



博客
2023/10/02
使用 Apache Beam 自建 GenAI 内容发现平台
使用 Apache Beam 自建 GenAI 内容发现平台
您的数字资产,例如文档、PDF、电子表格和演示文稿,包含大量有价值的信息,但有时很难找到您要查找的内容。这篇博文将解释如何构建一个 DIY 初始架构,它基于近实时数据摄取处理和大型语言模型 (LLM),从您的资产中提取有意义的信息。该模型通过简单的自然语言查询使信息可用并可发现。
构建用于内容摄取的近实时处理管道可能看起来是一项复杂的任务,而且确实如此。为了简化管道构建,Apache Beam 框架提供了一组强大的构造。这些构造消除了以下复杂性:与多种内容源和目标进行交互、错误处理和模块化。它们还以最小的努力保持弹性和可扩展性。您可以使用 Apache Beam 流管道来完成以下任务
- 连接到解决方案的多个组件。
- 快速处理文档的内容摄取请求。
- 在摄取后几秒钟内使文档中的信息可用。
LLM 通常用于提取存储在许多不同位置的内容并汇总信息。组织可以使用 LLM 快速找到分散在多年来撰写的多个文档中的相关信息。这些信息可能以不同的格式存在,或者文档可能太长太复杂,无法快速阅读和理解。使用 LLM 处理这些内容,使人们更容易找到他们需要的信息。
按照本指南中的步骤,为数据提取、内容摄取和存储创建自定义可扩展解决方案。了解如何使用 Google Cloud 产品和生成式 AI 产品来启动基于 LLM 的解决方案的开发。Google Cloud 旨在易于使用、可扩展且灵活,因此您可以将其用作进一步扩展或实验的起点。
高级流程
在此工作流程中,内容获取和查询交互完全分离。外部内容所有者可以发送存储在 Google Docs 中或以二进制文本格式存储的文档,并接收摄取请求的跟踪 ID。摄取过程获取文档的内容并创建大小可配置的块。每个文档块都用于生成嵌入。这些嵌入表示内容语义,以 768 维向量形式表示。给出文档标识符和块标识符,您可以在向量数据库中存储嵌入以进行语义匹配。此过程对于将用户查询上下文化至关重要。
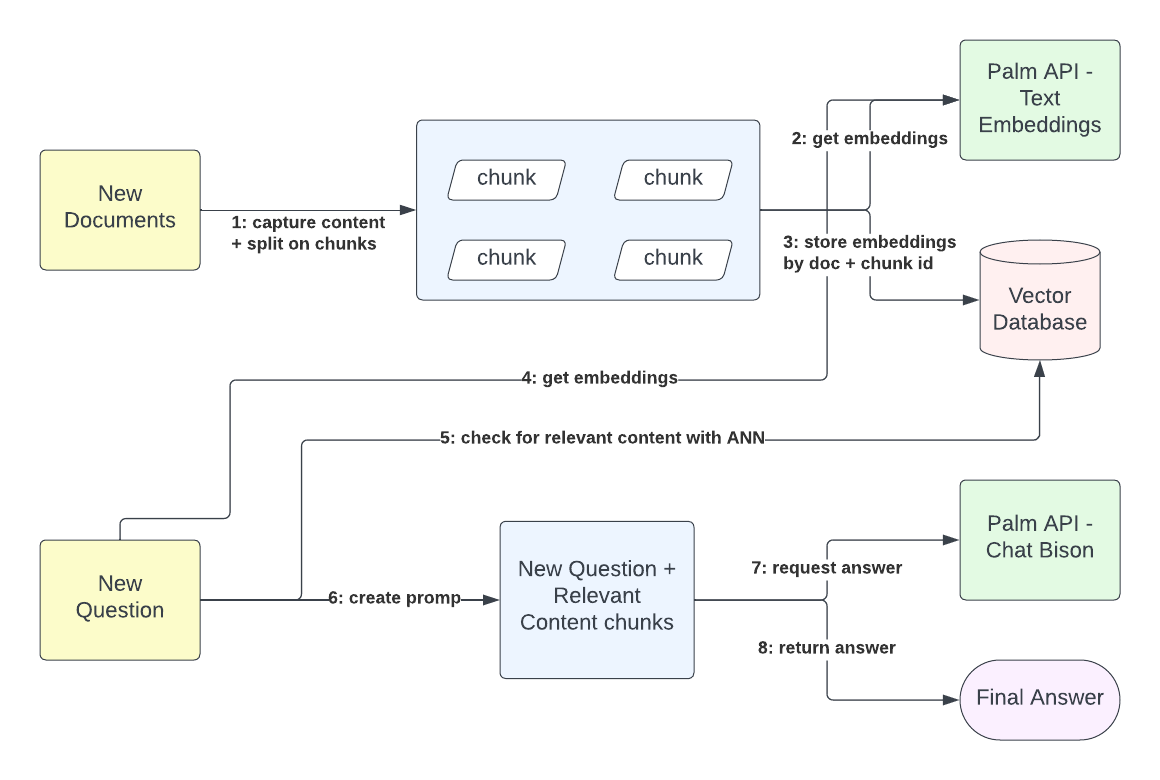
查询解析过程不直接依赖于信息摄取。用户会根据直到查询请求时为止摄取的内容收到相关答案。即使平台没有存储任何相关内容,平台也会返回一个答案,说明它没有相关内容。因此,查询解析过程首先从查询内容和先前存在的上下文中生成嵌入,例如与平台的先前交互,然后将这些嵌入与从内容存储的现有嵌入向量进行匹配。当平台具有正匹配时,它会检索由内容嵌入表示的纯文本内容。最后,通过使用查询的文本表示和匹配内容的文本表示,平台会向 LLM 发出请求,以提供对原始用户查询的最终答案。
