



博客
2022/04/22
使用 Google Cloud Dataflow 运行 Apache Hop 可视化管道
简介
Apache Hop (https://hop.apache.org/) 是一个可视化开发环境,用于使用 Apache Beam 创建数据管道。您可以将 Hop 管道在 Spark、Flink 或 Google Cloud Dataflow 中运行。
在这篇文章中,我们将看到如何安装 Hop,以及如何在云中使用 Dataflow 运行示例管道。要按照本文中的步骤操作,您应该在 Google Cloud Platform 上拥有一个项目,并且应该有足够的权限来创建 Google Cloud Storage 存储桶(或使用现有的存储桶),以及运行 Dataflow 作业。
准备好 Google Cloud 项目后,您需要 安装 Google Cloud SDK 来触发 Dataflow 管道。
另外,不要忘记配置 Google Cloud SDK 以使用您的帐户和项目。
设置和本地执行
您可以将 Apache Hop 作为本地应用程序运行,或者使用 Hop Web 版本 从 Docker 容器运行。本文中给出的说明适用于本地应用程序,因为如果 Hop 在容器中运行,则 Cloud Dataflow 的身份验证将有所不同。所有其他说明仍然有效。Hop 的 UI 无论是作为本地应用程序运行还是在 Web 版本中运行,都是完全相同的。
现在是时候下载并安装 Apache Hop 了,请按照以下 说明 进行操作。
对于本文,我使用了 apache-hop-client 包中的二进制文件,版本为 1.2.0,于 2022 年 3 月 7 日发布。
安装 Hop 后,我们就可以开始了。
Zip 文件包含一个名为 config 的目录,您将在其中找到一些示例项目和一些用于 Dataflow 和其他运行器的管道运行配置。
对于此示例,我们将使用位于 config/projects/samples/beam/pipelines/input-process-output.hpl 中的管道。
让我们从打开 Apache Hop 开始。在您解压缩客户端的目录中,运行
