



博客
2024/06/20
使用 Flink 运行器在 Kubernetes 上部署 Python 管道
使用 Flink 运行器在 Kubernetes 上部署 Python 管道
该 Apache Flink Kubernetes 运算符 充当控制平面,以管理 Apache Flink 应用程序的完整部署生命周期。使用运算符,我们可以简化 Apache Beam 管道的部署和管理。
在这篇文章中,我们使用 Apache Beam 开发一个使用 Python SDK 的管道,并使用 Apache Flink 运行器 在 Apache Flink 集群上部署它。我们首先在 minikube 集群上部署一个 Apache Kafka 集群,因为管道使用 Kafka 主题作为其数据源和接收器。然后,我们将管道开发为一个 Python 包,并将该包添加到自定义 Docker 镜像中,以便可以在外部执行 Python 用户代码。为了部署,我们使用 Flink Kubernetes 运算符创建了一个 Flink 会话集群,并使用 Kubernetes 作业部署了管道。最后,我们使用 Python 生产者应用程序向输入 Kafka 主题发送消息,以检查应用程序的输出。
在 Flink 上运行 Python Beam 管道的资源
我们使用 Python SDK 开发一个 Apache Beam 管道,并使用 Apache Flink 运行器在 Apache Flink 集群上部署它。虽然 Flink 集群是由 Flink Kubernetes 运算符创建的,但我们需要两个组件才能在 Flink 运行器 上运行管道:作业服务 和 SDK 运行程序。简单来说,作业服务将有关 Python 管道的详细信息转换为 Flink 运行器可以理解的格式。SDK 运行程序执行 Python 用户代码。Python SDK 提供了方便的包装器来管理这些组件,你可以通过在管道选项中指定 FlinkRunner 来使用它,例如 --runner=FlinkRunner。作业服务 会自动管理。我们依靠自己的 SDK 运行程序 作为 sidecar 容器,以简化操作。此外,我们还需要 Java IO 扩展服务,因为管道使用 Apache Kafka 主题作为其数据源和接收器,而 Kafka 连接器 I/O 是用 Java 开发的。简而言之,扩展服务用于对 Java SDK 的数据进行序列化。
设置 Kafka 集群
一个 Apache Kafka 集群是使用 Strimzi 运算符 在 minikube 集群上部署的。我们安装了 Strimzi 版本 0.39.0 和 Kubernetes 版本 1.25.3。在安装 minikube CLI 和 Docker 后,你可以通过指定 Kubernetes 版本来创建 minikube 集群。你可以在 GitHub 存储库 中找到这篇博文的源代码。
minikube start --cpus='max' --memory=20480 \
--addons=metrics-server --kubernetes-version=v1.25.3部署 Strimzi 运算符
GitHub 存储库保留了你用来部署 Strimzi 运算符、Kafka 集群和 Kafka 管理应用程序的清单文件。要下载不同版本的运算符,请通过指定版本来下载相关的清单文件。默认情况下,清单文件假设资源是在 myproject 命名空间中部署的。但是,由于我们是在 default 命名空间中部署它们的,因此我们需要更改资源命名空间。我们使用 sed 来更改资源命名空间。
要部署运算符,请使用 kubectl create 命令。
## Download and deploy the Strimzi operator.
STRIMZI_VERSION="0.39.0"
## Optional: If downloading a different version, include this step.
DOWNLOAD_URL=https://github.com/strimzi/strimzi-kafka-operator/releases/download/$STRIMZI_VERSION/strimzi-cluster-operator-$STRIMZI_VERSION.yaml
curl -L -o kafka/manifests/strimzi-cluster-operator-$STRIMZI_VERSION.yaml \
${DOWNLOAD_URL}
# Update the namespace from myproject to default.
sed -i 's/namespace: .*/namespace: default/' kafka/manifests/strimzi-cluster-operator-$STRIMZI_VERSION.yaml
