



博客
2018/01/09
Apache Beam:回顾 2017
2017 年 1 月 10 日,Apache Beam 被 晋升为 Apache 软件基金会顶级项目。这是一个重要的里程碑,验证了项目的价值、社区的合法性,并预示着其日益增长的采用率。在过去的一年里,Apache Beam 发展迅猛,社区和功能集都得到了显著增长。让我们一起回顾一下一些值得注意的成就。
用例
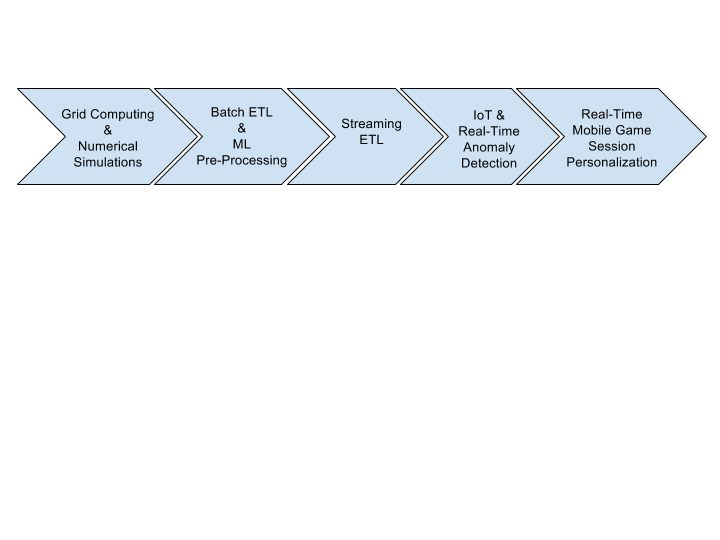
首先,让我们简单了解一下 Beam 在 2017 年的应用情况。Apache Beam 作为批处理和流处理的统一框架,支持非常广泛的各种用例。以下是一些用例,体现了 Beam 的多功能性。
社区发展
2017 年,Apache Beam 在全球范围内拥有 174 名贡献者,来自许多不同的组织。作为 Apache 项目,我们很自豪地拥有 18 名 PMC 成员和 31 名提交者。社区在 2017 年发布了 7 个版本,每个版本都带来了大量的新功能和修复。
Apache Beam 社区发展和可移植性核心价值主张得到验证的最明显和令人鼓舞的迹象是,新增了大量新的 运行器(即执行引擎)。我们在 2017 年初拥有 Apache Flink、Apache Spark 1.x、Google Cloud Dataflow、Apache Apex 和 Apache Gearpump。2017 年,开发了以下新的和更新的运行器
- Apache Spark 2.x 更新
- IBM Streams 运行器
- MapReduce 运行器
- JStorm 运行器
除了运行器之外,Beam 还添加了新的 IO 连接器,一些值得注意的连接器包括 Cassandra、MQTT、AMQP、HBase/HCatalog、JDBC、Solr、Tika、Redis 和 Elasticsearch 连接器。Beam 的 IO 连接器使您能够从数据源/接收器读取数据或写入数据,即使这些数据源/接收器不是底层执行引擎原生支持的。Beam 还提供完全可插拔的文件系统支持,使我们能够支持并扩展对 HDFS、S3、Azure 存储和 Google 存储的覆盖范围。我们继续添加新的 IO 连接器和文件系统,以扩展 Beam 的用例。
开源社区成熟度的明显标志是,社区能够与多个其他开源社区合作,并相互提高技术水平。在过去的几个月里,Beam、Calcite 和 Flink 社区齐心协力定义了一个强大的 规范,用于流式 SQL,来自四个组织的工程师都为其做出了贡献。如果您像我们一样对改进流式 SQL 的前景感到兴奋,请加入我们!
除了 SQL 之外,新的基于 XML 和 JSON 的声明式 DSL 也处于 PoC 阶段。
持续创新
创新对任何开源项目的成功都至关重要,Beam 在将创新的新理念带入开源社区方面有着悠久的历史。Apache Beam 是第一个在大型数据处理领域引入一些开创性概念的项目
- 统一的批处理和流式 SDK,使用户能够编写大型数据作业,而无需学习多个不同的 SDK/API。
- 跨引擎可移植性:让企业确信,今天编写的负载将来不必在开源引擎过时并被更新的引擎取代时重写。
- 语义对于推理无界无序数据至关重要,并能从流式作业中获得一致且正确的输出。
2017 年,创新速度持续加快。引入了以下功能
- 跨语言可移植性框架,以及使用该框架开发的 Go SDK。
- 动态可分片 IO(SplittableDoFn)
- 支持 PCollection 中的模式,使我们能够扩展运行器功能。
- 扩展以解决机器学习等新用例,以及新的数据格式。
改进领域
对项目的任何回顾,如果没有对改进领域的诚实评估,都是不完整的。有两个方面尤为突出
- 帮助运行器展示其各自的优势。毕竟,可移植性并不意味着同质性。不同的运行器在各自擅长的领域有所不同,我们需要更好地帮助他们突出其优势。
- 基于前一点,帮助客户在选择运行器或从一个运行器迁移到另一个运行器时做出更明智的决定。
2018 年,我们旨在采取积极措施,改进上述方面。
项目及其社区的精神
如今的批处理和流式大数据处理世界让人想起 巴别塔的寓言:由于不同的社区使用不同的语言,导致进展缓慢。同样,今天也存在着多个不同的大数据 SDK/API,每个 SDK/API 都有自己的独特术语来描述类似的概念。其副作用是用户混淆和采用率降低。
Apache Beam 项目旨在提供一个行业标准的可移植 SDK,该 SDK 将
- 通过提供 稳定性与创新 为用户带来益处:将 SDK 与引擎分离,使运行器之间能够进行良性竞争,而无需用户不断学习新的 SDK/API 和重写其负载以从新的创新中获益。
- 通过 为所有人做大蛋糕 为大数据引擎带来益处:使用户更容易编写、维护、升级和迁移其大数据负载,将导致生产大数据部署的数量显著增长。