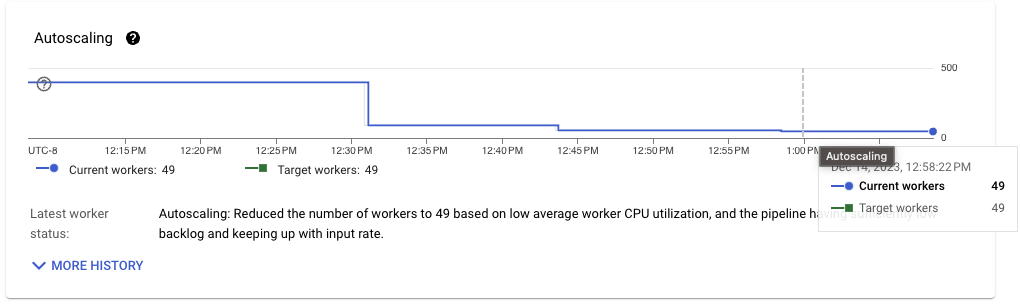
我们可以使用数据生成管道作为参考。该管道只需要随机生成数据并将事件写入 Pub/Sub。它稳定地运行,平均有 40 个工作进程。使用正确的工作负载配置对摄取管道进行改进使其更接近于生成所需的那些资源。
与基于流插入的管道类似,将数据写入 BigQuery 需要运行格式转换,从 Thrift 到 TableRow(在以前)以及从 Thrift 到 Protocol Buffers(protobuf)(在后者) 。因为我们正在使用 BigQueryIO.writeTableRows 方法,所以我们在格式转换中添加了另一个步骤。因为 TableRow 格式也增加了正在处理的 PCollection 的大小,所以我们想知道是否可以改进此步骤。
第五次运行:更好的写入格式
当使用 STORAGE_WRITE_API 时,BigQueryIO 变换公开了一种方法,我们可以使用它将 Beam 行类型直接写入 BigQuery。此步骤很有用,因为行类型为互操作性和模式管理提供了灵活性。此外,它既高效地用于混洗,也比 TableRow 更密集,因此我们的管道将具有更小的 PCollection 大小。
对于下一次运行,由于我们的数据量并不小,因此我们在写入 BigQuery 时降低了触发频率。因为我们使用的是不同的格式,所以运行的代码略有不同。对于此更改,测试管道脚本配置了标志 --formatToStore=BEAM_ROW。
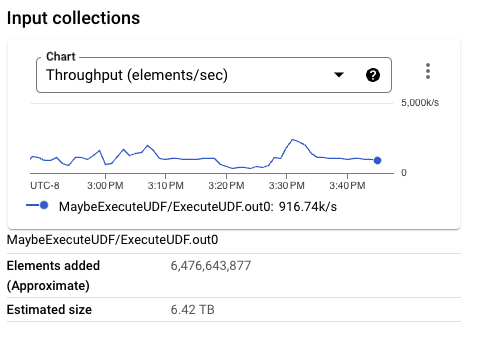
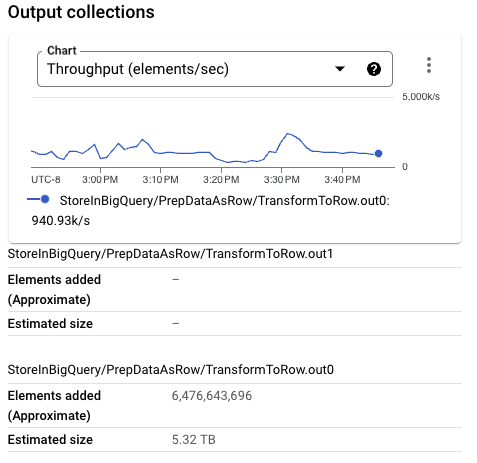
写入 BigQuery 的 PCollection 大小明显小于以前的执行。事实上,对于此特定执行,Beam 行格式的尺寸小于 Thrift 格式。较大的 PCollection 由更大的每个元素大小构成,这会在较小的工作进程配置中带来非凡的内存压力,从而降低整体吞吐量。