## Deploy the Strimzi cluster operator.
kubectl create -f kafka/manifests/strimzi-cluster-operator-$STRIMZI_VERSION.yaml验证 Strimzi 运算符是否作为 Kubernetes 部署 运行。
kubectl get deploy,rs,po
# NAME READY UP-TO-DATE AVAILABLE AGE
# deployment.apps/strimzi-cluster-operator 1/1 1 1 2m50s
# NAME DESIRED CURRENT READY AGE
# replicaset.apps/strimzi-cluster-operator-8d6d4795c 1 1 1 2m50s
# NAME READY STATUS RESTARTS AGE
# pod/strimzi-cluster-operator-8d6d4795c-94t8c 1/1 Running 0 2m49s部署 Kafka 集群
我们部署了一个包含单个代理和 Zookeeper 节点的 Kafka 集群。它在端口 9092 和 29092 上分别具有内部和外部侦听器。外部侦听器用于从 minikube 集群外部访问 Kafka 集群。此外,集群配置为允许自动创建主题 (auto.create.topics.enable: "true"),默认分区数设置为 3 (num.partitions: 3)。
# kafka/manifests/kafka-cluster.yaml
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: demo-cluster
spec:
kafka:
version: 3.5.2
replicas: 1
resources:
requests:
memory: 256Mi
cpu: 250m
limits:
memory: 512Mi
cpu: 500m
listeners:
- name: plain
port: 9092
type: internal
tls: false
- name: external
port: 29092
type: nodeport
tls: false
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 20Gi
deleteClaim: true
config:
offsets.topic.replication.factor: 1
transaction.state.log.replication.factor: 1
transaction.state.log.min.isr: 1
default.replication.factor: 1
min.insync.replicas: 1
inter.broker.protocol.version: "3.5"
auto.create.topics.enable: "true"
num.partitions: 3
zookeeper:
replicas: 1
resources:
requests:
memory: 256Mi
cpu: 250m
limits:
memory: 512Mi
cpu: 500m
storage:
type: persistent-claim
size: 10Gi
deleteClaim: true
使用 kubectl create 命令部署 Kafka 集群。
kubectl create -f kafka/manifests/kafka-cluster.yamlKafka 和 Zookeeper 节点由 StrimziPodSet 自定义资源管理。它还创建了多个 Kubernetes 服务。在本系列中,我们使用以下服务
- Kubernetes 集群内的通信
demo-cluster-kafka-bootstrap- 用于从客户端和管理应用程序访问 Kafka 代理demo-cluster-zookeeper-client- 用于从管理应用程序访问 Zookeeper 节点
- 来自主机的通信
demo-cluster-kafka-external-bootstrap- 用于从生产者应用程序访问 Kafka 代理
kubectl get po,strimzipodsets.core.strimzi.io,svc -l app.kubernetes.io/instance=demo-cluster
# NAME READY STATUS RESTARTS AGE
# pod/demo-cluster-kafka-0 1/1 Running 0 115s
# pod/demo-cluster-zookeeper-0 1/1 Running 0 2m20s
# NAME PODS READY PODS CURRENT PODS AGE
# strimzipodset.core.strimzi.io/demo-cluster-kafka 1 1 1 115s
# strimzipodset.core.strimzi.io/demo-cluster-zookeeper 1 1 1 2m20s
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# service/demo-cluster-kafka-bootstrap ClusterIP 10.101.175.64 <none> 9091/TCP,9092/TCP 115s
# service/demo-cluster-kafka-brokers ClusterIP None <none> 9090/TCP,9091/TCP,8443/TCP,9092/TCP 115s
# service/demo-cluster-kafka-external-0 NodePort 10.106.155.20 <none> 29092:32475/TCP 115s
# service/demo-cluster-kafka-external-bootstrap NodePort 10.111.244.128 <none> 29092:32674/TCP 115s
# service/demo-cluster-zookeeper-client ClusterIP 10.100.215.29 <none> 2181/TCP 2m20s
# service/demo-cluster-zookeeper-nodes ClusterIP None <none> 2181/TCP,2888/TCP,3888/TCP 2m20s部署 Kafka UI
Apache Kafka 的 UI (kafka-ui) 是一个免费的开源 Kafka 管理应用程序。它作为 Kubernetes 部署部署。部署配置为具有单个实例,并且 Kafka 集群访问详细信息作为环境变量指定。
# kafka/manifests/kafka-ui.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: kafka-ui
name: kafka-ui
spec:
type: ClusterIP
ports:
- port: 8080
targetPort: 8080
selector:
app: kafka-ui
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: kafka-ui
name: kafka-ui
spec:
replicas: 1
selector:
matchLabels:
app: kafka-ui
template:
metadata:
labels:
app: kafka-ui
spec:
containers:
- image: provectuslabs/kafka-ui:v0.7.1
name: kafka-ui-container
ports:
- containerPort: 8080
env:
- name: KAFKA_CLUSTERS_0_NAME
value: demo-cluster
- name: KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS
value: demo-cluster-kafka-bootstrap:9092
- name: KAFKA_CLUSTERS_0_ZOOKEEPER
value: demo-cluster-zookeeper-client:2181
resources:
requests:
memory: 256Mi
cpu: 250m
limits:
memory: 512Mi
cpu: 500m
使用 kubectl create 命令部署 Kafka 管理应用程序 (kafka-ui)。
kubectl create -f kafka/manifests/kafka-ui.yaml
kubectl get all -l app=kafka-ui
# NAME READY STATUS RESTARTS AGE
# pod/kafka-ui-65dbbc98dc-zl5gv 1/1 Running 0 35s
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# service/kafka-ui ClusterIP 10.109.14.33 <none> 8080/TCP 36s
# NAME READY UP-TO-DATE AVAILABLE AGE
# deployment.apps/kafka-ui 1/1 1 1 35s
# NAME DESIRED CURRENT READY AGE
# replicaset.apps/kafka-ui-65dbbc98dc 1 1 1 35s我们使用 kubectl port-forward 连接到在 minikube 集群中端口 8080 上运行的 kafka-ui 服务器。
kubectl port-forward svc/kafka-ui 8080
开发一个流处理应用程序
我们将 Apache Beam 管道开发为一个 Python 包,并将其添加到自定义 Docker 镜像中,该镜像用于执行 Python 用户代码 (SDK 运行程序)。我们还构建了另一个自定义 Docker 镜像,它将 Apache Beam 的 Java SDK 添加到官方 Flink 基础镜像中。此镜像用于部署 Flink 集群和执行 Kafka 连接器 I/O 的 Java 用户代码。
Beam 管道代码
该应用程序首先从输入 Kafka 主题读取文本消息。接下来,它通过拆分消息 (ReadWordsFromKafka) 来提取单词。然后,元素 (单词) 被添加到一个固定的 5 秒时间窗口中,并计算它们的平均长度 (CalculateAvgWordLen)。最后,我们包含窗口的开始和结束时间戳,并将更新后的元素发送到输出 Kafka 主题 (WriteWordLenToKafka)。