./hop/hop-gui.sh
(或者 ./hop/hop-gui.bat,如果您使用的是 Windows)。
进入 Hop 后,让我们打开管道。
我们首先从项目 default 切换到项目 samples。找到窗口左上角的 projects 框,然后选择项目 samples
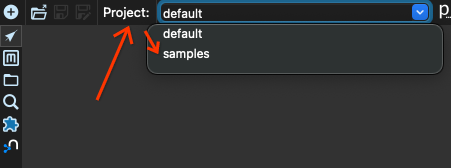
现在我们点击打开按钮
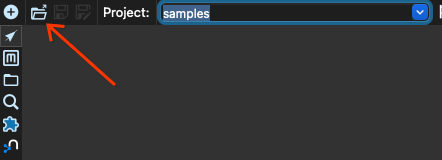
在 beam/pipelines 子目录中选择管道 input-process-output.hpl
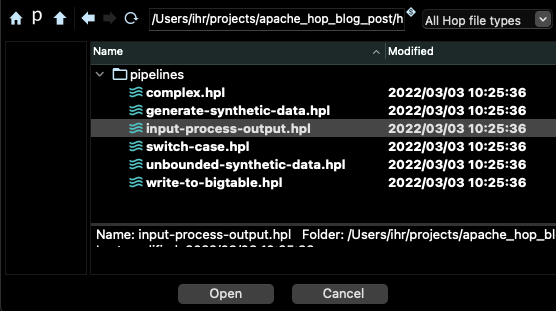
您应该在 Hop 的主窗口中看到如下所示的图表
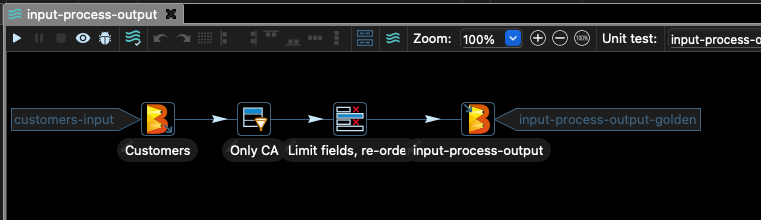
此管道从 CSV 文件中获取一些客户数据,并过滤掉除 stateCode 列等于 CA 的记录以外的所有记录。
然后我们只选择文件中的某些列,并将结果写入 Google Cloud Storage。
在将管道提交到 Dataflow 之前,始终先在本地测试管道是一个好主意。在 Apache Hop 中,您可以预览每个转换的输出。让我们看看输入 Customers。
点击 Customers 输入转换,然后在选择转换后打开的对话框中点击 预览输出
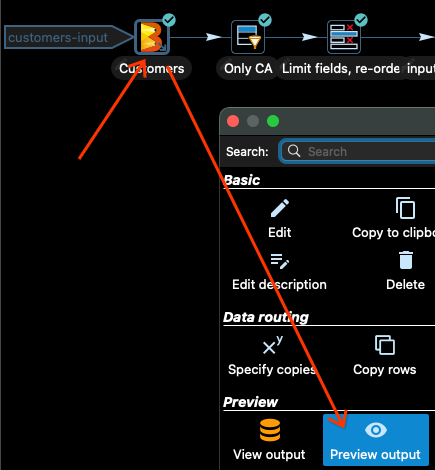
现在选择 快速启动 选项,您将看到一些输入数据

完成数据审查后,点击 停止。
如果我们在 Only CA 转换之后立即重复此过程,我们将看到所有行的 stateCode 列都等于 CA。
下一个转换只选择输入数据中的某些列,并重新排序这些列。让我们看看。点击转换,然后点击 预览输出
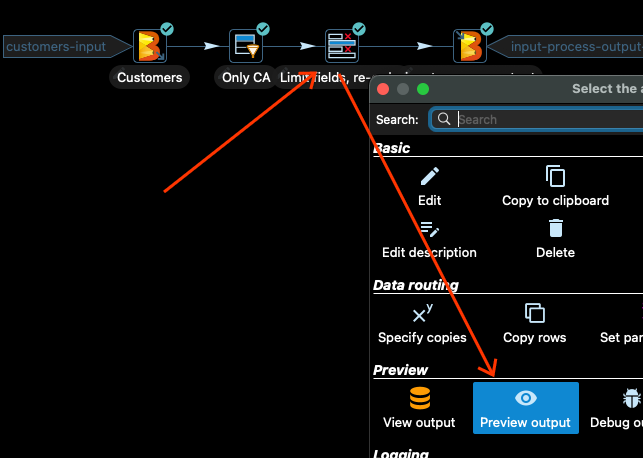
然后再次点击 _快速启动_,您应该看到以下输出
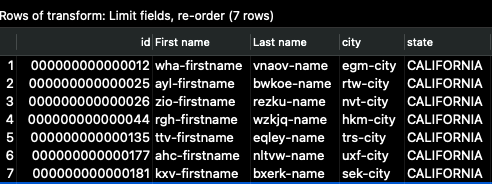
id 列现在是第一列,我们只看到输入列的一部分。这就是管道完成写入完整输出后数据的显示方式。