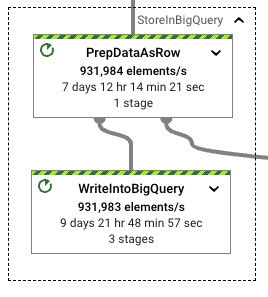
格式转换和实际 BigQuery 写入的挂钟速率也保持非常相似的速率。处理 Beam 行格式不会在格式转换和后续写入中造成性能损失。管道在吞吐量稳定时使用的工作进程数量可以证实这一点,它略小于前一次运行,但明显在同一范围内。
尽管我们已经比开始时处于一个好得多的位置,但考虑到我们的测试管道输入格式,仍然有改进的空间。
第六次运行:进一步减少格式转换工作
BigQueryIO 变换中对输入 PCollection 支持的另一种格式可能对我们的输入格式有利。方法 writeGenericRecords 使变换能够在写入操作之前将 Avro GenericRecords 直接转换为 protobuf。Apache Thrift 可以非常高效地转换为 Avro GenericRecords。我们可以通过在执行脚本上设置选项 --formatToStore=AVRO_GENERIC_RECORD 来进行另一个测试运行,从而配置我们的测试摄取管道。
这一次,格式转换和写入之间的差异显着增加,从而提高了性能。转换为 Avro GenericRecords 仅占将这些记录写入 BigQuery 所花费的写入工作量的 20%。考虑到测试管道具有相似的运行时间,并且在 WriteIntoBigQuery 阶段看到的挂钟时间也与其他与 StorageWrite 相关的运行一致,因此对于此工作负载来说,使用这种格式是合适的。
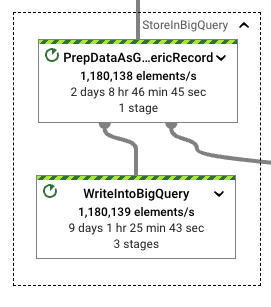
当我们查看资源利用率时,我们看到了进一步的收益。在实现所需吞吐量的同时,我们需要更少的 CPU 时间来执行工作负载的格式转换。
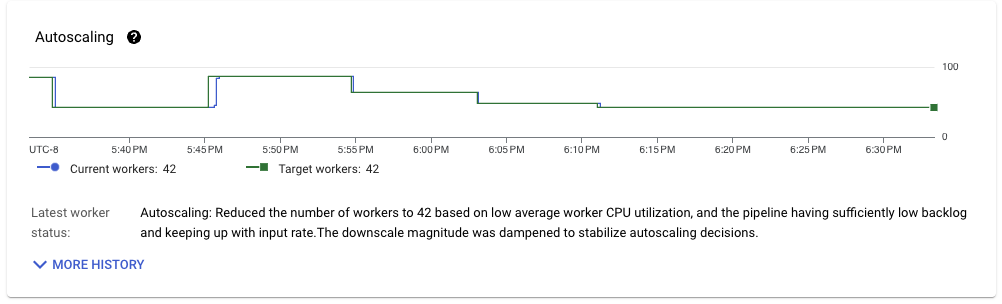
该管道改进了前一次运行,在吞吐量稳定时稳定地运行在 42 个工作进程上。考虑到使用的工作进程配置(nd2-standard-4)和工作负载处理的体积吞吐量(大约 1 GB/s),我们每 CPU 内核实现了大约 6 MB/s 的吞吐量,对于具有完全一次语义的流管道来说,这非常令人印象深刻。