我们创建了一个自定义 Java IO 扩展服务 (get_expansion_service),并将其添加到 Kafka 连接器 I/O 的 ReadFromKafka 和 WriteToKafka 变换中。虽然 Kafka I/O 提供了一个创建该服务的函数,但它对我不起作用 (或者我还不明白如何使用它)。相反,我创建了一个自定义服务,如 Jan Lukavský 的《使用 Apache Beam 构建大数据管道》 中所示。扩展服务 Jar 文件 (beam-sdks-java-io-expansion-service.jar) 必须存在于执行管道的 Kubernetes 作业 中,而 Java SDK (/opt/apache/beam/boot) 必须存在于运行器工作程序中。
# beam/word_len/word_len.py
import json
import argparse
import re
import logging
import typing
import apache_beam as beam
from apache_beam import pvalue
from apache_beam.io import kafka
from apache_beam.transforms.window import FixedWindows
from apache_beam.options.pipeline_options import PipelineOptions
from apache_beam.options.pipeline_options import SetupOptions
from apache_beam.transforms.external import JavaJarExpansionService
def get_expansion_service(
jar="/opt/apache/beam/jars/beam-sdks-java-io-expansion-service.jar", args=None
):
if args == None:
args = [
"--defaultEnvironmentType=PROCESS",
'--defaultEnvironmentConfig={"command": "/opt/apache/beam/boot"}',
"--experiments=use_deprecated_read",
]
return JavaJarExpansionService(jar, ["{{PORT}}"] + args)
class WordAccum(typing.NamedTuple):
length: int
count: int
beam.coders.registry.register_coder(WordAccum, beam.coders.RowCoder)
def decode_message(kafka_kv: tuple, verbose: bool = False):
if verbose:
print(kafka_kv)
return kafka_kv[1].decode("utf-8")
def tokenize(element: str):
return re.findall(r"[A-Za-z\']+", element)
def create_message(element: typing.Tuple[str, str, float]):
msg = json.dumps(dict(zip(["window_start", "window_end", "avg_len"], element)))
print(msg)
return "".encode("utf-8"), msg.encode("utf-8")
class AverageFn(beam.CombineFn):
def create_accumulator(self):
return WordAccum(length=0, count=0)
def add_input(self, mutable_accumulator: WordAccum, element: str):
length, count = tuple(mutable_accumulator)
return WordAccum(length=length + len(element), count=count + 1)
def merge_accumulators(self, accumulators: typing.List[WordAccum]):
lengths, counts = zip(*accumulators)
return WordAccum(length=sum(lengths), count=sum(counts))
def extract_output(self, accumulator: WordAccum):
length, count = tuple(accumulator)
return length / count if count else float("NaN")
def get_accumulator_coder(self):
return beam.coders.registry.get_coder(WordAccum)
class AddWindowTS(beam.DoFn):
def process(self, avg_len: float, win_param=beam.DoFn.WindowParam):
yield (
win_param.start.to_rfc3339(),
win_param.end.to_rfc3339(),
avg_len,
)
class ReadWordsFromKafka(beam.PTransform):
def __init__(
self,
bootstrap_servers: str,
topics: typing.List[str],
group_id: str,
verbose: bool = False,
expansion_service: typing.Any = None,
label: str | None = None,
) -> None:
super().__init__(label)
self.boostrap_servers = bootstrap_servers
self.topics = topics
self.group_id = group_id
self.verbose = verbose
self.expansion_service = expansion_service
def expand(self, input: pvalue.PBegin):
return (
input
| "ReadFromKafka"
>> kafka.ReadFromKafka(
consumer_config={
"bootstrap.servers": self.boostrap_servers,
"auto.offset.reset": "latest",
# "enable.auto.commit": "true",
"group.id": self.group_id,
},
topics=self.topics,
timestamp_policy=kafka.ReadFromKafka.create_time_policy,
commit_offset_in_finalize=True,
expansion_service=self.expansion_service,
)
| "DecodeMessage" >> beam.Map(decode_message)
| "Tokenize" >> beam.FlatMap(tokenize)
)
class CalculateAvgWordLen(beam.PTransform):
def expand(self, input: pvalue.PCollection):
return (
input
| "Windowing" >> beam.WindowInto(FixedWindows(size=5))
| "GetAvgWordLength" >> beam.CombineGlobally(AverageFn()).without_defaults()
)
class WriteWordLenToKafka(beam.PTransform):
def __init__(
self,
bootstrap_servers: str,
topic: str,
expansion_service: typing.Any = None,
label: str | None = None,
) -> None:
super().__init__(label)
self.boostrap_servers = bootstrap_servers
self.topic = topic
self.expansion_service = expansion_service
def expand(self, input: pvalue.PCollection):
return (
input
| "AddWindowTS" >> beam.ParDo(AddWindowTS())
| "CreateMessages"
>> beam.Map(create_message).with_output_types(typing.Tuple[bytes, bytes])
| "WriteToKafka"
>> kafka.WriteToKafka(
producer_config={"bootstrap.servers": self.boostrap_servers},
topic=self.topic,
expansion_service=self.expansion_service,
)
)
def run(argv=None, save_main_session=True):
parser = argparse.ArgumentParser(description="Beam pipeline arguments")
parser.add_argument(
"--deploy",
dest="deploy",
action="store_true",
default="Flag to indicate whether to deploy to a cluster",
)
parser.add_argument(
"--bootstrap_servers",
dest="bootstrap",
default="host.docker.internal:29092",
help="Kafka bootstrap server addresses",
)
parser.add_argument(
"--input_topic",
dest="input",
default="input-topic",
help="Kafka input topic name",
)
parser.add_argument(
"--output_topic",
dest="output",
default="output-topic-beam",
help="Kafka output topic name",
)
parser.add_argument(
"--group_id",
dest="group",
default="beam-word-len",
help="Kafka output group ID",
)
known_args, pipeline_args = parser.parse_known_args(argv)
print(known_args)
print(pipeline_args)