使用 Beam Direct Runner
让我们运行管道。要运行管道,我们需要指定运行器配置。这通过 Apache Hop 的元数据工具完成
在 samples 项目中,已经创建了多个配置

local 配置用于使用 Hop 运行管道。例如,这是我们在检查不同步骤输出预览时使用的配置。
Direct 配置使用 Apache Beam 的直接运行器。让我们看看它是什么样的。管道运行配置中有两个选项卡:主选项卡和变量选项卡。
对于直接运行器,主选项卡具有以下选项

我们可以更改工作程序数量设置以匹配我们的 CPU 数量,甚至将其限制为 1,这样管道就不会消耗太多资源。
在变量选项卡中,我们找到了管道本身的配置参数(而不是运行器的配置参数):\\
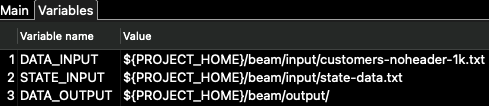
对于此管道,只使用了 DATA_INPUT 和 DATA_OUTPUT 变量。STATE_INPUT 用于另一个示例。
如果转到管道输入和输出节点中的 Beam 转换,您将看到这些变量是如何在那里使用的

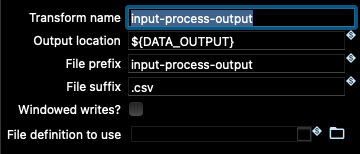
由于这些变量已正确设置以指向样本项目文件夹中数据的存储位置,因此让我们尝试使用 Beam Direct Runner 运行管道。
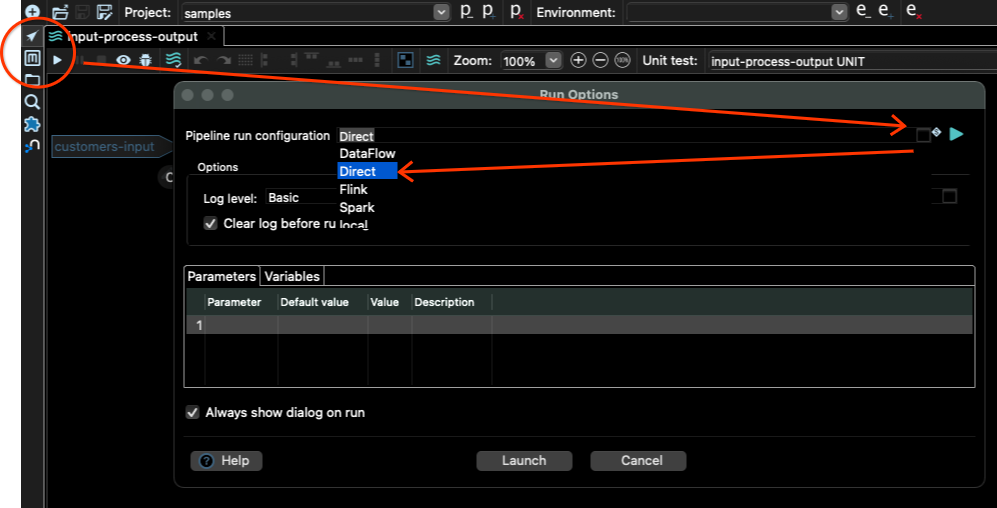
为此,我们需要返回管道视图(元数据工具上方的箭头按钮),然后点击运行按钮(工具栏中的小型“播放”按钮)。然后选择 Direct 管道运行配置,然后点击 启动 按钮
您如何知道作业是否已完成?您可以检查主窗口底部的日志以了解这一点。您应该看到类似以下内容
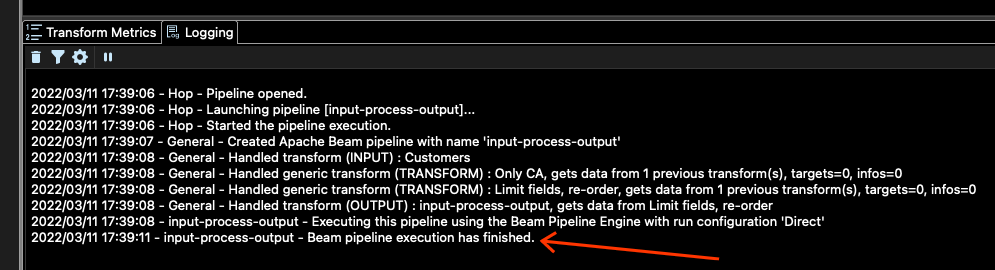
如果我们转到 DATA_OUTPUT 设置的位置,在本例中为 config/projects/samples/beam/output,我们应该在那里看到一些输出文件。在我的例子中,我看到这些文件

文件数量取决于您在运行配置中设置的工作程序数量。
太好了,所以管道在本地运行。现在是时候在云中运行它了!