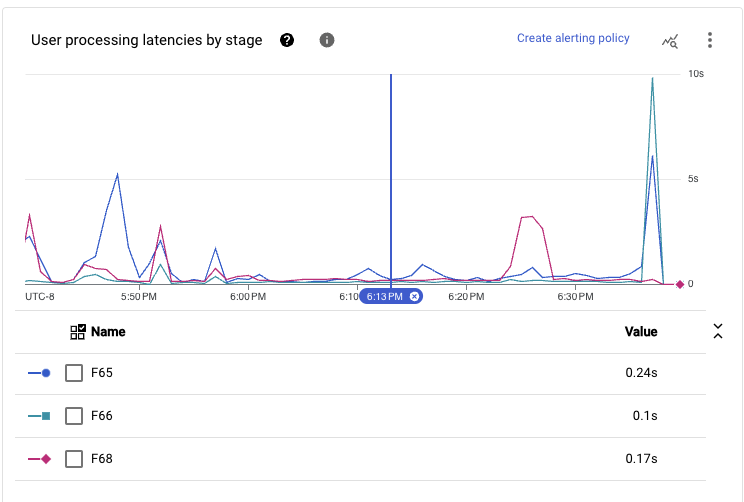
当我们将管道主路径中执行的所有阶段加起来时,在此规模上看到的延迟在持续时间内实现了亚秒级端到端延迟。
鉴于工作负载要求和已实现的管道代码,这种性能是我们无需进一步调整运行器特定设置即可获得的最佳性能。
第七次运行:放松一些约束
当将 STORAGE_WRITE_API 设置用于 BigQueryIO 时,我们会在写入上强制执行完全一次语义。此配置非常适合需要对处理的数据进行强一致性的用例,但会造成性能和成本损失。
从高级的角度来看,写入 BigQuery 是分批进行的,这些批次是根据当前分片和触发频率发布的。如果在执行特定捆绑包期间写入失败,则会重试。只有当特定捆绑包中的所有数据都正确附加到流中时,该捆绑包中的数据才会提交到 BigQuery。此实现需要混洗数据的全部体积以创建要写入的批次,以及用于稍后提交的已完成批次的信息(尽管与第一个相比,这最后一个部分非常小)。
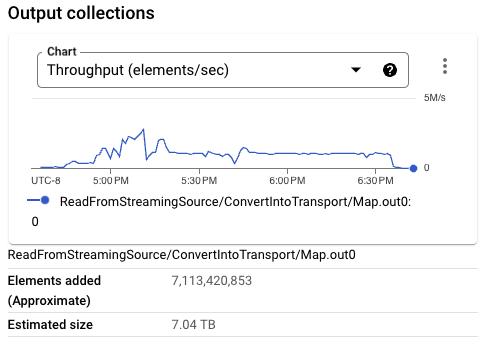
查看以前的管道执行,流式引擎为管道处理的总数据量大于从 Pub/Sub 读取的数据量。例如,从 Pub/Sub 读取了 7 TB 的数据,而整个管道执行的数据处理将 25 TB 的数据从流式引擎移入移出。

当数据一致性不是摄取的硬性要求时,您可以将 BigQueryIO 写入模式与至少一次语义一起使用。此实现避免了为写入混洗和分组数据。但是,此更改可能会导致少量重复行写入目标表。这可能会在追加错误、不频繁的工作进程重启和其他更不频繁的错误的情况下发生。
因此,我们添加了使用 STORAGE_API_AT_LEAST_ONCE 写入模式的配置。为了指示 StorageWrite 客户端在写入数据时重用连接,我们还添加了配置标志 –useStorageApiConnectionPool。此配置选项仅适用于 STORAGE_API_AT_LEAST_ONCE 模式,它减少了类似于 Storage Api write delay more than 8 seconds 的警告的出现。
