



博客
2023/12/18
使用 Beam 和 Flink 构建可扩展的、自管理的流式基础设施:解决自动伸缩挑战 - 第 2 部分
使用 Flink 构建可扩展的、自管理的流式基础设施:解决自动伸缩挑战 - 第 2 部分
欢迎来到我们关于在 Kubernetes 上构建和管理 Apache Beam Flink 服务的深度系列的第 2 部分。在本节中,我们将仔细研究我们在实现自动伸缩时遇到的障碍。这些挑战不仅是障碍,也是我们创新和改进系统的机会。让我们分解这些问题,了解它们的背景,并探索我们开发的解决方案。
了解 Apache Beam 积压指标在 Flink 运行器环境中的表现
挑战:在我们当前的设置中,我们使用 Apache Flink 处理数据流。但是,我们遇到了一个令人困惑的问题:我们的 Flink 作业没有显示来自 Apache Beam 的积压指标。这些指标对于理解数据管道的状态和性能至关重要。
我们发现:有趣的是,我们注意到这些指标实际上是在 KafkaIO 中生成的,这是我们数据管道的一部分,用于处理 Kafka 流。但是,当我们尝试通过 Apache Flink 指标系统监控这些指标时,却找不到它们。我们怀疑 Apache Beam 和 Apache Flink 之间的集成(或“连线”)可能存在问题。
深入挖掘:经仔细检查,我们发现这些指标应该在数据流处理的“检查点”阶段发出。在此关键步骤中,系统会拍摄流状态的快照,并且这些指标通常是为无界源生成的指标。无界源是持续流式传输数据的源,例如 Kafka。