解决方案的组件
使用 Google Cloud 服务的低运营能力来创建一组高度可扩展的功能。您可以将解决方案分为两个主要组件:服务层和内容摄取管道。服务层充当文档摄取和用户查询的入口点。它是一组简单的 REST 资源,通过 Cloud Run 公开,并通过使用 Quarkus 和客户端库来访问其他服务(Vertex AI 模型、Cloud Bigtable 和 Pub/Sub)来实现。内容摄取管道包括以下组件
- 一个从其驻留位置捕获用户内容的流管道。
- 一个从这些内容中提取含义作为一组多维向量(文本嵌入)的过程。
- 一个存储系统,简化了知识内容和用户查询之间的上下文匹配(向量数据库)。
- 另一个存储系统,将知识表示与实际内容映射,形成查询的聚合上下文。
- 一个能够理解聚合上下文并通过提示工程提供有意义答案的模型。
- 基于 HTTP 和 gRPC 的服务。
这些组件共同为内容发现平台提供了一个全面而简单的实现。
工作流程架构
本节说明不同组件之间的交互方式。
组件的依赖关系
以下图表显示了平台集成的所有组件。它还显示了解决方案组件和 Google Cloud 服务之间存在的所有依赖关系。
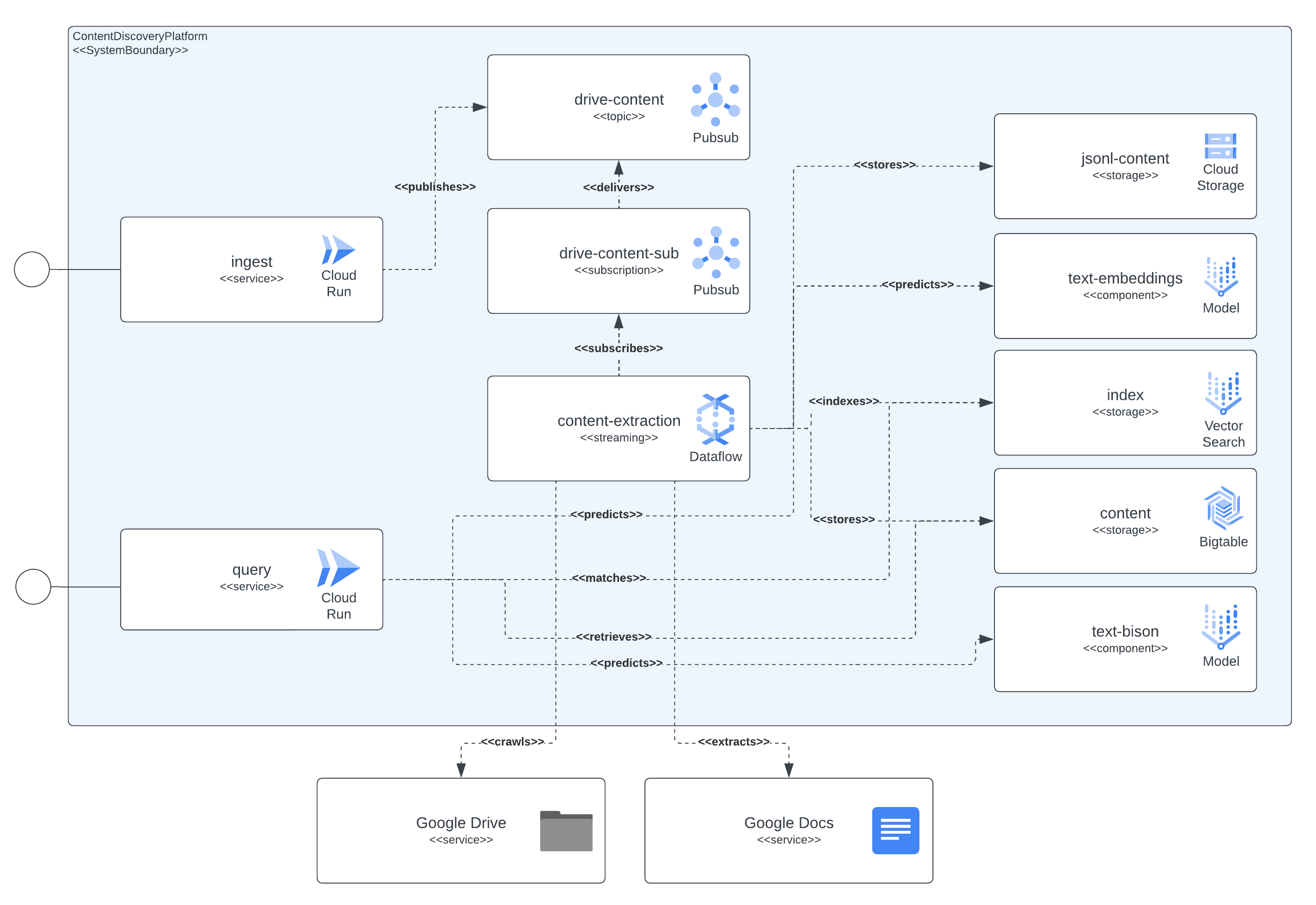
如该图所示,上下文提取组件是负责检索文档内容以及其从嵌入模型中的语义含义并存储相关数据(块文本内容、块嵌入、JSON-L 内容)在持久性存储系统中供以后使用的核心部分。PubSub 资源是流管道和异步处理之间的粘合剂,捕获用户摄取请求、摄取管道中潜在错误的重试(例如文档已发送到摄取但权限尚未授予的情况,在几分钟后触发重试)和内容刷新事件(管道会定期扫描已摄取的文档,查看最新版本并确定是否应触发内容刷新)。
上下文提取组件检索文档的内容,将其划分为块。它还使用 LLM 交互从提取的内容计算嵌入。然后,它将相关数据(块文本内容、块嵌入、JSON-L 内容)存储在持久性存储系统中以供以后使用。Pub/Sub 资源连接流管道和异步处理,捕获以下操作
- 用户摄取请求
- 摄取管道中错误的重试,例如文档已发送到摄取但缺少访问权限
- 内容刷新事件(管道会定期扫描已摄取的文档,查看最新版本并确定是否应触发内容刷新)
此外,CloudRun 在公开服务方面发挥着重要作用,它与许多 Google Cloud 服务进行交互以解决用户查询或摄取请求。例如,在解决查询请求时,服务将