使用 Dataflow 在云端大规模运行
让我们看看 Dataflow 管道运行配置。转到元数据工具,然后转到管道运行配置,并选择 Dataflow
我们又有主选项卡和变量选项卡。我们需要在两者中都更改一些值。让我们从变量开始。点击变量选项卡,您应该看到以下值

这些是属于该示例项目作者的 Google Cloud Storage (GCS) 位置。我们需要将它们更改为指向我们自己的 GCS 存储桶。
Google Cloud 中的项目设置
但为此,我们需要创建一个存储桶。对于下一步,您需要确保已配置 gcloud(Google Cloud SDK)以及已成功进行身份验证。
要仔细检查,请运行命令 gcloud config list 并检查帐户和项目是否正确。如果正确,让我们再三检查并运行 gcloud auth login。这应该会在您的 Web 浏览器中打开一个选项卡,以完成身份验证过程。完成此操作后,您可以使用 SDK 与您的项目进行交互。
对于此示例,我将使用 GCP 的 europe-west1 区域。让我们在那里创建一个区域存储桶。在我的例子中,我将存储桶名称用作 ihr-apache-hop-blog。为您的存储桶选择一个不同的名称!
gsutil mb -c regional -l europe-west1 gs://ihr-apache-hop-blog
现在让我们将示例数据上传到 GCS 存储桶,以测试管道如何在 Dataflow 中运行。转到您拥有所有 hop 文件的同一个目录(与 hop-gui.sh 所在的同一个目录),然后将数据复制到 GCS
gsutil cp config/projects/samples/beam/input/customers-noheader-1k.txt gs://ihr-apache-hop-blog/data/
请注意路径中的最终斜杠 /,这表示您要创建一个名为 data 的目录,其中包含所有内容。
要确保已正确上传数据,请检查该位置的内容
gsutil ls gs://ihr-apache-hop-blog/data/
您应该在该位置看到文件 customer-noheader-1k.txt。
在继续之前,请确保已在您的项目中启用 Dataflow,并且您已准备好一个服务帐户与 Hop 一起使用。请查看 Dataflow 文档中给出的说明,在 开始之前部分 中查看如何为 Dataflow 启用 API。