# We use the save_main_session option because one or more DoFn elements in this
# workflow rely on global context. That is, a module imported at the module level.
pipeline_options = PipelineOptions(pipeline_args)
pipeline_options.view_as(SetupOptions).save_main_session = save_main_session
expansion_service = None
if known_args.deploy is True:
expansion_service = get_expansion_service()
with beam.Pipeline(options=pipeline_options) as p:
(
p
| "ReadWordsFromKafka"
>> ReadWordsFromKafka(
bootstrap_servers=known_args.bootstrap,
topics=[known_args.input],
group_id=known_args.group,
expansion_service=expansion_service,
)
| "CalculateAvgWordLen" >> CalculateAvgWordLen()
| "WriteWordLenToKafka"
>> WriteWordLenToKafka(
bootstrap_servers=known_args.bootstrap,
topic=known_args.output,
expansion_service=expansion_service,
)
)
logging.getLogger().setLevel(logging.DEBUG)
logging.info("Building pipeline ...")
if __name__ == "__main__":
run()
管道脚本被添加到名为 word_len 的文件夹下的 Python 包中。创建了一个名为 run 的简单模块,因为它是作为模块执行的,例如 python -m ...。当我将管道作为脚本运行时,遇到了错误。这种打包方法仅用于演示。有关打包管道的推荐方法,请参阅 管理 Python 管道依赖项。
# beam/word_len/run.py
from . import *
run()
总的来说,管道包使用以下结构。
tree beam/word_len
beam/word_len
├── __init__.py
├── run.py
└── word_len.py构建 Docker 镜像
如前所述,我们构建了一个自定义 Docker 镜像 (beam-python-example:1.16),并使用它来部署 Flink 集群和运行 Kafka 连接器 I/O 的 Java 用户代码。
# beam/Dockerfile
FROM flink:1.16
COPY --from=apache/beam_java11_sdk:2.56.0 /opt/apache/beam/ /opt/apache/beam/
我们还构建了一个自定义 Docker 镜像 (beam-python-harness:2.56.0) 来运行 Python 用户代码 (SDK 运行程序)。从 Python SDK Docker 镜像开始,它首先安装 Java 开发工具包 (JDK) 并下载 Java IO 扩展服务 Jar 文件。然后,将 Beam 管道包复制到 /app 文件夹中。应用程序文件夹被添加到 PYTHONPATH 环境变量中,这使得这些包可以被搜索到。
# beam/Dockerfile-python-harness
FROM apache/beam_python3.10_sdk:2.56.0
ARG BEAM_VERSION
ENV BEAM_VERSION=${BEAM_VERSION:-2.56.0}
ENV REPO_BASE_URL=https://repo1.maven.org/maven2/org/apache/beam
RUN apt-get update && apt-get install -y default-jdk
RUN mkdir -p /opt/apache/beam/jars \
&& wget ${REPO_BASE_URL}/beam-sdks-java-io-expansion-service/${BEAM_VERSION}/beam-sdks-java-io-expansion-service-${BEAM_VERSION}.jar \
--progress=bar:force:noscroll -O /opt/apache/beam/jars/beam-sdks-java-io-expansion-service.jar
COPY word_len /app/word_len
COPY word_count /app/word_count
ENV PYTHONPATH="$PYTHONPATH:/app"
由于自定义镜像需要在 minikube 集群中可以访问,因此我们将终端的 docker-cli 指向 minikube 的 Docker 引擎。然后,我们可以使用 docker build 命令构建镜像。
eval $(minikube docker-env)
docker build -t beam-python-example:1.16 beam/
docker build -t beam-python-harness:2.56.0 -f beam/Dockerfile-python-harness beam/部署流处理应用程序
Beam 管道是在 Flink 会话集群 上执行的,该集群由 Flink Kubernetes 运算符部署。将 Beam 管道作为 Flink 作业部署的 应用程序部署模式 似乎不起作用 (或者我还不明白如何这样做),原因可能是作业提交超时错误或无法上传作业工件。在部署管道后,我们通过向输入 Kafka 主题发送文本消息来检查应用程序的输出。
部署 Flink Kubernetes 运算符
首先,为了能够添加 webhook 组件,请在 minikube 集群上安装 证书管理器。然后,使用 Helm 图表来安装运算符。文章中安装了 1.8.0 版本。
kubectl create -f https://github.com/jetstack/cert-manager/releases/download/v1.8.2/cert-manager.yaml
helm repo add flink-operator-repo https://downloads.apache.org/flink/flink-kubernetes-operator-1.8.0/
helm install flink-kubernetes-operator flink-operator-repo/flink-kubernetes-operator