- 通过与嵌入模型交互来请求计算用户查询的嵌入
- 使用查询嵌入表示从 Vertex AI 向量搜索(以前称为匹配引擎)中查找最近邻匹配
- 使用其标识符从 BigTable 检索这些匹配向量的文本内容,以对 LLM 提示进行上下文化
- 最后,创建一个对 VertexAI Chat-Bison 模型的请求,生成系统将传递给用户查询的响应。
Google Cloud 产品
本节介绍解决方案中使用的 Google Cloud 产品和服务及其用途。
Cloud Build:所有容器映像(包括服务和管道)都是使用 Cloud Build 直接从源代码构建的。使用 Cloud Build 简化了解决方案部署期间的代码分发。
CloudRun:解决方案的服务入口点由 CloudRun 部署并自动扩展。
Pub/Sub:一个 Pub/Sub 主题和订阅排队所有 Google Drive 或自包含内容的摄取请求,并将请求传递到管道。
Dataflow:一个多语言、流式 Apache Beam 管道处理摄取请求。这些请求从 Pub/Sub 订阅发送到管道。管道从 Google Docs、Google Drive URL 和自包含二进制编码文本内容中提取内容。然后,它生成内容块。这些块被发送到 Vertex AI 基礎模型之一以进行嵌入表示。来自文档的嵌入和块被发送到 Vertex AI 向量搜索和 Cloud Bigtable 以进行索引和快速访问。最后,已摄取的文档存储在 Google Cloud Storage 中的 JSON-L 格式,可用于微调 Vertex AI 模型。通过使用 Dataflow 运行 Apache Beam 流管道,您可以最大限度地减少扩展资源所需的运营。如果您在摄取请求上有突发情况,Dataflow 可以将延迟保持在不到一分钟。
Vertex AI - 向量搜索:向量搜索 是一种高性能、低延迟向量数据库。这些向量数据库通常称为向量相似性搜索或近似最近邻 (ANN) 服务。我们使用向量搜索索引来存储所有已摄取文档的嵌入作为含义表示。这些嵌入按块和文档 ID 进行索引。稍后,这些标识符可用于对用户查询进行上下文化,并通过提供直接从存储在 BigTable 上的文档内容映射中提取的知识(使用相同的块文档标识符)来丰富发送到 LLM 的请求。