现在我们需要确保 Hop 可以使用访问 Dataflow 所需的凭据。在 Hop 文档中,您会发现它建议创建一个服务帐户,导出该服务帐户的密钥,并设置 GOOGLE_APPLICATION_CREDENTIALS 环境变量。这也是上述链接中给出的方法。
导出服务帐户的密钥可能存在安全隐患,因此我们将使用一种不同的方法,利用 Google Cloud SDK。运行以下命令
gcloud auth application-default login
这将打开一个选项卡,该选项卡将在您的 Web 浏览器中打开,询问您是否确认身份验证。确认后,系统中任何需要访问 Google Cloud Platform 的应用程序都将使用这些凭据进行访问。
我们还需要为 Dataflow 作业创建一个服务帐户,该帐户具有某些权限。使用以下命令创建服务帐户
gcloud iam service-accounts create dataflow-hop-sa
现在我们授予此服务帐户对 Dataflow 的权限
gcloud projects add-iam-policy-binding ihr-hop-playground \
--member="serviceAccount:dataflow-hop-sa@ihr-hop-playground.iam.gserviceaccount.com"\
--role="roles/dataflow.worker"
我们还需要为 Google Cloud Storage 授予其他权限
gcloud projects add-iam-policy-binding ihr-hop-playground \
--member="serviceAccount:dataflow-hop-sa@ihr-hop-playground.iam.gserviceaccount.com"\
--role="roles/storage.admin"
确保将项目 ID ihr-hop-playground 更改为您的项目 ID。
现在让我们授予我们的用户模拟该服务帐户的权限。为此,请转到 Google Cloud Console 中的 服务帐户,然后点击我们刚刚创建的服务帐户。
点击 权限 选项卡,然后点击 授予访问权限 按钮
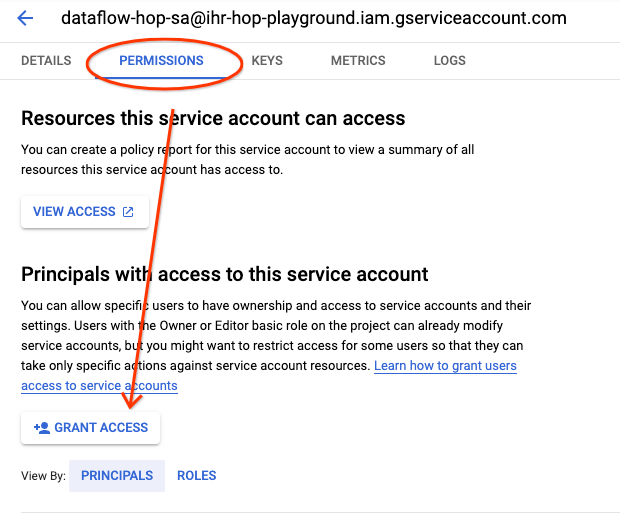
为您的用户授予 服务帐户用户 角色
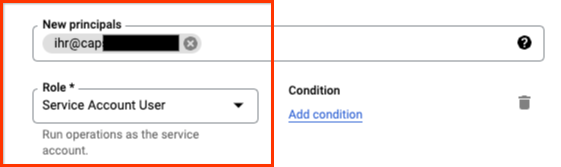
您现在已经准备好使用该服务帐户和您的用户运行 Dataflow 了。
更新管道运行配置