# NAME: flink-kubernetes-operator
# LAST DEPLOYED: Mon Jun 03 21:37:45 2024
# NAMESPACE: default
# STATUS: deployed
# REVISION: 1
# TEST SUITE: None
helm list
# NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
# flink-kubernetes-operator default 1 2024-06-03 21:37:45.579302452 +1000 AEST deployed flink-kubernetes-operator-1.8.0 1.8.0部署 Beam 管道
首先,创建一个 Flink 会话集群。在清单文件中,配置通用属性,例如 Docker 镜像、Flink 版本、集群配置和 pod 模板。这些属性被应用于 Flink 作业管理器和任务管理器。此外,请指定副本和资源。我们向任务管理器添加了一个 sidecar 容器,并且此 SDK 运行程序 容器配置为执行 Python 用户代码 - 请参阅以下作业配置。
# beam/word_len_cluster.yml
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
name: word-len-cluster
spec:
image: beam-python-example:1.16
imagePullPolicy: Never
flinkVersion: v1_16
flinkConfiguration:
taskmanager.numberOfTaskSlots: "10"
serviceAccount: flink
podTemplate:
spec:
containers:
- name: flink-main-container
volumeMounts:
- mountPath: /opt/flink/log
name: flink-logs
volumes:
- name: flink-logs
emptyDir: {}
jobManager:
resource:
memory: "2048Mi"
cpu: 2
taskManager:
replicas: 1
resource:
memory: "2048Mi"
cpu: 2
podTemplate:
spec:
containers:
- name: python-harness
image: beam-python-harness:2.56.0
args: ["-worker_pool"]
ports:
- containerPort: 50000
name: harness-port
管道使用 Kubernetes 作业部署,并且自定义 SDK 运行程序 镜像被用于作为模块执行管道。前两个参数是特定于应用程序的。其余的参数是用于管道选项的。有关管道参数的更多信息,请参阅 管道选项源代码 和 Flink 运行器文档。为了在 sidecar 容器中执行 Python 用户代码,我们将环境类型设置为 EXTERNAL,并将环境配置设置为 localhost:50000。
# beam/word_len_job.yml
apiVersion: batch/v1
kind: Job
metadata:
name: word-len-job
spec:
template:
metadata:
labels:
app: word-len-job
spec:
containers:
- name: beam-word-len-job
image: beam-python-harness:2.56.0
command: ["python"]
args:
- "-m"
- "word_len.run"
- "--deploy"
- "--bootstrap_servers=demo-cluster-kafka-bootstrap:9092"
- "--runner=FlinkRunner"
- "--flink_master=word-len-cluster-rest:8081"
- "--job_name=beam-word-len"
- "--streaming"
- "--parallelism=3"
- "--flink_submit_uber_jar"
- "--environment_type=EXTERNAL"
- "--environment_config=localhost:50000"
- "--checkpointing_interval=10000"
restartPolicy: Never
使用 kubectl create 命令部署会话集群和作业。会话集群由 FlinkDeployment 自定义资源创建,它管理作业管理器部署、任务管理器 Pod 和相关服务。当我们检查作业 Pod 的日志时,我们会看到它执行以下任务
- 下载 Jar 文件后启动 Job Service
- 上传管道工件
- 将管道提交为 Flink 作业
- 持续监控作业状态
kubectl create -f beam/word_len_cluster.yml
# flinkdeployment.flink.apache.org/word-len-cluster created
kubectl create -f beam/word_len_job.yml
# job.batch/word-len-job created
kubectl logs word-len-job-p5rph -f
# WARNING:apache_beam.options.pipeline_options:Unknown pipeline options received: --checkpointing_interval=10000. Ignore if flags are used for internal purposes.
# WARNING:apache_beam.options.pipeline_options:Unknown pipeline options received: --checkpointing_interval=10000. Ignore if flags are used for internal purposes.
# INFO:root:Building pipeline ...
# INFO:apache_beam.runners.portability.flink_runner:Adding HTTP protocol scheme to flink_master parameter: http://word-len-cluster-rest:8081
# WARNING:apache_beam.options.pipeline_options:Unknown pipeline options received: --checkpointing_interval=10000. Ignore if flags are used for internal purposes.