Cloud BigTable:此存储系统通过标识符提供可预测规模的低延迟搜索。考虑到请求解析的低延迟,它非常适合在线交换用户查询和平台组件交互。它用于存储从文档中提取的内容,因为它按块和文档标识符进行索引。每次用户向查询服务发出请求时,并在查询文本嵌入解析并与现有上下文匹配后,文档和块 ID 用于检索将用作上下文以向正在使用的 LLM 请求答案的文档内容。此外,BigTable 用于跟踪用户与平台之间的对话交换,从而进一步丰富发送到 LLM(嵌入、汇总、聊天问答)的请求中包含的上下文。
Vertex AI - 文本嵌入模型:文本嵌入 是文本片段的压缩向量(数字)表示。如果两个文本片段在语义上相似,则它们相应的嵌入将在嵌入向量空间中彼此靠近。有关更多详细信息,请参阅 获取文本嵌入。这些嵌入在处理文档内容和查询服务时被摄取管道直接使用,作为将用户查询语义与向量搜索中索引的现有内容进行匹配的输入。
Vertex AI - 文本摘要模型: Text-bison 是一个 PaLM 2 LLM,它能够理解、概括和生成文本。Text-bison 可以创建的文本类型包括文档摘要、问题的答案以及对提供输入内容进行分类的标签。我们使用这个 LLM 来概括之前维护的对话,目的是丰富用户的查询并更好地进行嵌入匹配。简而言之,用户不必在自己的问题中包含所有上下文,我们可以从对话历史记录中提取和概括它。
Vertex AI - 文本聊天模型: Chat-bison 是一个 PaLM 2 LLM,擅长语言理解、语言生成和对话。这个聊天模型经过微调,可以进行自然的多次对话,非常适合需要来回交互的代码相关文本任务。我们使用这个 LLM 来回答用户提出的问题,其中包括双方之间的对话历史,并用解决方案中存储的内容丰富模型的上下文。
提取管道
内容提取管道是平台的核心。它负责处理内容提取请求,提取文档内容并计算这些内容的嵌入,最终将数据存储在专门的存储系统中,这些存储系统将被查询服务组件用于快速访问。
高级视图
如前所述,管道使用 Apache Beam 框架实现,并以流式方式在 GCP 的 Dataflow 服务上运行。
通过使用 Apache Beam 和 Dataflow,我们可以确保最小延迟(亚分钟处理时间)、低操作(当流量峰值发生时,无需手动扩展或缩减管道,包括工作器循环、更新等)、以及高可观察性(提供清晰且丰富的性能指标)。

在高级别上,管道将提取、计算、错误处理和存储职责分别分配给不同的组件或 PTransforms。如图所示,消息从 PubSub 订阅中读取,然后立即包含在窗口定义中,之后进行内容提取。
每个 PTransforms 可以扩展以显示有关实现的底层阶段的更多详细信息。我们将在后面的部分深入探讨每个 PTransforms。
