



博客
2022/04/28
在笔记本中运行 Beam SQL
简介
Beam SQL 允许 Beam 用户使用 SQL 语句查询 PCollection。 交互式 Beam 在 Apache Beam 和 Jupyter 笔记本(以前称为 IPython 笔记本)之间提供集成,以使管道原型设计和数据探索更加快速和容易。您可以按照其文档在自己的设备上设置自己的笔记本用户界面(例如,JupyterLab 或经典的 Jupyter 笔记本)。或者,您可以选择一个为您完成所有操作的托管解决方案。您可以自由选择您喜欢的任何笔记本用户界面。为简单起见,本文不会介绍笔记本环境的设置,并使用 Apache Beam 笔记本,它提供了一个云托管的 JupyterLab 环境,并允许 Beam 用户在读-评估-打印-循环 (REPL) 工作流程中迭代地开发管道、检查管道图并解析单个 PCollection。
在本文中,您将看到如何使用 beam_sql(一个笔记本 魔法)在笔记本中执行 Beam SQL 并检查结果。
在本文结束时,它还将演示如何将 beam_sql 魔法与生产环境一起使用,例如将其作为 Dataflow 上的一次性作业运行。这是可选的。要遵循这些步骤,您应该在 Google Cloud Platform 中有一个项目,其中启用了 必要的 API,并且您应该有足够的权限来创建一个 Google Cloud Storage 存储桶(或使用现有的存储桶)、查询一个公共 Google Cloud BigQuery 数据集并运行 Dataflow 作业。
如果您选择使用云托管的笔记本解决方案,一旦您的 Google Cloud 项目准备就绪,您将需要创建一个 Apache Beam 笔记本实例并打开 JupyterLab 网页界面。请按照以下链接提供的说明操作:https://cloud.google.com/dataflow/docs/guides/interactive-pipeline-development#launching_an_notebooks_instance
熟悉环境
登录页面
启动您自己的笔记本用户界面后:例如,如果您使用的是 Apache Beam 笔记本,单击 OPEN JUPYTERLAB 链接后,您将进入笔记本环境的默认启动器页面。
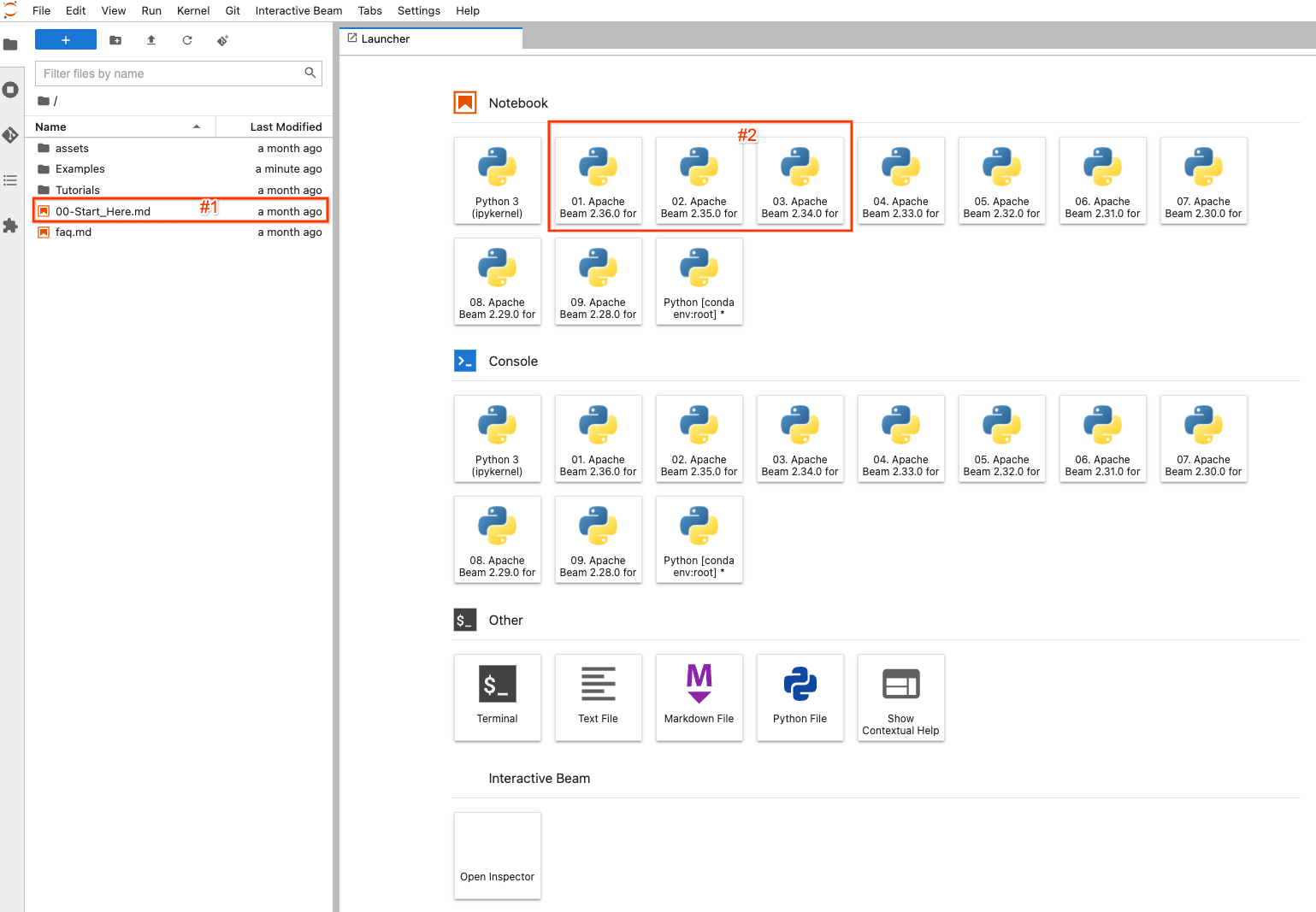
在左侧,有一个文件资源管理器用于查看笔记本实例上的示例、教程和资产。要轻松浏览文件,您可以双击 00-Start_Here.md(屏幕截图中的#1)文件以查看有关文件的详细信息。
在右侧,它显示了 JupyterLab 的默认启动器页面。要创建和打开一个全新的笔记本文件并使用选定的 Apache Beam 版本进行编码,请单击带有 Apache Beam >=2.34.0(因为 beam_sql 在 2.34.0 中引入)安装的项目之一(#2)。