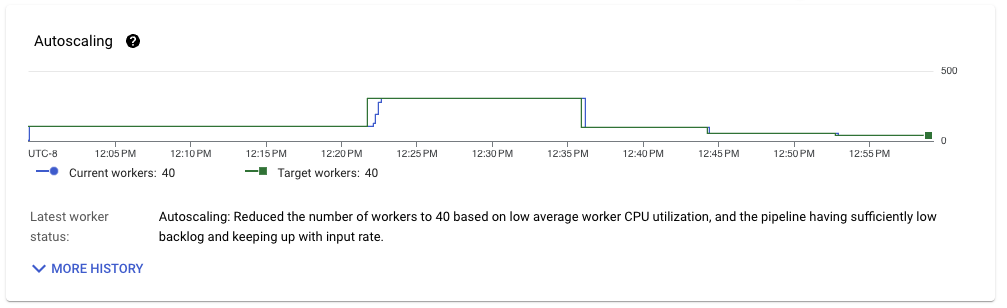
当管道吞吐量稳定时,我们看到了工作负载资源利用率的类似模式。使用的工作进程数量达到 40 个,与上次运行相比略有改进。但是,从流式引擎移动的数据量更接近于从 Pub/Sub 读取的数据量。
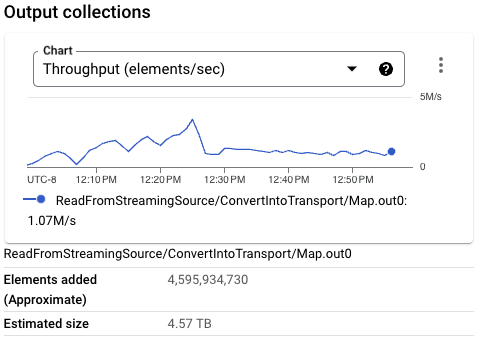

考虑到所有这些因素,此更改进一步优化了工作负载,每 CPU 内核的吞吐量达到了 6.4 MB/s。与在将数据一致写入 BigQuery 时使用相同工作负载相比,这种改进很小,但它使用更少的流数据资源。此配置代表了工作负载的最优设置,具有最高的每资源吞吐量和最少的跨工作进程的流数据。
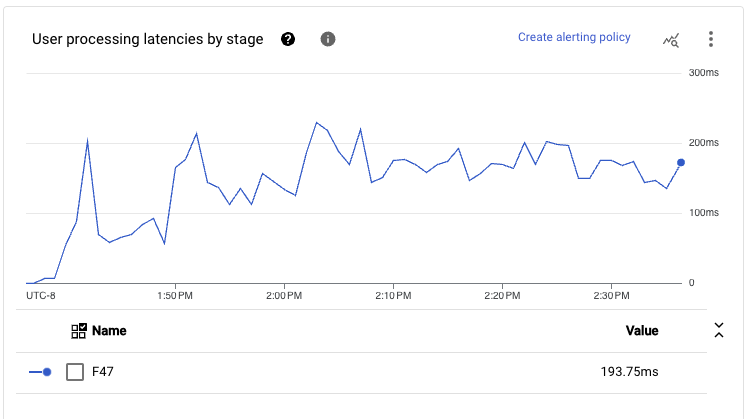
此配置的端到端处理延迟也令人印象深刻地低。考虑到管道主路径已在从读取到写入的单个执行阶段中融合,我们发现即使在 p99 处,延迟在非常大的体积吞吐量下(如之前提到的约 1 GB/s)也往往低于 300 毫秒。
总结
为了优化 Apache Beam 流式工作负载以实现低延迟和高效执行,需要仔细分析和决策,以及正确的配置。
考虑到本文中讨论的场景,除了为工作负载编写正确的管道外,还必须考虑诸如总体 CPU 利用率、每个阶段的吞吐量和延迟、PCollection 大小、每个阶段的墙上时间、写入模式和传输格式等因素。
我们的实验表明,使用 StorageWrite API、写入的自动分片以及 Avro GenericRecords 作为传输格式产生了最有效的结果。放松写入的一致性可以进一步提高性能。
随附的 Github 存储库 包含一个测试套件,您可以使用它在您的 Google Cloud 项目上或使用不同的运行器设置来复制分析。请随时试用它。评论和 PR 始终受欢迎。