该管道使用多语言方法实现,主要组件用 Java 语言(JDK 版本 17)编写,与嵌入计算相关的组件用 Python(版本 3.11)编写,因为 Vertex AI API 客户端适用于这种语言。
内容提取
内容提取组件负责检查提取请求有效载荷,并根据事件属性决定是否需要从事件本身(自包含内容,基于文本的文档二进制编码)中检索内容,或者从 Google Drive 中检索内容。
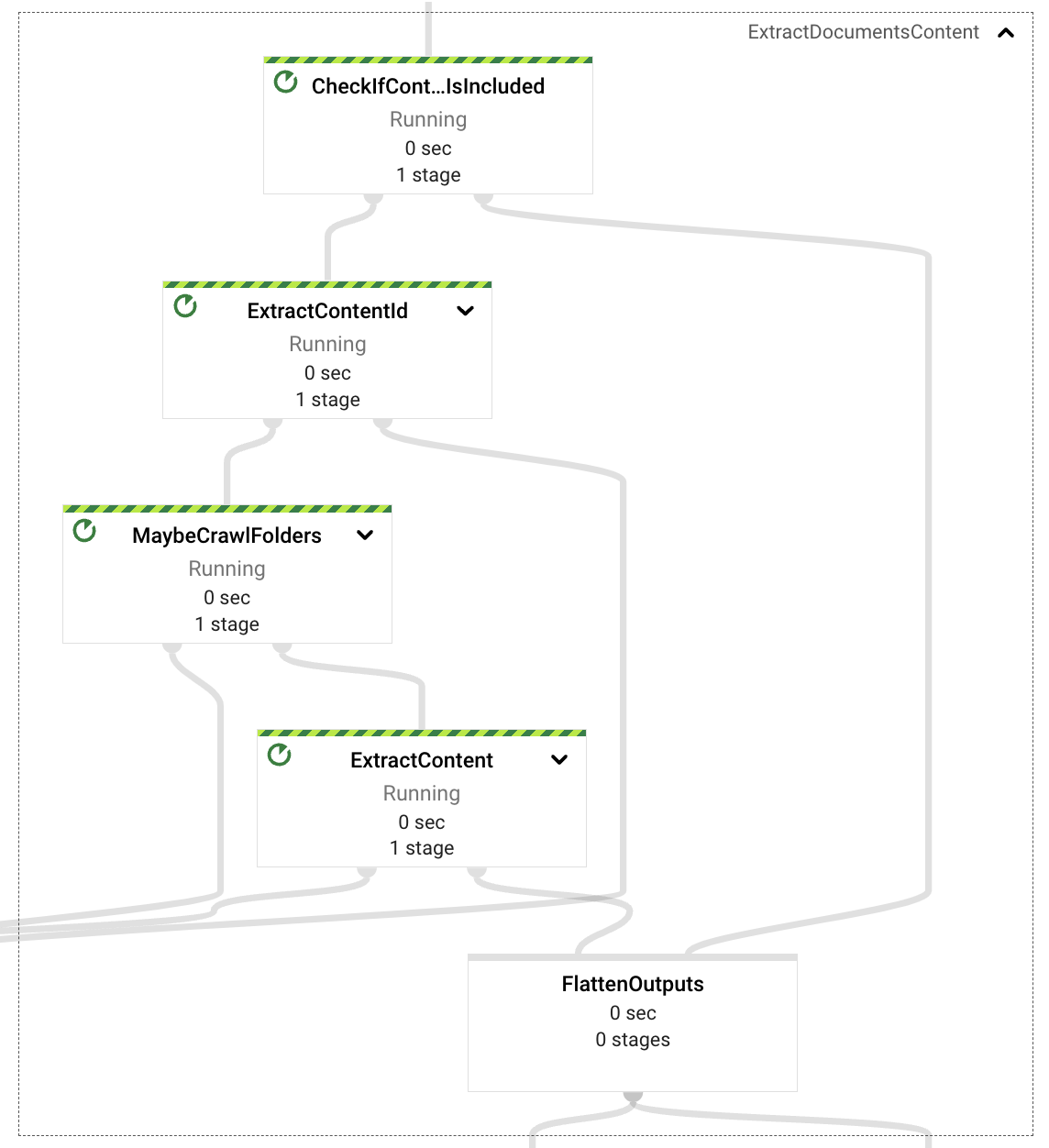
对于自包含文档,管道将提取文档 ID 并将文档格式化为段落,以便在后续的嵌入处理中使用。
如果需要从 Google Drive 检索,管道将检查事件中提供的 URL 是否指向 Google Drive 文件夹或单个文件格式(支持的格式包括文档、电子表格和演示文稿)。如果是文件夹,管道将递归地爬取文件夹的内容,提取所有支持格式的文件;如果是单个文档,则只返回该文档。
最后,从提取请求中检索到所有文件引用后,将从文件中提取文本内容(此 PoC 未实现图像支持)。该内容也将传递到嵌入处理阶段,包括文档标识符和作为段落的内容。
错误处理
在内容提取过程的每个阶段,都可能遇到各种错误,例如格式错误的提取请求、不符合规范的 URL、Drive 资源权限不足、文件数据检索权限不足。
在所有这些情况下,一个专门的组件将捕获这些潜在的错误,并根据错误的性质决定是否应该重试事件,或者将其发送到一个死信 GCS 存储桶以供日后检查。
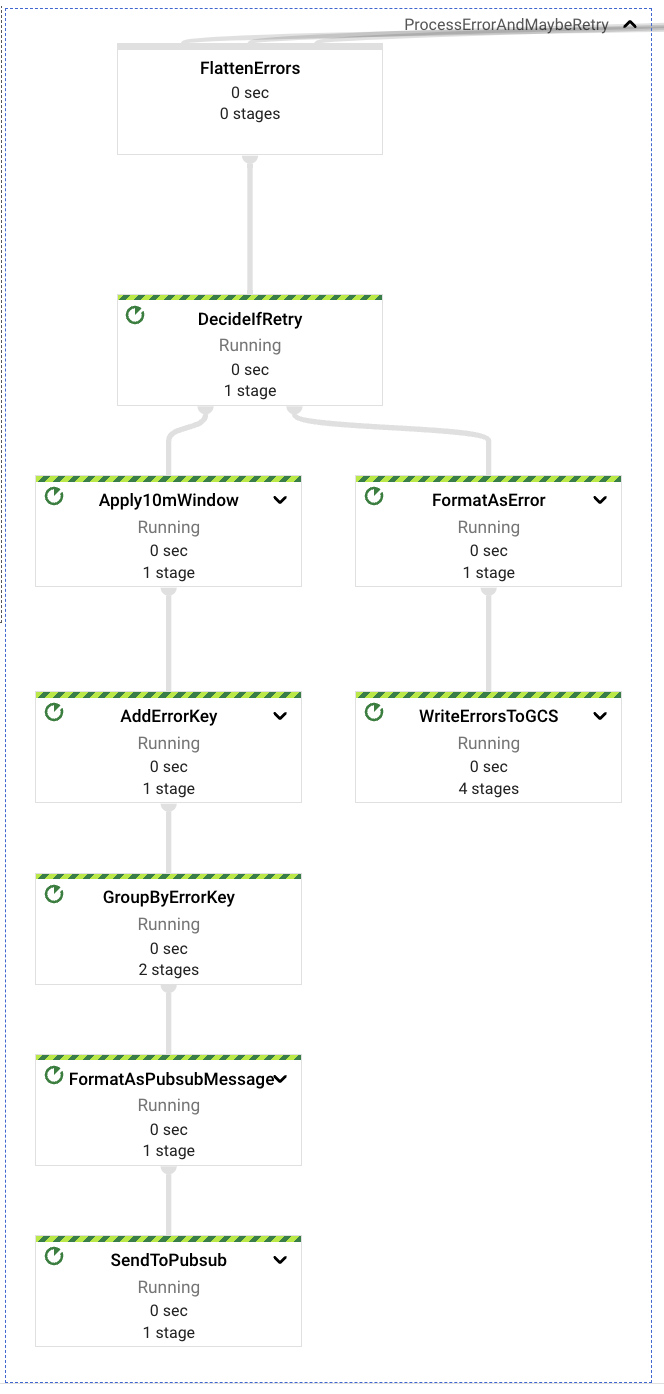
最终错误,或那些不会被重试的错误,是与错误请求格式(事件本身或属性内容,例如格式错误或错误的 URL 等)相关的错误。
可重试错误是与内容访问和权限不足相关的错误。请求的解决速度可能比为运行管道的服务帐户提供访问提取请求中包含的资源(Google Drive 文件夹或文件)的正确权限的手动过程快。如果检测到可重试错误,管道将在重新发送消息到上游 PubSub 主题之前保留重试 10 分钟;每个错误最多重试 5 次,然后再发送到死信 GCS 存储桶。
在所有以死信目标结束的事件中,必须通过手动过程进行检查和重新处理。
处理嵌入