创建/打开笔记本
例如,如果您单击带有 Apache Beam 2.36.0 的图像按钮,您将看到一个 Untitled.ipynb 文件被创建并打开。
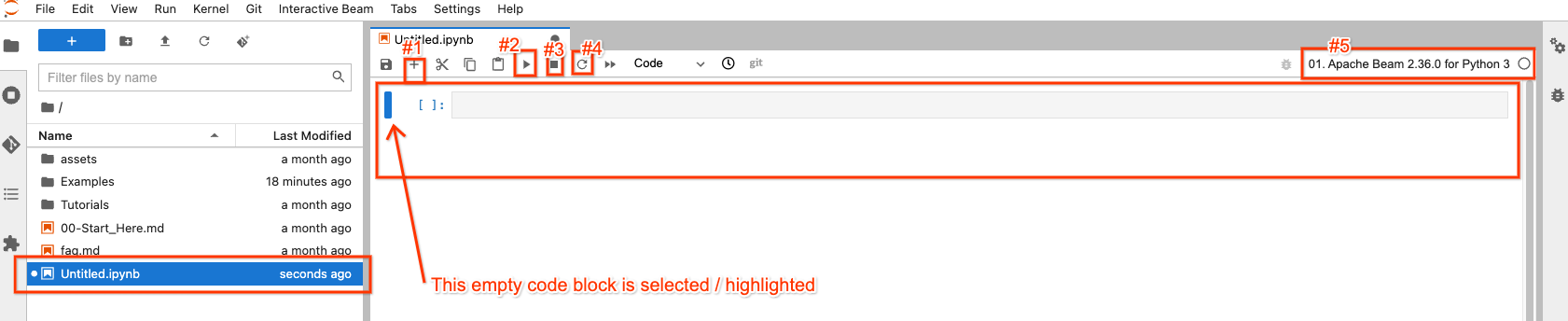
在文件资源管理器中,您的新笔记本文件已创建为 Untitled.ipynb。
在右侧,在打开的笔记本中,顶部有 4 个按钮,您可能会最常与它们交互
- #1:在选定/突出显示的代码块之后插入一个空的代码块
- #2:执行选定/突出显示的块中的代码
- #3:如果您的代码执行卡住,则中断代码执行
- #4:“重启内核”:清除来自代码执行的所有状态并从头开始
右上角有一个按钮(#5),供您根据需要选择不同的 Apache Beam 版本,因此它不是一成不变的。
您始终可以从文件资源管理器中双击文件以打开它,而无需创建新的文件。
Beam SQL
beam_sql 魔法
beam_sql 是一个 IPython 自定义魔法。如果您不熟悉魔法,这里有一些 内置示例。它是在使用 SQL 对 Beam 管道进行原型设计时,在将管道在远程集群/服务上进行生产化之前,使用它来验证您的查询在已知/测试数据源上的本地有效性的便捷方式。
Apache Beam 笔记本环境已预加载 beam_sql 魔法和基本的 apache-beam 模块,因此您可以直接使用它们而无需额外导入。如果您在其他地方设置了自己的笔记本,也可以通过 %load_ext apache_beam.runners.interactive.sql.beam_sql_magics 和 apache-beam 模块显式加载魔法。
您可以键入
%beam_sql -h
然后执行代码以了解如何使用魔法
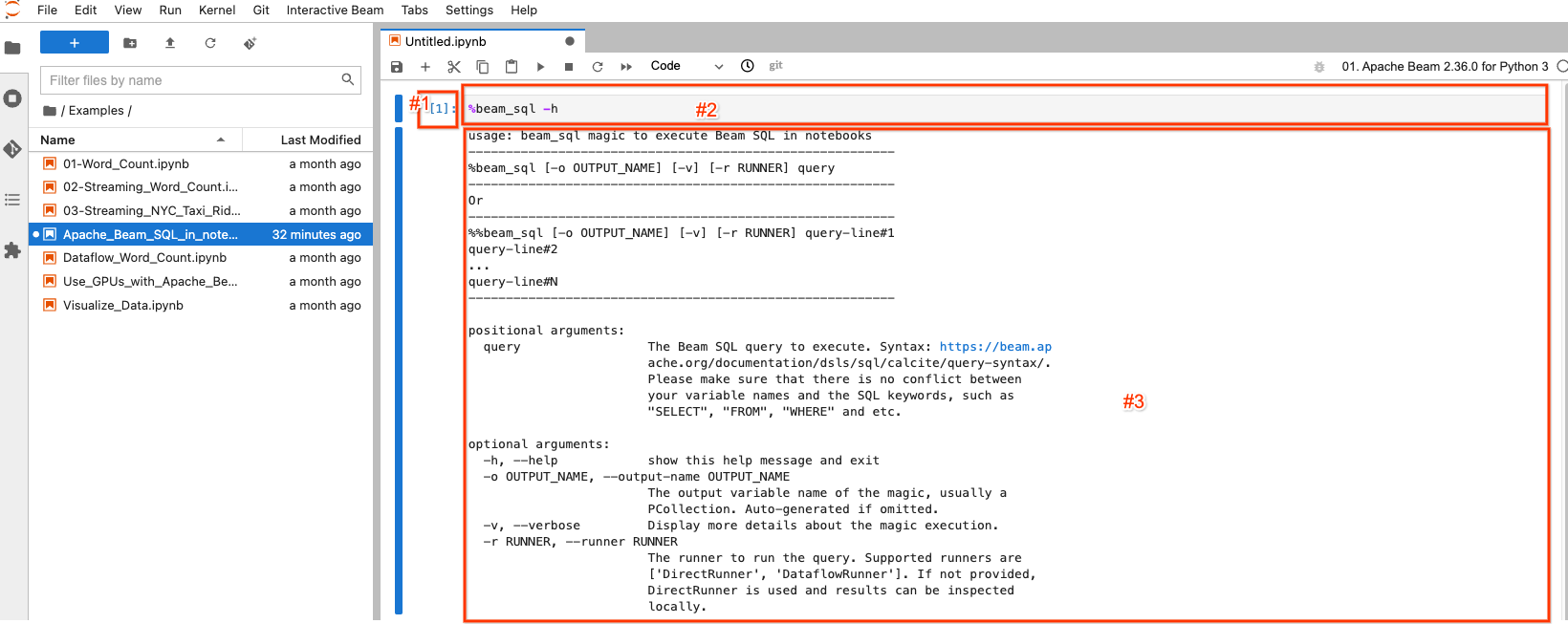
选定/突出显示的块称为笔记本单元格。它主要有 3 个组成部分
- #1:执行计数。
[1]表示此块是第一个执行的代码。对于您执行的每一块代码,它都会增加 1,即使您重新执行相同的代码块也是如此。[ ]表示此块未执行。 - #2:单元格输入:执行代码。
- #3:单元格输出:代码执行的输出。这里它包含
beam_sql魔法的帮助文档。
创建 PCollection
使用 Beam SQL 创建 PCollection 时有 3 种情况
- 使用 Beam SQL 从常量值创建 PCollection
%%beam_sql -o pcoll
SELECT CAST(1 AS INT) AS id, CAST('foo' AS VARCHAR) AS str, CAST(3.14 AS DOUBLE) AS flt