在我们能够在 Dataflow 中运行管道之前,我们需要生成管道代码的 JAR 包。为此,您必须转到 工具 菜单(在菜单栏中),然后选择 生成 Hop fat jar 选项。在对话框中点击确定,然后选择 JAR 文件的存储位置和文件名,然后点击 保存
生成文件需要几分钟时间

我们已经准备好将管道在 Dataflow 中运行。或者几乎准备好了:)。
转到管道编辑器,点击播放按钮,选择 DataFlow 作为管道运行配置,然后点击右侧的播放按钮
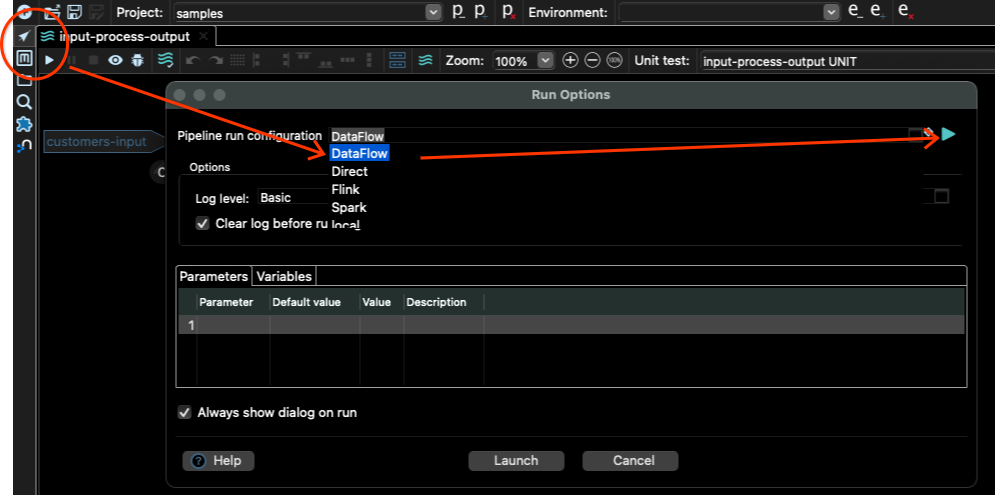
这将打开 Dataflow 管道运行配置,您可以在其中更改输入变量和其他 Dataflow 设置。
点击 变量 选项卡,只修改 DATA_INPUT 和 DATA_OUTPUT 变量。
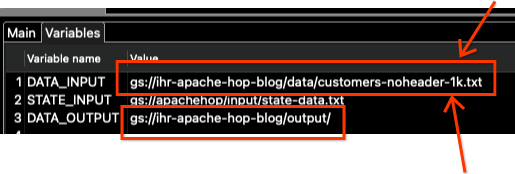
请注意,我们还需要更改文件名。
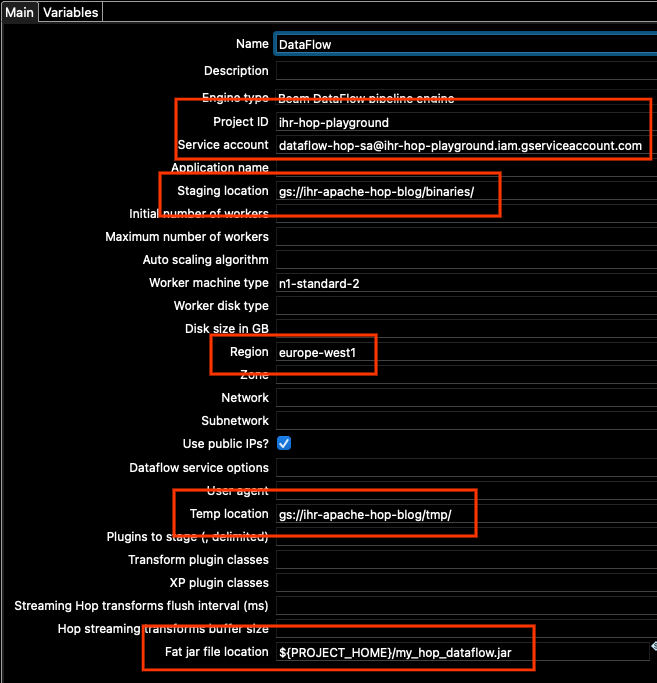
现在让我们转到Main选项卡,因为那里还有一些我们需要更改的选项。我们需要更新
- 项目 ID
- 服务帐户
- 暂存位置
- 区域
- 临时位置
- Fat Jar 文件位置
对于项目 ID,请设置您的项目 ID(与您在运行gcloud config list时看到的相同)。
对于服务帐户,请使用我们创建的服务帐户的地址。如果您不记得,您可以在 Google Cloud Console 中的服务帐户下找到它。
对于暂存和临时位置,请使用我们刚刚创建的同一个存储桶。在路径中更改存储桶地址,并保留已在配置中设置的相同的“binaries”和“tmp”位置。
对于区域,在本例中我们使用europe-west1。
此外,根据您的网络配置,您可能希望选中“使用公用 IP?”框,或者选择不选中该框,但在您项目的 europe-west1 区域子网中启用 Google 私有访问(有关详细信息,请参阅配置私有 Google 访问 | VPC)。在本例中,为简单起见,我将选中该框。
对于 Fat Jar 位置,请使用右侧的“浏览”按钮,并找到我们上面生成的 JAR 文件。总之,我的Main选项看起来像这样(您的项目 ID 和位置将不同)
当然,您可以根据项目可能需要的特定设置更改任何其他选项。
准备好后,点击“确定”按钮,然后点击“启动”以触发管道。
在日志窗口中,您应该看到类似以下内容的行

检查 Dataflow 中的作业
如果一切顺利,您现在应该看到一个作业正在运行,网址为https://console.cloud.google.com/dataflow/jobs.