从请求中提取内容或从 Google Drive 文件中捕获内容后,管道将触发嵌入计算过程。如前所述,与 Vertex AI 基础模型 API 的交互是用 Python 语言实现的。因此,我们需要将提取的内容格式化为 Java 类型,这些类型可以直接转换为 Python 世界中的类型。这些类型包括键值对(在 Python 中是 2 元素元组)、字符串(在两种语言中都可用)和可迭代对象(在两种语言中也都可用)。我们可以在两种语言中都实现编码器以支持自定义传输类型,但我们选择放弃这种做法,以追求清晰度和简单性。
在计算内容的嵌入之前,我们决定引入一个重新洗牌步骤,使输出对下游阶段保持一致,目的是避免在出现错误的情况下重复内容提取步骤。这应该可以避免对与 Google Drive 相关的 API 的现有访问配额施加压力。
然后,管道将内容分成可配置的大小,并进行可配置的重叠。对于通用的有效数据提取,很难获得好的参数,因此我们选择使用较小的块和较小的重叠因子作为默认设置,以支持文档结果的多样性(至少从我们获得的经验结果来看是这样的)。
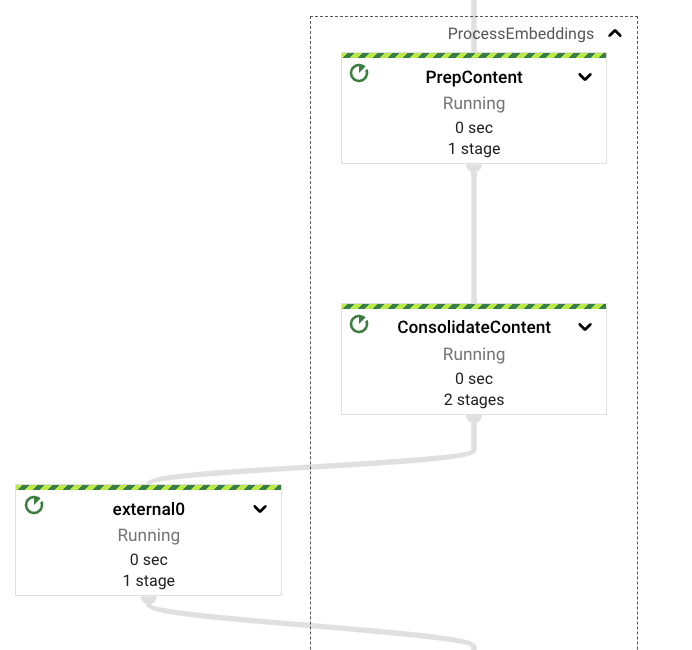
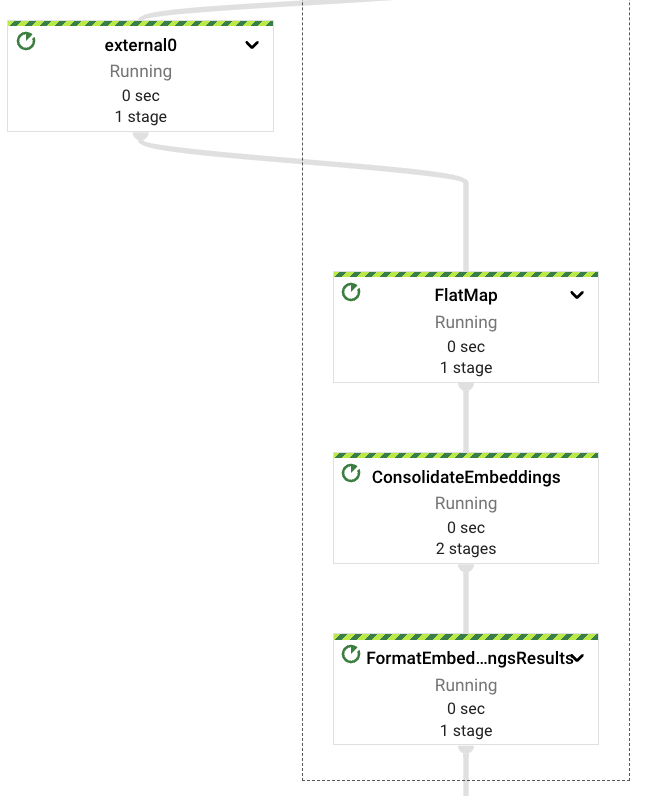
从嵌入 Vertex AI LLM 中检索到嵌入向量后,我们将再次合并它们,避免在出现下游错误的情况下重复此步骤。
值得注意的是,此管道直接与 Vertex AI 模型交互,使用客户端 SDK,Apache Beam 已经通过 RunInference PTransform 提供了对这种交互的支持(请参见 此处 的示例)。
内容存储
为从提取的文档中提取的内容块计算嵌入后,我们需要将向量存储在可搜索的存储中,并将与这些嵌入相关的文本内容也存储起来。我们将在查询服务中使用嵌入向量作为语义匹配,并将与这些嵌入相对应的文本内容用作 LLM 上下文,以此来改进和引导响应预期。
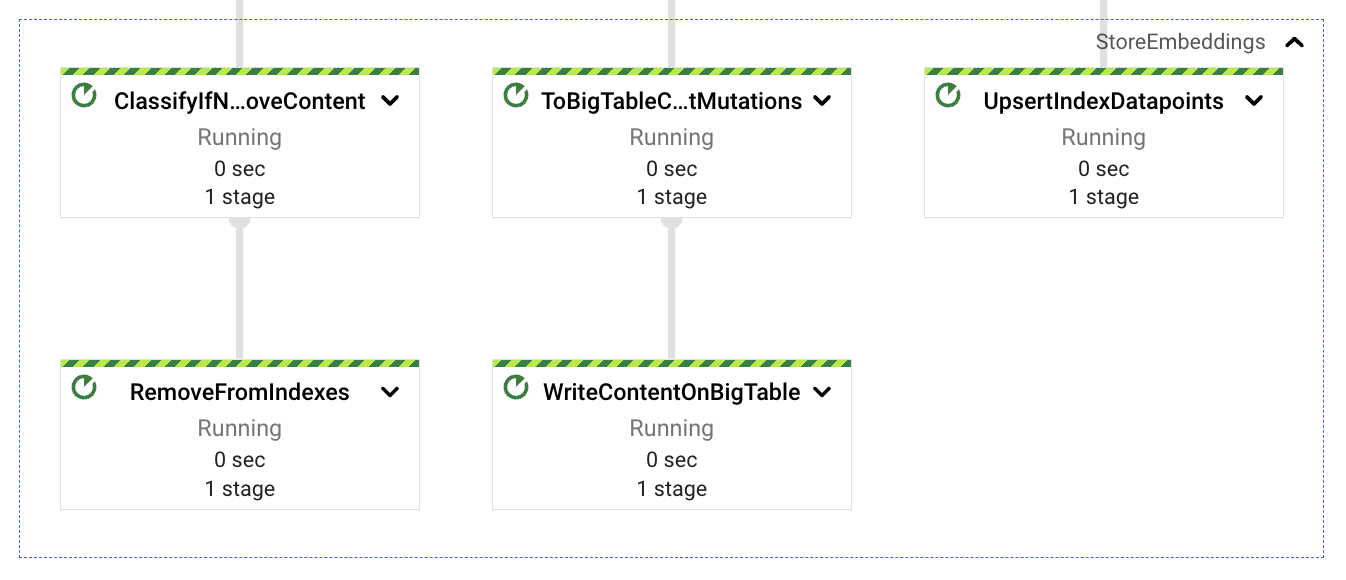
考虑到这一点,我们将合并的嵌入分成 3 条路径:一条路径将向量存储到 Vertex AI 向量搜索中(使用简单的 REST 调用),另一条路径将文本内容存储到 BigTable 中(用于在语义匹配后进行低延迟检索),最后一条路径作为潜在的清理内容刷新或重新提取的路径(稍后详细介绍)。这三条路径都使用提取的文档标识符作为相关数据,该标识符由文档名称(如果有)、文档标识符和块序列号组成。使用块标识符的原因是考虑到了后续更新。内容的增加会产生更多数量的块,上载所有块将始终能够使用最新的数据;相反,内容的减少会为文档内容生成更少的块数量,此数量差异可以用于删除剩余的孤儿索引块(来自不再存在于文档最新版本中的内容)。
内容刷新