beam_sql 魔法创建一个名为 pcoll 的 PCollection,并输出它,元素类型类似于 BeamSchema_...(id: int32, str: str, flt: float64)。
注意,您没有显式创建 Beam 管道。您获得一个 PCollection 是因为 beam_sql 魔法始终隐式创建一个管道来执行您的 SQL 查询。为了保存具有每个字段类型信息的元素,Beam 会自动创建一个 模式 作为创建的 PCollection 的 element_type。您将在后面了解有关模式感知 PCollection 的更多信息。
- 使用 Beam SQL 查询 PCollection
您可以将另一个 SQL 与来自先前 SQL(或由任何正常的 Beam PTransforms 生成的任何模式感知 PCollection)的输出链接起来,以生成一个新的 PCollection。
注意:如果您命名输出 PCollection,请确保它在笔记本中是唯一的,以避免覆盖不同的 PCollection。
%%beam_sql -o id_pcoll
SELECT id FROM pcoll

- 使用 Beam SQL 连接多个 PCollection
您可以从单个查询中查询多个 PCollection。
%%beam_sql -o str_with_same_id
SELECT id, str FROM pcoll JOIN id_pcoll USING (id)

现在您已了解如何使用 beam_sql 魔法来创建 PCollection 并检查其结果。
提示:如果您不小心删除了笔记本单元格的某些输出,您可以始终通过调用 ib.show(pcoll_name) 或 ib.collect(pcoll_name) 来检查 PCollection 的内容,其中 ib 代表“交互式 Beam”(了解更多)。
模式感知 PCollection
beam_sql 魔法提供了灵活性,可以无缝地混合 SQL 和非 SQL Beam 语句来构建管道,甚至在 Dataflow 上运行它们。但是,每个由 Beam SQL 查询的 PCollection 都需要具有 模式。对于 beam_sql 魔法,当需要模式时,建议使用 typing.NamedTuple。您可以查看以下示例以了解有关模式感知 PCollection 的更多详细信息。
设置
在本例的设置中,您将
- 使用内置的
%pip魔法安装 PyPI 包names:您将使用该模块生成一些随机的英文姓名作为原始数据输入。 - 使用
NamedTuple定义一个模式,它有两个属性:id- 人的唯一数字标识符;name- 人的字符串姓名。 - 使用
InteractiveRunner定义一个管道,以利用 Apache Beam 的笔记本相关功能。
%pip install names
import names
from typing import NamedTuple
class Person(NamedTuple):
id: int
name: str
p = beam.Pipeline(InteractiveRunner())
代码执行没有可见的输出。
在不使用 SQL 的情况下创建模式感知 PCollection
persons = (p
| beam.Create([Person(id=x, name=names.get_full_name()) for x in range(10)]))
ib.show(persons)

persons_2 = (p
| beam.Create([Person(id=x, name=names.get_full_name()) for x in range(5, 15)]))
ib.show(persons_2)