# DEBUG:apache_beam.runners.portability.abstract_job_service:Got Prepare request.
# DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): word-len-cluster-rest:8081
# DEBUG:urllib3.connectionpool:http://word-len-cluster-rest:8081 "GET /v1/config HTTP/1.1" 200 240
# INFO:apache_beam.utils.subprocess_server:Downloading job server jar from https://repo.maven.apache.org/maven2/org/apache/beam/beam-runners-flink-1.16-job-server/2.56.0/beam-runners-flink-1.16-job-server-2.56.0.jar
# INFO:apache_beam.runners.portability.abstract_job_service:Artifact server started on port 43287
# DEBUG:apache_beam.runners.portability.abstract_job_service:Prepared job 'job' as 'job-edc1c2f1-80ef-48b7-af14-7e6fc86f338a'
# INFO:apache_beam.runners.portability.abstract_job_service:Running job 'job-edc1c2f1-80ef-48b7-af14-7e6fc86f338a'
# DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): word-len-cluster-rest:8081
# DEBUG:urllib3.connectionpool:http://word-len-cluster-rest:8081 "POST /v1/jars/upload HTTP/1.1" 200 148
# DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): word-len-cluster-rest:8081
# DEBUG:urllib3.connectionpool:http://word-len-cluster-rest:8081 "POST /v1/jars/e1984c45-d8bc-4aa1-9b66-369a23826921_beam.jar/run HTTP/1.1" 200 44
# INFO:apache_beam.runners.portability.flink_uber_jar_job_server:Started Flink job as a403cb2f92fecee65b8fd7cc8ac6e68a
# INFO:apache_beam.runners.portability.portable_runner:Job state changed to STOPPED
# DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): word-len-cluster-rest:8081
# DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): word-len-cluster-rest:8081
# DEBUG:urllib3.connectionpool:http://word-len-cluster-rest:8081 "GET /v1/jobs/a403cb2f92fecee65b8fd7cc8ac6e68a/execution-result HTTP/1.1" 200 31
# DEBUG:urllib3.connectionpool:http://word-len-cluster-rest:8081 "GET /v1/jobs/a403cb2f92fecee65b8fd7cc8ac6e68a/execution-result HTTP/1.1" 200 31
# INFO:apache_beam.runners.portability.portable_runner:Job state changed to RUNNING
# DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): word-len-cluster-rest:8081
# DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): word-len-cluster-rest:8081
# DEBUG:urllib3.connectionpool:http://word-len-cluster-rest:8081 "GET /v1/jobs/a403cb2f92fecee65b8fd7cc8ac6e68a/execution-result HTTP/1.1" 200 31
# DEBUG:urllib3.connectionpool:http://word-len-cluster-rest:8081 "GET /v1/jobs/a403cb2f92fecee65b8fd7cc8ac6e68a/execution-result HTTP/1.1" 200 31
# ...部署完成后,我们可以看到以下 Flink 会话集群和作业相关资源。
kubectl get all -l app=word-len-cluster
# NAME READY STATUS RESTARTS AGE
# pod/word-len-cluster-7c98f6f868-d4hbx 1/1 Running 0 5m32s
# pod/word-len-cluster-taskmanager-1-1 2/2 Running 0 4m3s
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# service/word-len-cluster ClusterIP None <none> 6123/TCP,6124/TCP 5m32s
# service/word-len-cluster-rest ClusterIP 10.104.23.28 <none> 8081/TCP 5m32s
# NAME READY UP-TO-DATE AVAILABLE AGE
# deployment.apps/word-len-cluster 1/1 1 1 5m32s
# NAME DESIRED CURRENT READY AGE
# replicaset.apps/word-len-cluster-7c98f6f868 1 1 1 5m32s
kubectl get all -l app=word-len-job
# NAME READY STATUS RESTARTS AGE
# pod/word-len-job-24r6q 1/1 Running 0 5m24s
# NAME COMPLETIONS DURATION AGE
# job.batch/word-len-job 0/1 5m24s 5m24s您可以使用 kubectl port-forward 命令在端口 8081 上访问 Flink Web UI。作业图显示了两个任务。第一个任务将单词元素添加到固定时间窗口中。第二个任务将平均词长记录发送到输出主题。
kubectl port-forward svc/flink-word-len-rest 8081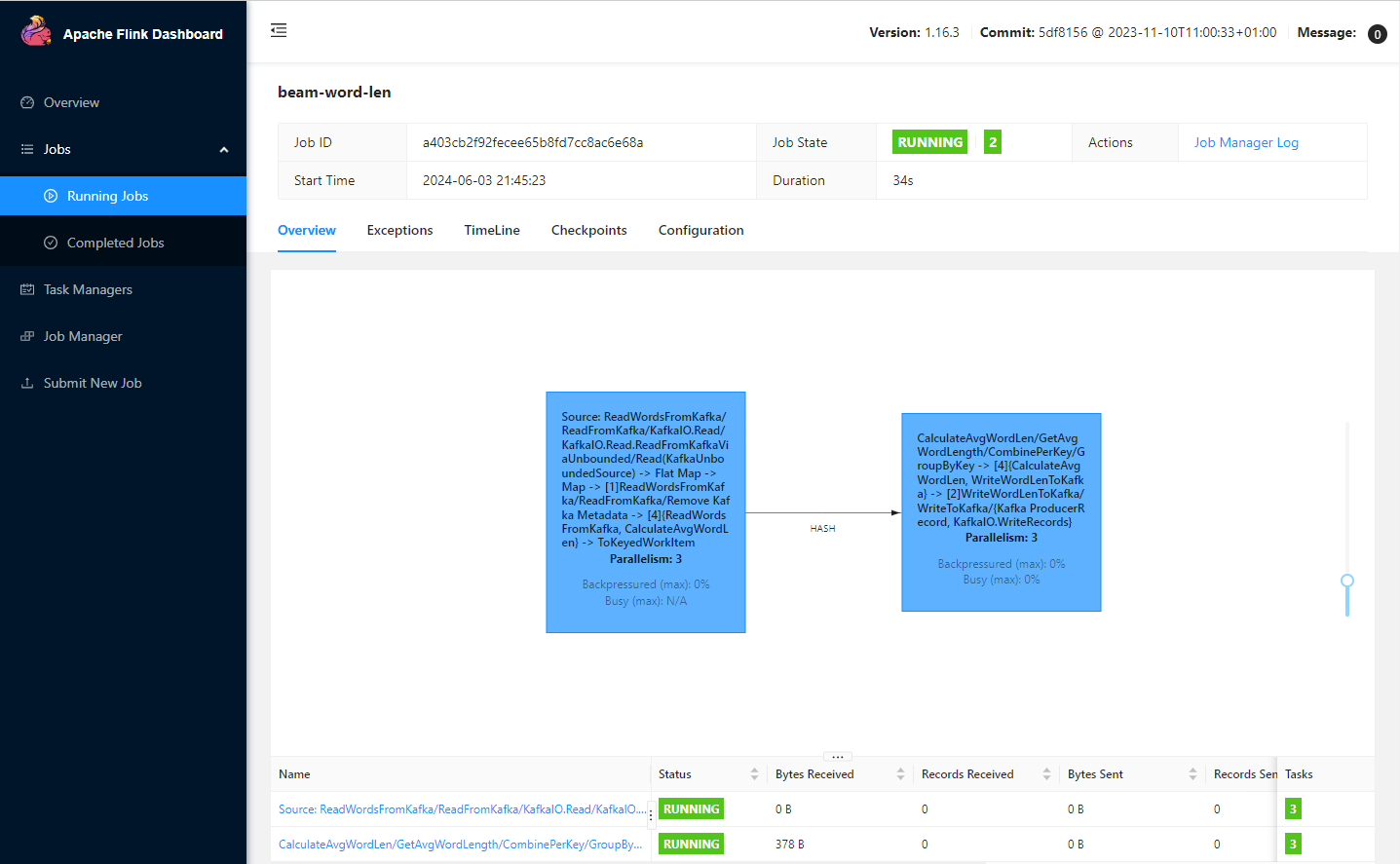
Kafka I/O 在不存在的情况下会自动创建一个主题,我们可以在 kafka-ui 上看到输入主题已创建。
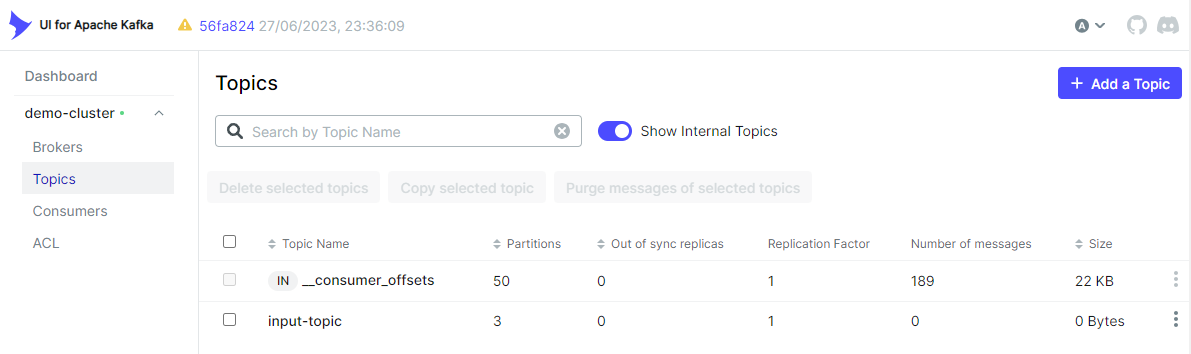
Kafka 生产者
创建一个简单的 Python Kafka 生产者来检查应用程序的输出。默认情况下,生产者应用程序每秒从 Faker 包发送随机文本到输入 Kafka 主题。
# kafka/client/producer.py
import os
import time
from faker import Faker
from kafka import KafkaProducer
class TextProducer:
def __init__(self, bootstrap_servers: list, topic_name: str) -> None:
self.bootstrap_servers = bootstrap_servers
self.topic_name = topic_name
self.kafka_producer = self.create_producer()
def create_producer(self):
"""
Returns a KafkaProducer instance
"""
return KafkaProducer(
bootstrap_servers=self.bootstrap_servers,
value_serializer=lambda v: v.encode("utf-8"),
)
def send_to_kafka(self, text: str, timestamp_ms: int = None):
"""
Sends text to a Kafka topic.