最后一个管道组件是最简单的,至少从概念上来说是这样。从 Google Drive 中提取文档后,外部用户可以在这些文档中进行更新,导致索引的内容过时。我们实现了一个简单的周期性进程,该进程位于同一个流式管道中,负责检查已经提取的文档,并查看是否需要内容更新。我们使用 GenerateSequence 变换来产生一个周期性脉冲(默认情况下每 6 小时一次),该脉冲将触发对 BigTable 的扫描,检索所有提取的文档标识符。有了这些标识符,我们就可以查询 Google Drive 以获取每个文档的最新更新时间戳,并使用该标记来决定是否需要更新。
如果需要更新文档的内容,我们可以简单地向上游 PubSub 主题发送一个提取请求,并让管道运行其针对此新事件的流程。由于我们负责上载嵌入并清理不再存在的嵌入,因此我们应该能够处理大多数添加操作(只要这些操作是文本更新,因为目前图像内容尚未被处理)。
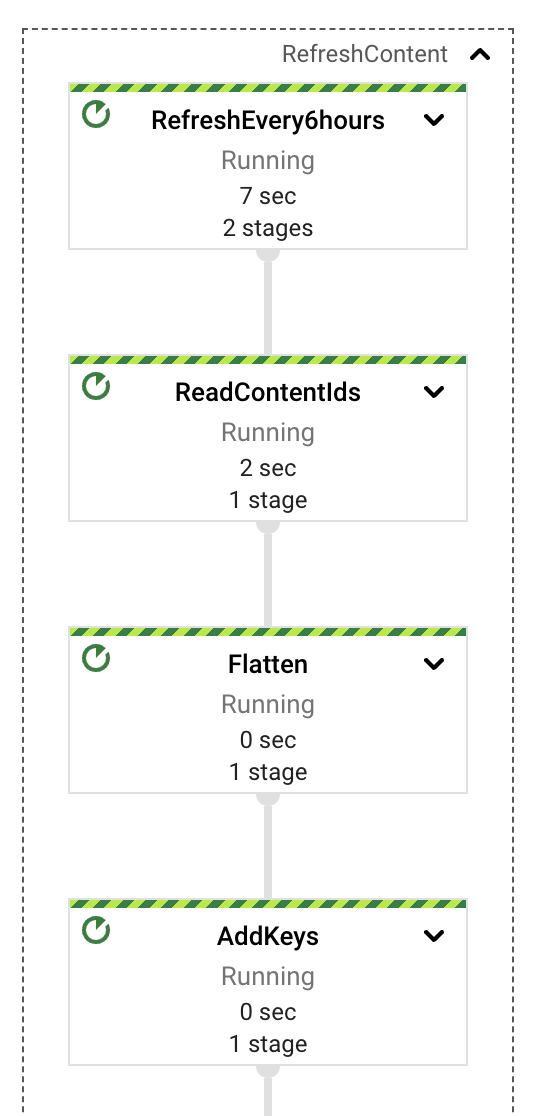
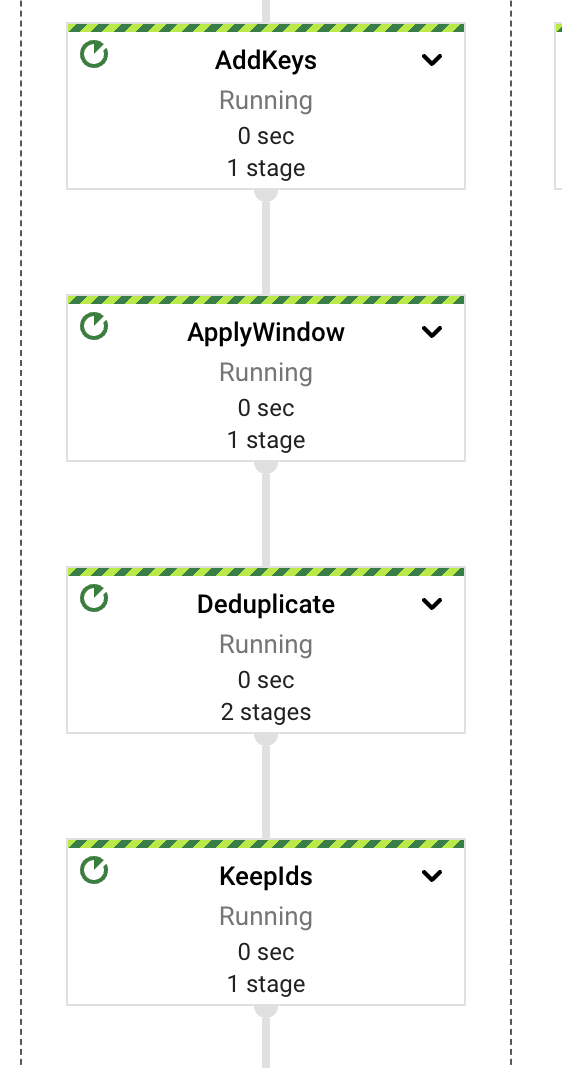
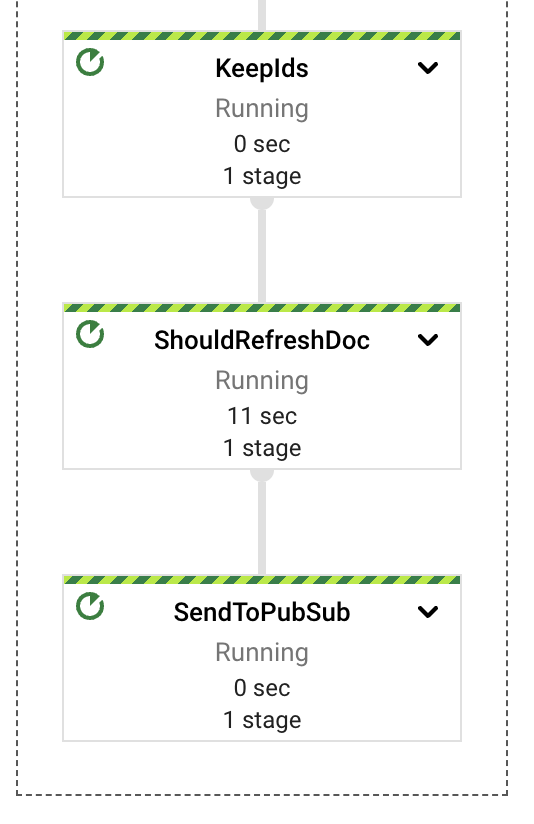
这项任务可以作为单独的工作来执行,可能是一项以批处理形式定期安排的工作。这将导致更低的成本、独立的错误域以及更可预测的自动扩展行为。但是,为了演示目的,使用一个作业更简单。
接下来,我们将重点关注解决方案如何与外部客户端交互,以实现提取和内容发现用例。
交互设计
该解决方案旨在尽可能简化平台提取和查询的交互。此外,由于提取部分可能意味着与多个服务进行交互,并意味着重试或内容刷新,因此我们决定将它们分开并异步执行,使外部用户在等待请求解决时不会阻塞自己。
交互示例
在将平台部署到 GCP 项目中后,与服务交互的一种简单方法是通过使用 Web 客户端,curl 就是一个很好的例子。此外,由于端点已通过身份验证,因此客户端需要在请求标头中包含其凭据以获得访问权限。
以下是一个内容提取交互的示例:
$ > curl -X POST -H "Content-Type: application/json" -H "Authorization: Bearer $(gcloud auth print-identity-token)" https://<service-address>/ingest/content/gdrive -d $'{"url":"https://drive.google.com/drive/folders/somefolderid"}' | jq .