现在您有两个 PCollection,它们都具有由 Person 类定义的相同模式
persons包含 10 个人的 10 条记录,id 范围从 0 到 9,persons_2包含另外 10 个人的 10 条记录,id 范围从 5 到 14。
模式感知 PCollection 的编码和解码
对于本例,您还需要来自第一个 pcoll 的另一个数据块,您已使用本文中的说明创建了它。
您可以使用原始的 pcoll。可选地,如果您想明确地使用编码器来练习使用模式感知 PCollection,您可以添加一个文本 I/O:将 pcoll 的内容写入文本文件,保留其模式信息,然后将该文件读回一个名为 pcoll_in_file 的新的模式感知 PCollection 中,并使用新的 PCollection 来连接 persons 和 persons_2 以查找所有三个中具有公共 id 的姓名。
要将 pcoll 编码到文件中,请执行
coder=beam.coders.registry.get_coder(pcoll.element_type)
pcoll | beam.io.textio.WriteToText('/tmp/pcoll', coder=coder)
pcoll.pipeline.run().wait_until_finish()
!cat /tmp/pcoll*

上面的代码执行使用 Beam 分配的编码器将 PCollection pcoll(基本上是 {id: 1, str: foo, flt: 3.14})写入文本文件。如您所见,文件内容以二进制非人类可读格式记录,这是正常的。
要将文件内容解码为新的 PCollection,请执行
pcoll_in_file = p | beam.io.ReadFromText(
'/tmp/pcoll*', coder=coder).with_output_types(
pcoll.element_type)
ib.show(pcoll_in_file)

注意,您必须在编码和解码期间使用相同的编码器,此外,您还可以通过 with_output_types() 将模式显式分配给新的 PCollection。
从文本文件中读取编码的二进制内容并使用正确的编码器对其进行解码,pcoll 的内容将恢复到 pcoll_in_file 中。您可以使用此技术通过任何 Beam I/O(不一定是文本文件)与在自己的管道上工作(不仅仅是在您的笔记本会话或管道中)的合作者保存和共享您的数据。
beam_sql 魔法中的模式
beam_sql 魔法会自动为您的 NamedTuple 模式注册一个 RowCoder,这样您只需专注于准备查询数据,而无需担心编码器。 要查看 beam_sql 魔法在幕后所做工作的更详细说明,您可以使用 -v 选项。
例如,您可以使用以下查询查找 persons 中所有 id < 5 的元素,并将输出分配给 persons_id_lt_5。
%%beam_sql -o persons_id_lt_5 -v
SELECT * FROM persons WHERE id < 5
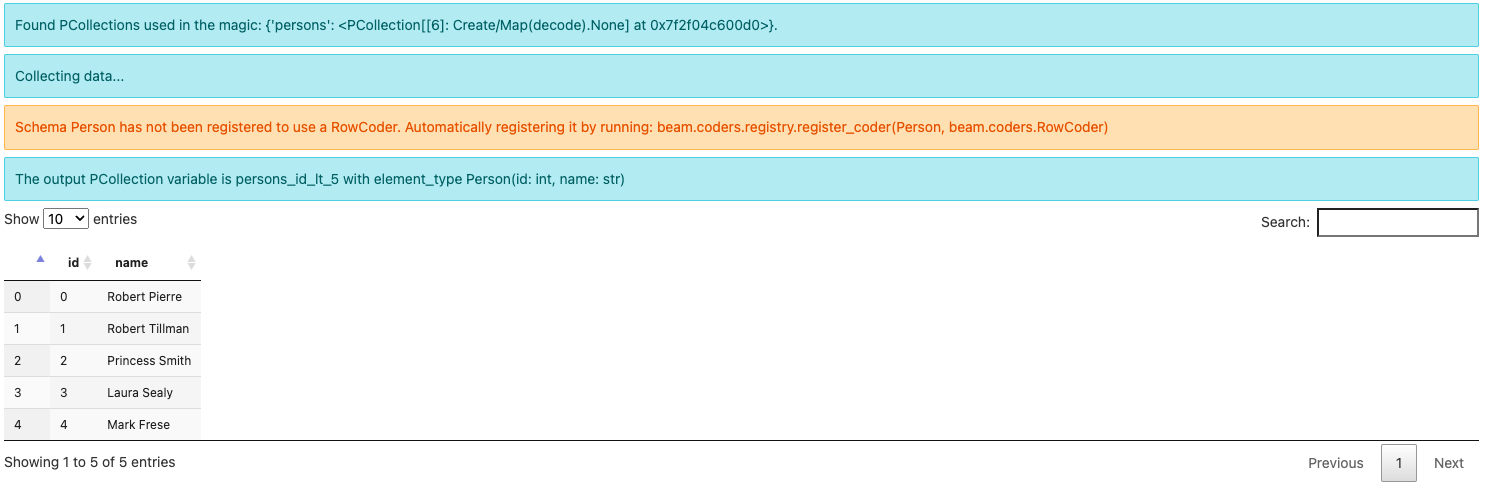
由于这是您第一次运行此查询,您可能会看到一条关于
模式 Person 尚未注册以使用 RowCoder。正在通过运行以下命令自动注册它:beam.coders.registry.register_coder(Person, beam.coders.RowCoder)
beam_sql 魔法有助于为每个定义并使用的模式注册一个 RowCoder,无论何时找到一个模式。 您也可以显式运行相同的代码来执行此操作。
注意 输出元素类型是 Person(id: int, name: str) 而不是 BeamSchema_…,因为您从已知类型 Person(id: int, name: str) 的单个 PCollection 中选择了所有字段。
另一个示例,您可以查询 persons 和 persons_2 中所有具有相同 ID 的名称,并将输出分配给 persons_with_common_id
%%beam_sql -o persons_with_common_id -v
SELECT * FROM persons JOIN persons_2 USING (id)
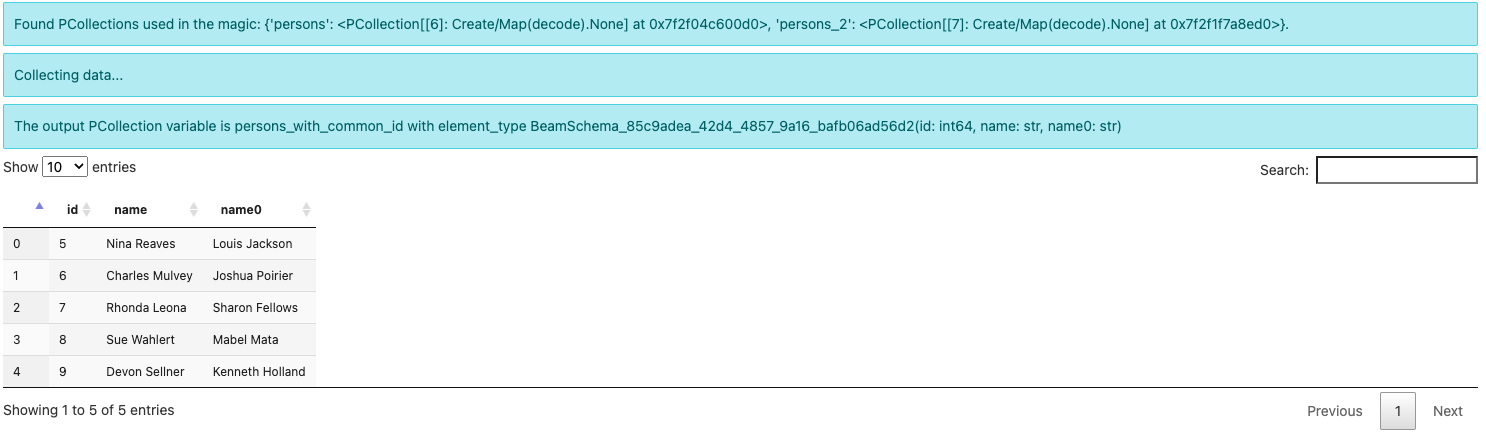
注意输出元素类型现在是 BeamSchema_...(id: int64, name: str, name0: str)。 因为您从两个 PCollection 中选择了列,所以没有已知的模式来保存结果。 Beam 会自动创建一个模式,并通过在其中一个冲突字段 name 后添加 0 来区分它。
而且,由于 Person 以前已经用 RowCoder 注册过了,即使使用 -v 选项,也不会再有关于注册它的警告。
此外,您可以使用 pcoll_in_file、persons 和 persons_2 执行连接
%%beam_sql -o entry_with_common_id
SELECT pcoll_in_file.id, persons.name AS name_1, persons_2.name AS name_2
FROM pcoll_in_file JOIN persons ON pcoll_in_file.id = persons.id
JOIN persons_2 ON pcoll_in_file.id = persons_2.id