如果由于某种原因作业失败了,请打开失败的作业页面,检查底部的“日志”,并点击错误图标以查找管道失败的原因。这通常是因为我们在您的配置中设置了一些错误的选项。
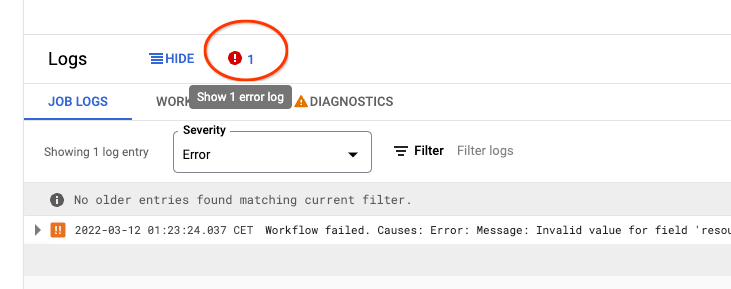
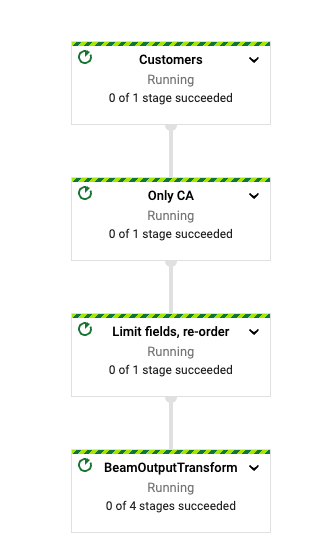
当管道开始运行时,您应该在作业页面中看到管道的图表。
当作业完成时,输出位置应该有一个文件。您可以使用gsutil检查它。
% gsutil ls gs://ihr-apache-hop-blog/output
gs://ihr-apache-hop-blog/output/input-process-output-00000-of-00003.csv
gs://ihr-apache-hop-blog/output/input-process-output-00001-of-00003.csv
gs://ihr-apache-hop-blog/output/input-process-output-00002-of-00003.csv
在我的情况下,作业生成了三个文件,但实际数量会在每次运行时有所不同。
让我们探索这些文件的第一行。
gsutil cat "gs://ihr-apache-hop-blog/output/*csv"| head
12,wha-firstname,vnaov-name,egm-city,CALIFORNIA
25,ayl-firstname,bwkoe-name,rtw-city,CALIFORNIA
26,zio-firstname,rezku-name,nvt-city,CALIFORNIA
44,rgh-firstname,wzkjq-name,hkm-city,CALIFORNIA
135,ttv-firstname,eqley-name,trs-city,CALIFORNIA
177,ahc-firstname,nltvw-name,uxf-city,CALIFORNIA
181,kxv-firstname,bxerk-name,sek-city,CALIFORNIA
272,wpy-firstname,qxjcn-name,rew-city,CALIFORNIA
304,skq-firstname,cqapx-name,akw-city,CALIFORNIA
308,sfu-firstname,ibfdt-name,kqf-city,CALIFORNIA
我们可以看到所有行都有 CALIFORNIA 作为州,输出只包含我们选择的列,并且用户 ID 是第一列。您获得的实际输出可能会有所不同,因为数据处理的顺序在每次运行中都不相同。
我们使用了一个小数据样本运行了这个作业,但我们可以使用任意大的输入 CSV 运行相同的作业。Dataflow 会并行处理数据并将其分成块。
结论
Apache Hop 是一个用于 Beam 管道的可视化开发环境,允许我们本地运行管道,检查数据,调试,单元测试以及许多其他功能。一旦我们对本地运行的管道感到满意,我们就可以通过简单地设置使用 Dataflow 的必要参数,将相同的可视化管道部署到云中。
如果您想了解更多关于 Apache Hop 的信息,不要错过Hop 作者在 Beam 峰会上发表的演讲,也不要忘记查看入门指南。