# response from service
{
"status": "Ingestion trace id: <some identifier>"
}
在本例中,在将提取请求发送到 PubSub 主题以进行处理后,服务将返回跟踪标识符,该标识符与 PubSub 消息标识符相对应。请注意,提供的 URL 可以是 Google Doc 或 Google Drive 文件夹,在后一种情况下,提取过程将递归地爬取文件夹的内容以检索所有包含的文档及其内容。
接下来是一个内容查询交互的示例,与前一个示例非常类似:
$ > curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<service-address>/query/content \
-d $'{"text":"summarize the benefits of using VertexAI foundational models for Generative AI applications", "sessionId": ""}' \
| jq .
# response from service
{
"content": "VertexAI Foundation Models are a set of pre-trained models that can be used to accelerate the development of machine learning applications. They are available for a variety of tasks, including natural language processing, computer vision, and recommendation systems.\n\nVertexAI Foundation Models can be used to improve the performance of Generative AI applications by providing a starting point for model development. They can also be used to reduce the amount of time and effort required to train a model.\n\nIn addition, VertexAI Foundation Models can be used to improve the accuracy and robustness of Generative AI applications. This is because they are trained on large datasets and are subject to rigorous quality control.\n\nOverall, VertexAI Foundation Models can be a valuable resource for developers who are building Generative AI applications. They can help to accelerate the development process, reduce the cost of development, and improve the performance and accuracy of applications.",
"previousConversationSummary": "",
"sourceLinks": [
{
"link": "<possibly some ingested doc url/id>",
"distance": 0.7233397960662842
}
],
"citationMetadata": [
{
"citations": []
}
],
"safetyAttributes": [
{
"categories": [],
"scores": [],
"blocked": false
}
]
}
该平台将使用 LLM 返回文本响应,并将包含有关内容分类、引用元数据和源链接(如果有)的信息(例如,平台之前提取的文档的 Google Docs 链接)。
当与服务交互时,一个好的查询通常会返回好的结果,查询越清晰,就越容易理解其含义,并向LLM发送更准确的信息以检索答案。 但是,在每次与服务的交互中都必须在短语中包含查询上下文的全部细节,这可能会非常繁琐和困难。 为了解决这个问题,平台可以使用提供的会话标识符来存储用户与平台之间所有之前的交互。 这将有助于实现更好地理解初始查询嵌入的匹配,甚至在模型请求中提供更简洁的上下文信息。 以下是一个上下文交互的示例。
$ > curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<service-address>/query/content \
-d $'{"text":"summarize the benefits of using VertexAI foundational models for Generative AI applications?", "sessionId": "some-session-id"}' \
| jq .
# response from service
{
"content": "VertexAI Foundational Models are a suite of pre-trained models that can be used to accelerate the development of Generative AI applications. These models are available in a variety of languages and domains, and they can be used to generate text, images, audio, and other types of content.\n\nUsing VertexAI Foundational Models can help you to:\n\n* Reduce the time and effort required to develop Generative AI applications\n* Improve the accuracy and quality of your models\n* Access the latest research and development in Generative AI\n\nVertexAI Foundational Models are a powerful tool for developers who want to create innovative and engaging Generative AI applications.",
…
}
$ > curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<service-address>/query/content \
-d $'{"text":"describe the available LLM models?", "sessionId": "some-session-id"}' \
| jq .
# response from service
{
"content": "The VertexAI Foundational Models suite includes a variety of LLM models, including:\n\n* Text-to-text LLMs: These models can generate text based on a given prompt. They can be used for tasks such as summarization, translation, and question answering.\n* Image-to-text LLMs: These models can generate text based on an image. They can be used for tasks such as image captioning and description generation.\n* Audio-to-text LLMs: These models can generate text based on an audio clip. They can be used for tasks such as speech recognition and transcription.\n\nThese models are available in a variety of languages, including English, Spanish, French, German, and Japanese. They can be used to create a wide range of Generative AI applications, such as chatbots, customer service applications, and creative writing tools.",
…
}
$ > curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<service-address>/query/content \
-d $'{"text":"do rate limit apply for those LLMs?", "sessionId": "some-session-id"}' \
| jq .
# response from service
{
"content": "Yes, there are rate limits for the VertexAI Foundational Models. The rate limits are based on the number of requests per second and the total number of requests per day. For more information, please see the [VertexAI Foundational Models documentation](https://cloud.google.com/vertex-ai/docs/foundational-models#rate-limits).",
…
}
$ > curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<service-address>/query/content \
-d $'{"text":"care to share the price?", "sessionId": "some-session-id"}' \
| jq .
# response from service
{
"content": "The VertexAI Foundational Models are priced based on the number of requests per second and the total number of requests per day. For more information, please see the [VertexAI Foundational Models pricing page](https://cloud.google.com/vertex-ai/pricing#foundational-models).",
…
}
使用技巧: 如果突然改变主题,最好使用新的会话标识符。
部署
作为平台解决方案的一部分,有一组脚本可以帮助部署所有不同的组件。 通过运行 start.sh 并设置正确的参数(GCP 项目、Terraform 状态存储桶和平台实例的名称),脚本将负责构建代码,部署必要的容器(服务端点容器和 Dataflow Python 自定义容器),使用 Terraform 部署所有 GCP 资源,最后部署管道。 还可以通过向启动脚本传递额外的参数来修改管道的执行,例如:start.sh <gcp project> <state-bucket-name> <a run name> "--update" 将更新内容提取管道。
此外,如果只想关注特定组件的部署,已经包含了其他脚本来帮助完成这些特定任务(构建解决方案、部署基础设施、部署管道、部署服务等)。
解决方案说明
此解决方案旨在作为学习示例。 提取管道的许多配置值和安全限制仅作为示例提供。 该解决方案不会传播已摄取内容的现有访问控制列表 (ACL)。 结果,所有具有访问服务端点权限的用户都可以访问从这些原始文档中提取内容摘要的权限。
关于源代码的说明
内容发现平台的源代码可在 Github 上找到。 您可以在任何 Google Cloud 项目中运行它。 该仓库包含集成服务的源代码、多语言摄取管道以及通过 Terraform 进行的部署自动化。 如果您部署此示例,创建和配置所有必需资源可能需要长达 90 分钟。 README 文件包含有关部署先决条件和示例 REST 交互的额外文档。