生成的模式反映了您在 SQL 中进行的列重命名。
示例
您将通过一个示例来找出在特定日期拥有最多 COVID 阳性病例的美国州,数据由 covid 跟踪项目 提供。
获取数据
import json
import requests
# The covidtracking project has stopped collecting new data, current data ends on 2021-03-07
json_current='https://api.covidtracking.com/v1/states/current.json'
def get_json_data(url):
with requests.Session() as session:
data = json.loads(session.get(url).text)
return data
current_data = get_json_data(json_current)
current_data[0]

数据日期为 2021-03-07。它包含有关美国不同州 COVID 病例的许多详细信息。current_data[0] 只是一个数据点。
您可以摆脱数据中的大多数列。 例如,只关注“date”、“state”、“positive”和“negative”,然后定义一个模式 UsCovidData
from typing import Optional
class UsCovidData(NamedTuple):
partition_date: str # Remember to str(e['date']).
state: str
positive: int
negative: Optional[int]
注意:
date是 (Calcite)SQL 中的关键字,请使用不同的字段名称,例如partition_date;- 数据中的
date是int类型,而不是str。 请确保您使用str()转换数据或使用date: int。 negative具有缺失值,默认值为None。 因此,它应该使用negative: Optional[int]而不是negative: int。 或者,您可以在使用模式时将None转换为 0。
然后将 JSON 数据解析为具有该模式的 PCollection
p_sql = beam.Pipeline(runner=InteractiveRunner())
covid_data = (p_sql
| 'Create PCollection from json' >> beam.Create(current_data)
| 'Parse' >> beam.Map(
lambda e: UsCovidData(
partition_date=str(e['date']),
state=e['state'],
positive=e['positive'],
negative=e['negative'])).with_output_types(UsCovidData))
ib.show(covid_data)

查询
您现在可以找到“当前日期”(2021-03-07)的最大阳性值。
%%beam_sql -o max_positive
SELECT partition_date, MAX(positive) AS positive
FROM covid_data
GROUP BY partition_date

但是,这只是阳性数字。 您无法观察到具有此最大值的州,也无法观察到该州的阴性病例数量。
要丰富您的结果,您必须将此数据重新加入您已解析的原始数据集中。
%%beam_sql -o entry_with_max_positive
SELECT covid_data.partition_date, covid_data.state, covid_data.positive, {fn IFNULL(covid_data.negative, 0)} AS negative
FROM covid_data JOIN max_positive
USING (partition_date, positive)