"""
try:
args = {"topic": self.topic_name, "value": text}
if timestamp_ms is not None:
args = {**args, **{"timestamp_ms": timestamp_ms}}
self.kafka_producer.send(**args)
self.kafka_producer.flush()
except Exception as e:
raise RuntimeError("fails to send a message") from e
if __name__ == "__main__":
producer = TextProducer(
os.getenv("BOOTSTRAP_SERVERS", "localhost:29092"),
os.getenv("TOPIC_NAME", "input-topic"),
)
fake = Faker()
num_events = 0
while True:
num_events += 1
text = fake.text()
producer.send_to_kafka(text)
if num_events % 5 == 0:
print(f"<<<<<{num_events} text sent... current>>>>\n{text}")
time.sleep(int(os.getenv("DELAY_SECONDS", "1")))
使用 kubectl port-forward 命令在端口 29092 上公开 Kafka bootstrap 服务器。执行 Python 脚本启动生产者应用程序。
kubectl port-forward svc/demo-cluster-kafka-external-bootstrap 29092
python kafka/client/producer.py我们可以看到输出主题 (output-topic-beam) 已在 kafka-ui 上创建。
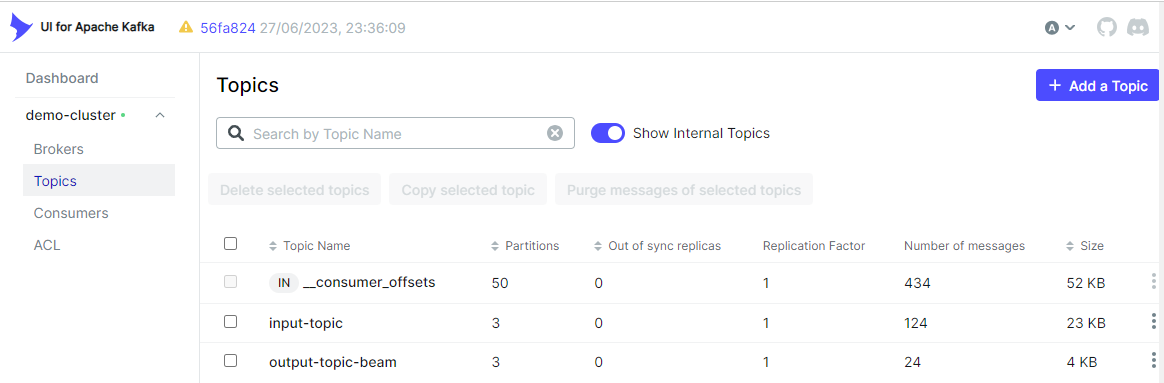
此外,我们可以在 主题 选项卡中检查输出消息是否按预期创建。
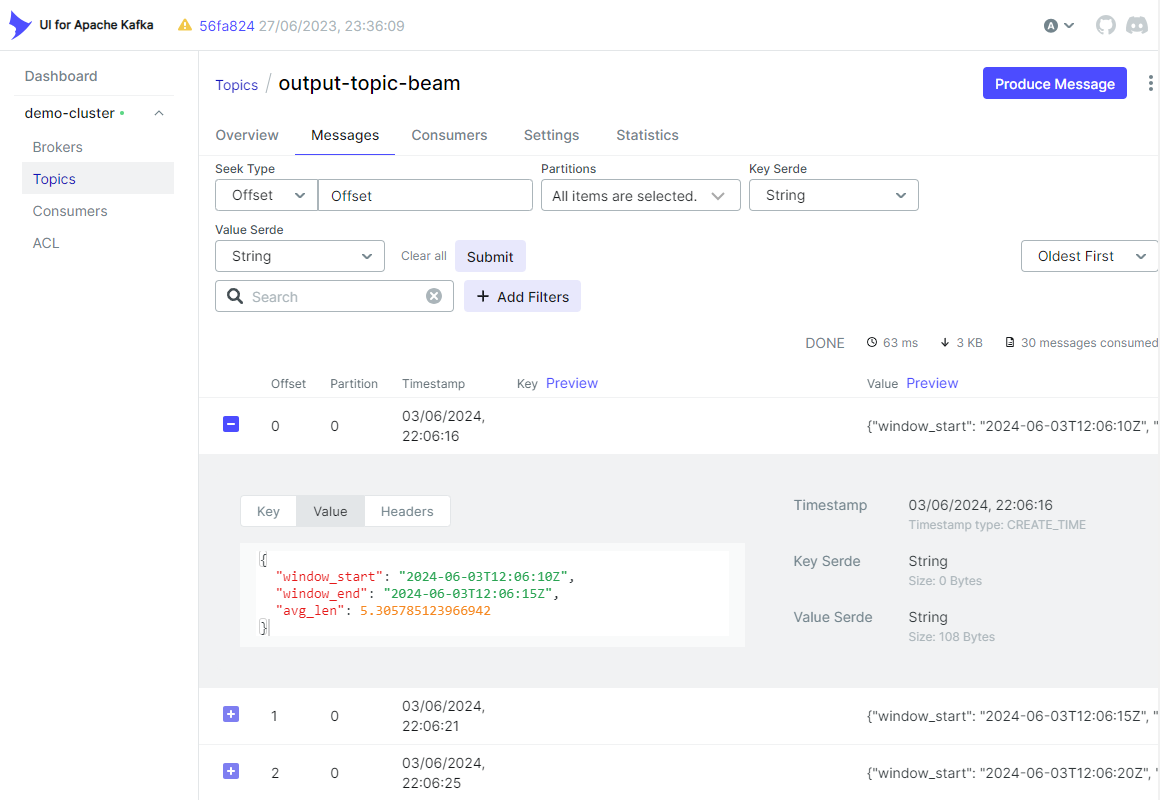
删除资源
使用以下步骤删除 Kubernetes 资源和 minikube 集群。
## Delete the Flink Operator and related resources.
kubectl delete -f beam/word_len_cluster.yml
kubectl delete -f beam/word_len_job.yml
helm uninstall flink-kubernetes-operator
helm repo remove flink-operator-repo
kubectl delete -f https://github.com/jetstack/cert-manager/releases/download/v1.8.2/cert-manager.yaml
## Delete the Kafka cluster and related resources.
STRIMZI_VERSION="0.39.0"
kubectl delete -f kafka/manifests/kafka-cluster.yaml
kubectl delete -f kafka/manifests/kafka-ui.yaml
kubectl delete -f kafka/manifests/strimzi-cluster-operator-$STRIMZI_VERSION.yaml
## Delete the minikube.
minikube delete