现在,您可以看到具有 2021-03-07 最大阳性病例的所有数据列。注意:为了处理原始数据中阴性列的缺失值,您可以使用 {fn IFNULL(covid_data.negative, 0)} 将空值设置为 0。
准备好扩展时,您可以使用 SqlTransform 将 SQL 转换为管道,并在 Flink 或 Spark 等分布式运行器上运行您的管道。 本文通过在笔记本中使用 beam_sql 魔法启动 Dataflow 上的一次性作业来演示这一点。
在 Dataflow 上运行
现在您拥有了一个从 JSON 解析 US COVID 数据并查找具有每个日期最多阳性病例的州的阳性/阴性/州信息的管道,您可以尝试将其应用于所有历史每日数据并在 Dataflow 上运行它。
您将使用的新的数据源是来自 USAFacts US Coronavirus 数据库的公共数据集,其中包含美国 COVID 病例的所有历史每日汇总。
数据的模式与 covid 跟踪项目网站提供的模式非常相似。 您将查询的字段是:date、state、confirmed_cases 和 deaths。
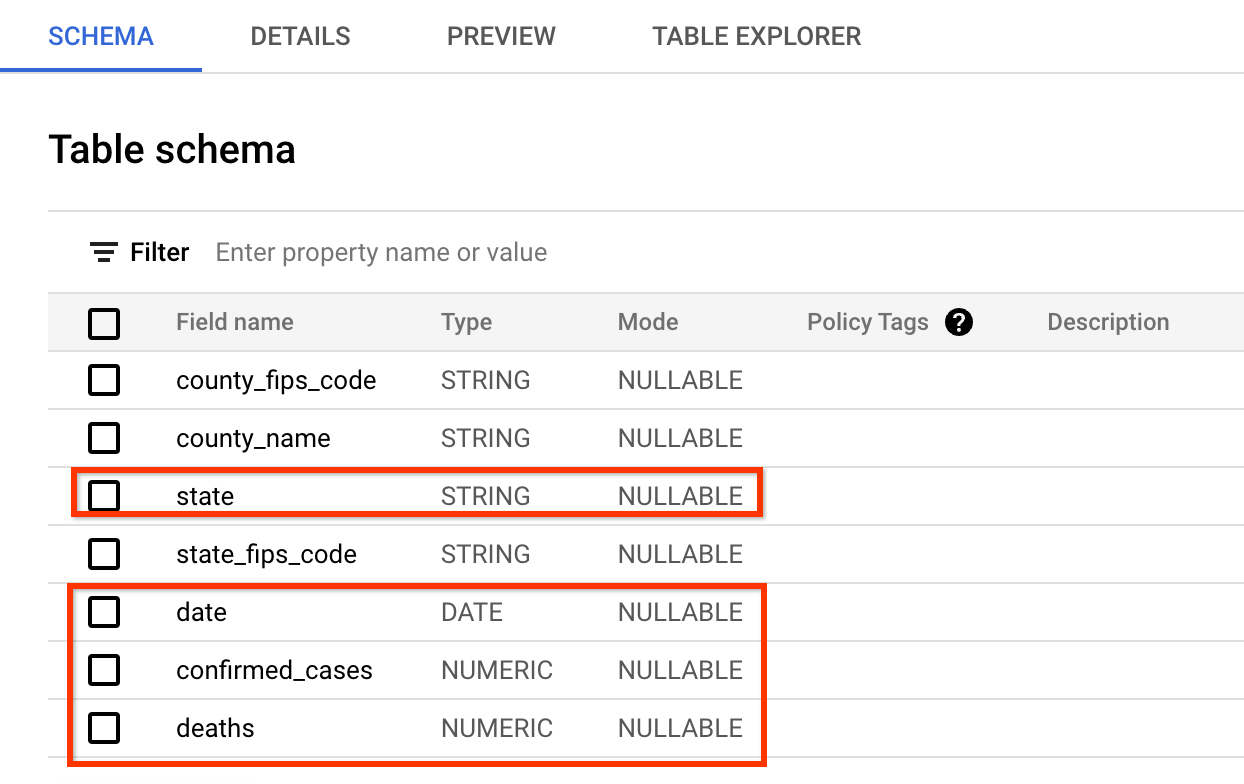
数据的预览如下所示(您可能跳过 BigQuery 中的检查,只需看一下屏幕截图即可)

数据的格式与您在先前管道中解析的 JSON 数据略有不同,因为数字按县而不是州分组,因此需要在 SQL 中进行一些额外的聚合。
如果您需要全新执行,您可以点击顶部菜单上的“重新启动内核”按钮。
完整代码如下,位于原始管道和查询之上
- 它将数据源从单日数据更改为更完整的历史数据;
- 它更改了 I/O 和模式以适应新数据集;
- 它更改了 SQL 以包括更多聚合以适应数据集的新格式。
使用模式准备数据
from typing import NamedTuple
from typing import Optional
# Public BQ dataset.
table = 'bigquery-public-data:covid19_usafacts.summary'
# Replace with your project.
project = 'YOUR-PROJECT-NAME-HERE'
# Replace with your GCS bucket.
gcs_location = 'gs://YOUR_GCS_BUCKET_HERE'
class UsCovidData(NamedTuple):
partition_date: str
state: str
confirmed_cases: Optional[int]
deaths: Optional[int]
p_on_dataflow = beam.Pipeline(runner=InteractiveRunner())
covid_data = (p_on_dataflow
| 'Read dataset' >> beam.io.ReadFromBigQuery(
project=project, table=table, gcs_location=gcs_location)
| 'Parse' >> beam.Map(
lambda e: UsCovidData(
partition_date=str(e['date']),
state=e['state'],
confirmed_cases=int(e['confirmed_cases']),
deaths=int(e['deaths']))).with_output_types(UsCovidData))
在 Dataflow 上运行
在 Dataflow 上运行 SQL 非常简单,您只需添加选项 -r DataflowRunner 即可。
%%beam_sql -o data_by_state -r DataflowRunner
SELECT partition_date, state, SUM(confirmed_cases) as confirmed_cases, SUM(deaths) as deaths
FROM covid_data
GROUP BY partition_date, state
与之前的 beam_sql 魔法执行不同,您不会立即看到结果。 相反,笔记本单元格输出中会打印类似于以下内容的表单

beam_sql 魔法尽最大努力猜测您的项目 ID 和首选云区域。 您仍然需要输入提交 Dataflow 作业所需的其他信息,例如用于暂存 Dataflow 作业的 GCS 存储桶以及作业需要的任何其他 Python 依赖项。
目前,请忽略单元格输出中的表单,因为您还需要 2 个 SQL 来:1) 查找每天的最大确认病例数;2) 将最大病例数据与完整的 data_by_state 连接起来。 beam_sql 魔法允许您链接 SQL,因此通过执行以下操作链接 2 个
%%beam_sql -o max_cases -r DataflowRunner
SELECT partition_date, MAX(confirmed_cases) as confirmed_cases
FROM data_by_state
GROUP BY partition_date
和
%%beam_sql -o data_with_max_cases -r DataflowRunner
SELECT data_by_state.partition_date, data_by_state.state, data_by_state.confirmed_cases, data_by_state.deaths
FROM data_by_state JOIN max_cases
USING (partition_date, confirmed_cases)
默认情况下,在 Dataflow 上运行 beam_sql 时,输出 PCollection 将写入 GCS 上的文本文件。 “写入”由 beam_sql 自动提供,主要用于您检查此一次性 Dataflow 作业的输出数据的用途。 它很轻量级,不会对元素进行编码以供进一步开发。 要保存输出并与他人共享,您可以在其中添加更多 Beam I/O。
例如,您可以使用上述模式感知 PCollection 示例中描述的技术将元素适当编码到文本文件中。
from apache_beam.options.pipeline_options import GoogleCloudOptions
coder = beam.coders.registry.get_coder(data_with_max_cases.element_type)
max_data_file = gcs_location + '/encoded_max_data'
data_with_max_cases | beam.io.textio.WriteToText(max_data_file, coder=coder)
此外,您可以在自己的项目中创建一个新的 BQ 数据集来存储已处理的数据。
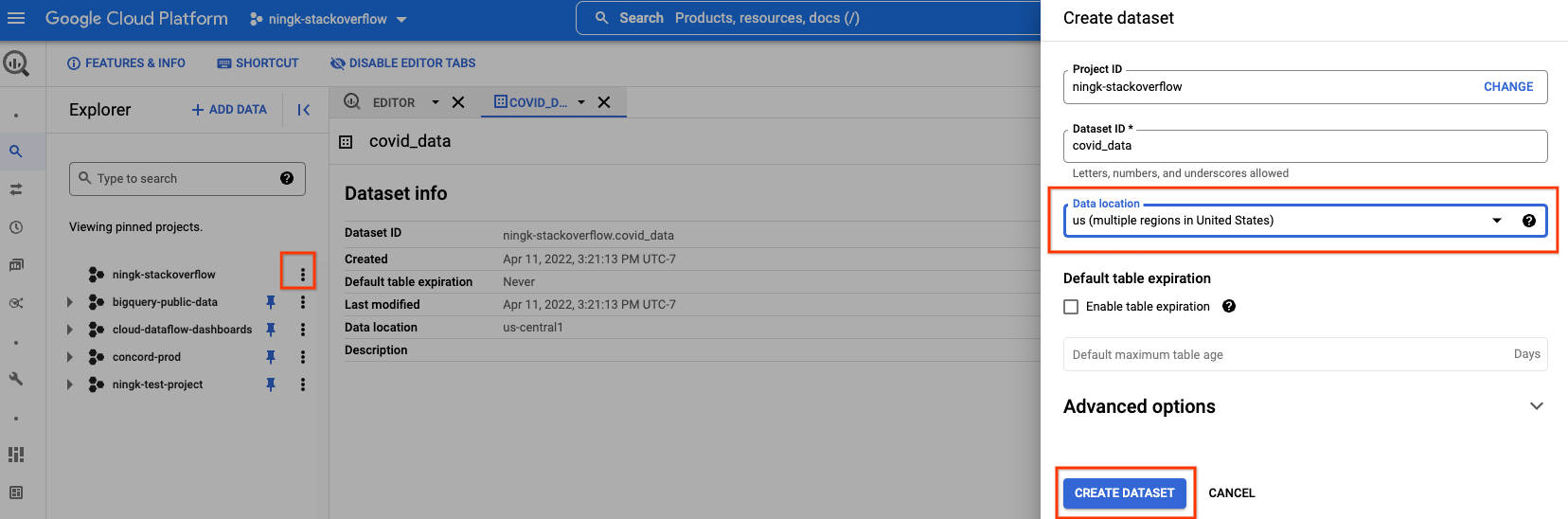
您必须选择与您正在读取的公共 BigQuery 数据相同的数据位置。 在这种情况下,“美国(美国多个区域)”。
创建完空数据集后,您可以执行以下操作
output_table=f'{project}:covid_data.max_analysis'
bq_schema = {
'fields': [
{'name': 'partition_date', 'type': 'STRING'},
{'name': 'state', 'type': 'STRING'},
{'name': 'confirmed_cases', 'type': 'INTEGER'},
{'name': 'deaths', 'type': 'INTEGER'}]}
(data_with_max_cases
| 'To json-like' >> beam.Map(lambda x: {
'partition_date': x.partition_date,
'state': x.state,
'confirmed_cases': x.confirmed_cases,
'deaths': x.deaths})
| beam.io.WriteToBigQuery(
table=output_table,
schema=bq_schema,
method='STREAMING_INSERTS',
custom_gcs_temp_location=gcs_location))
现在,返回最后一个 SQL 单元格输出中的表单,您可以填写必要的 信息在 Dataflow 上运行管道。 一个示例输入如下所示
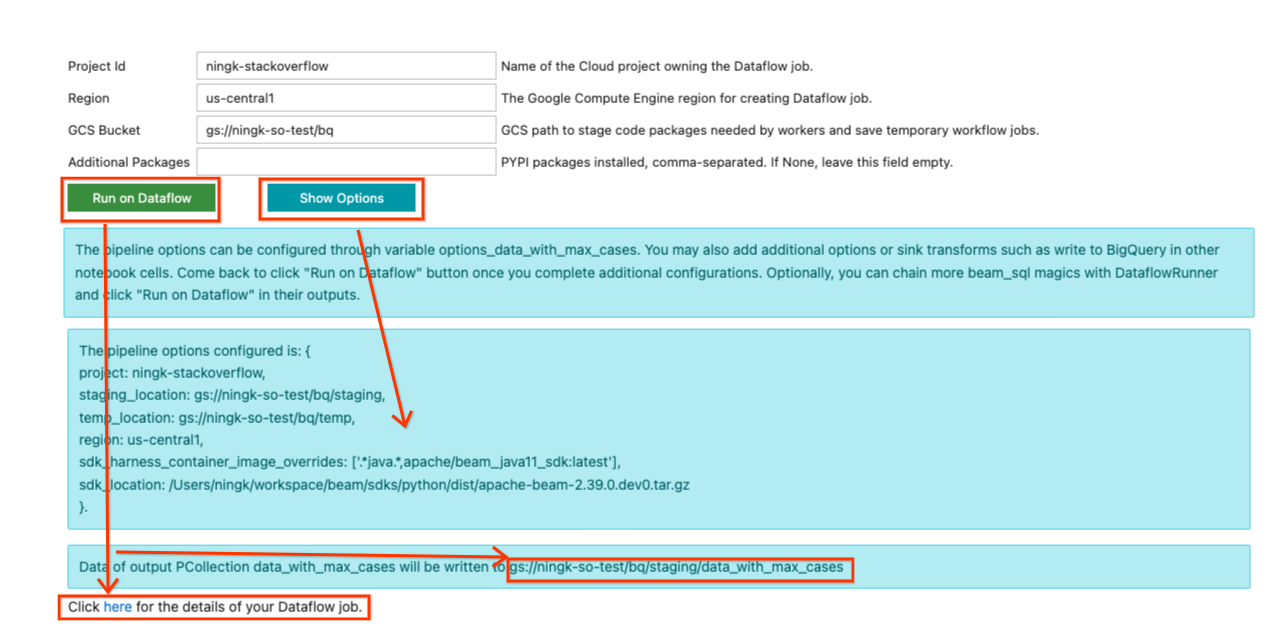
因为此管道不使用任何其他 Python 依赖项,所以“其他包”保持为空。 在您安装名为 names 的包的先前示例中,要在 Dataflow 上运行该管道,您必须将 names 放入此字段。
更新完输入后,您可以点击“显示选项”按钮查看根据您的输入配置了哪些管道选项。 将生成一个变量 options_[YOUR_OUTPUT_PCOLL_NAME],如果表单不足以执行,您可以在其中提供更多管道选项。
准备好提交 Dataflow 作业后,点击“在 Dataflow 上运行”按钮。 它会告诉您默认输出将写入的位置,一段时间后,将显示一行包含以下内容的文字
点击此处查看您的 Dataflow 作业的详细信息。
您可以点击超链接转到您的 Dataflow 作业页面。(或者,您可以忽略表单并继续开发以扩展您的管道。 满意管道的状态后,您可以返回到表单并提交作业到 Dataflow。)

如您所见,生成的 Dataflow 作业的每个转换名称都以字符串 [number]: 为前缀。 这是为了区分笔记本中重新执行的代码,因为 Beam 要求每个转换都具有不同的名称。 在幕后,beam_sql 魔法还会将您的模式信息暂存到 Dataflow,因此您可能会看到名为 schema_loaded_beam_sql_… 的转换。 这是因为笔记本中定义的 NamedTuple 可能位于 __main__ 范围内,而 Dataflow 根本不知道它们。 为了最大程度地减少用户干预并避免对整个主会话进行序列化(并且在主会话包含不可序列化的属性时对其进行序列化是不可行的),beam_sql 魔法通过序列化您的模式、将其暂存到 Dataflow 然后对它们进行反序列化/加载以供作业执行来优化暂存过程。
作业成功后,输出 PCollection 的结果将写入您的 I/O 转换指示的位置。注意:在 Dataflow 上运行 beam_sql 会生成一次性作业,它不是交互式的。
对默认输出位置的数据进行简单检查
!gsutil cat 'gs://ningk-so-test/bq/staging/data_with_max_cases*'

由您的 WriteToText 写入的包含编码二进制数据的文本文件
!gsutil cat 'gs://ningk-so-test/bq/encoded_max_data*'

由您的 WriteToBigQuery 创建的表 YOUR-PROJECT:covid_data.max_analysis

使用 beam_sql 魔法直接在其他 OSS 运行器上运行
在发布此博客的当天,beam_sql 魔法只支持 DirectRunner(交互式)和 DataflowRunner(一次性)。 它是在 SqlTransform 之上的一个简单包装器,其中包含由 ipywidgets 实现的交互式输入小部件。 您可以按照 说明 实现自己的运行器支持或实用程序。
此外,对其他 OSS 运行器的支持正在进行中,例如 使用 beam_sql 魔法支持 FlinkRunner。
结论
beam_sql 魔法和 Apache Beam 笔记本结合使用,是您学习 Beam SQL 并将 Beam SQL 混合到原型设计和生产环境中(例如,到 Dataflow)的便捷工具,只需最少的设置即可。
有关 Beam SQL 语法的更多详细信息,请查看 Beam Calcite SQL 兼容性 和 Apache Calcite SQL 语法。