潜在解决方案:我们认为问题的根源在于检查点阶段设置指标上下文的方式。似乎存在断开连接,阻止 Beam 指标在 Flink 指标系统中被正确捕获。我们为这个问题提出了一个修复方案,您可以查看并在我们的 GitHub 拉取请求中做出贡献:Apache Beam PR #29793。
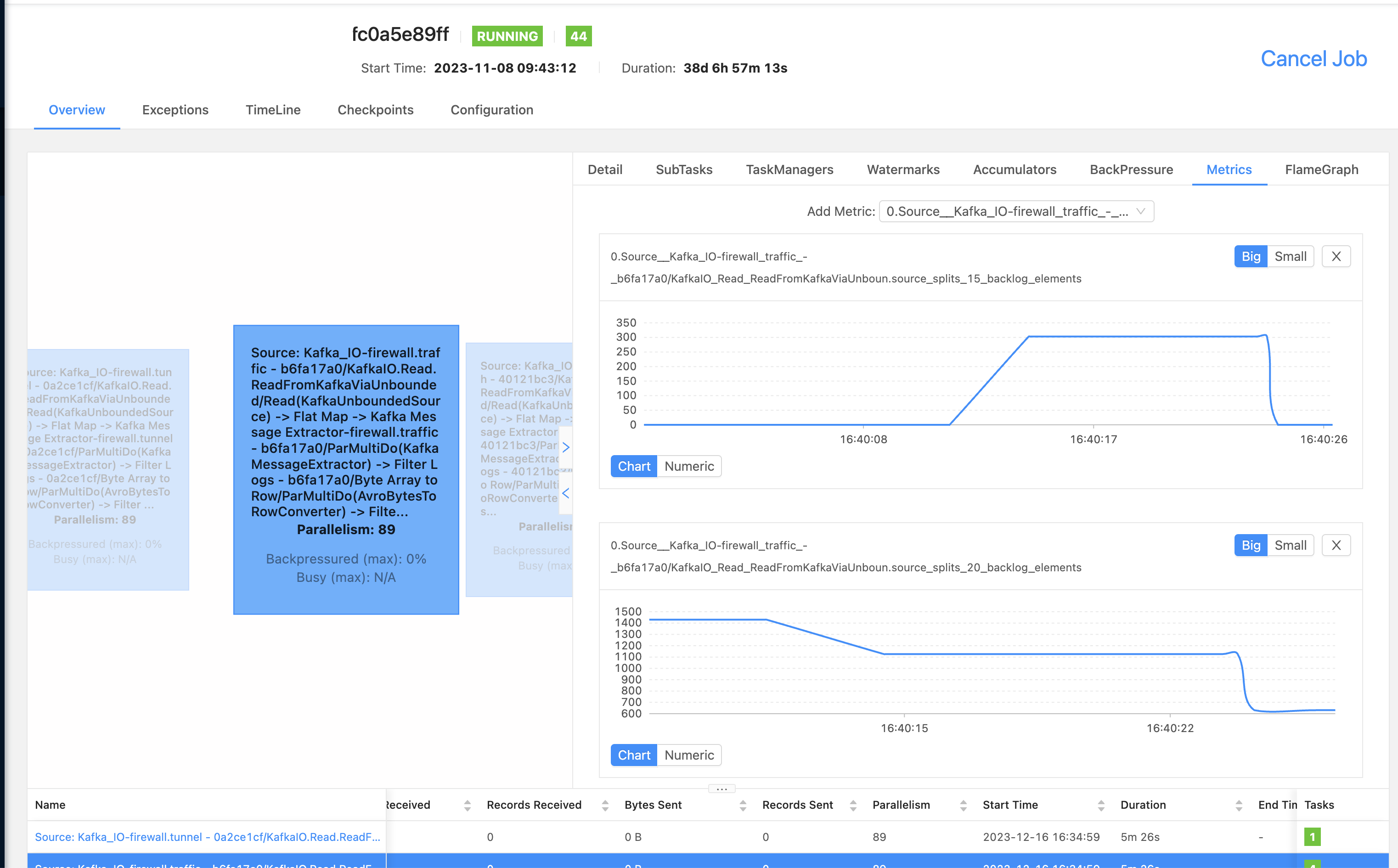
克服自动伸缩 Beam 作业的检查点大小减少方面的挑战
在本节中,我们将讨论减少自动伸缩 Apache Beam 作业的检查点大小的策略,重点关注 Apache Flink 中的有效检查点,以及优化捆绑大小和 PipelineOptions 以管理频繁的检查点超时和大型作业需求。
了解 Apache Flink 中检查点的基础知识
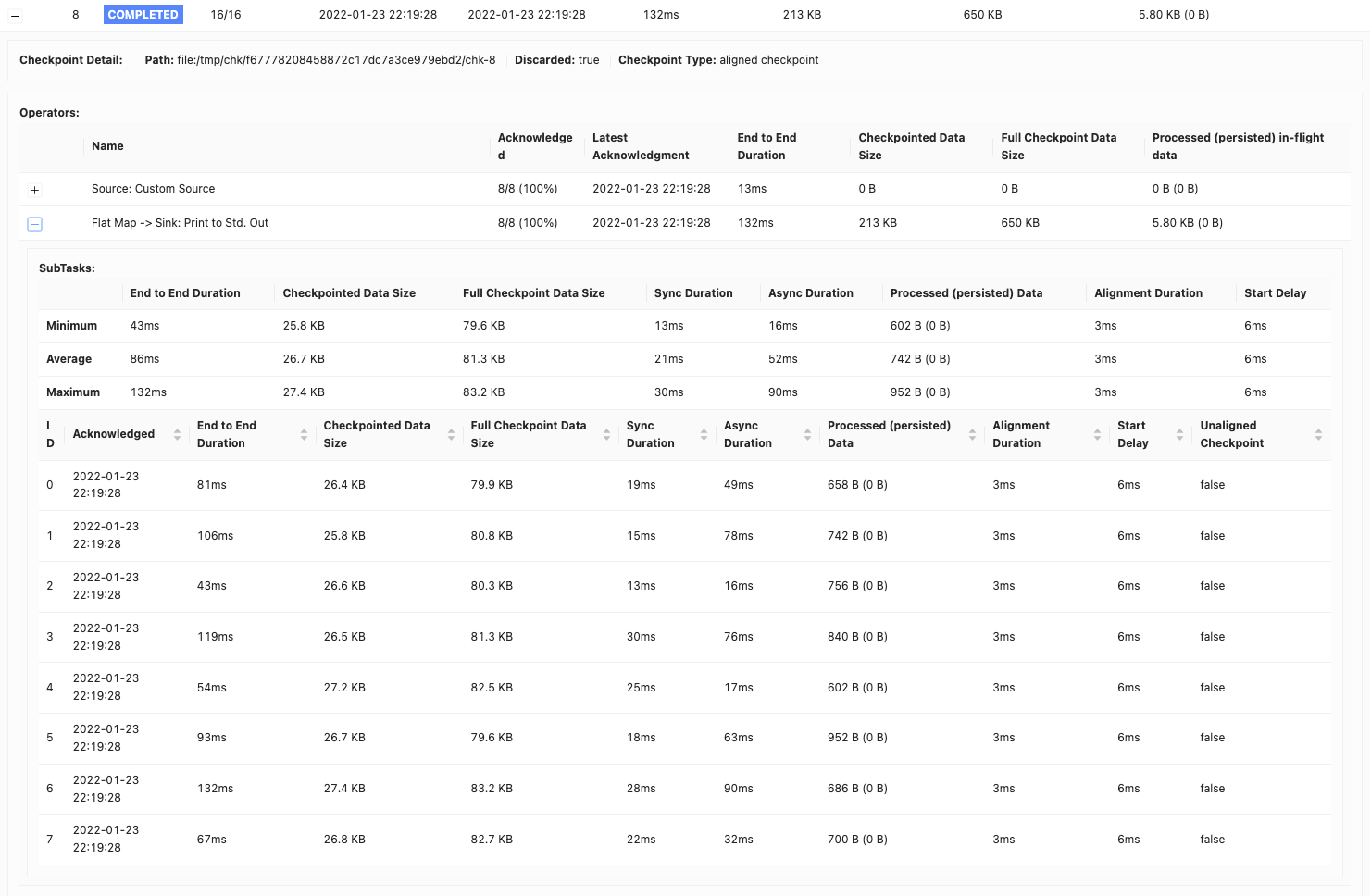
在流处理中,维护状态一致性和容错性至关重要。Apache Flink 通过称为检查点的过程来实现这一点。检查点会定期捕获作业操作员的状态,并将其存储在稳定的存储位置,例如 Google Cloud Storage 或 AWS S3。具体来说,Flink 每十秒钟检查点一次作业,并允许此过程最多完成一分钟。此过程对于确保在发生故障的情况下,作业可以从上次检查点恢复至关重要,从而提供恰好一次语义和容错能力。
捆绑在 Apache Beam 中的作用
Apache Beam 引入了捆绑的概念。捆绑本质上是一组一起处理的元素。此步骤通过减少单独处理每个元素的开销来提高处理效率和吞吐量。有关更多信息,请参见捆绑和持久性。在 Flink 运行器中,默认配置,捆绑的默认大小为 1000 个元素,超时时间为一秒钟。但是,根据我们的性能测试,我们将捆绑大小调整为10,000 个元素,超时时间为 10 秒钟。
挑战:频繁的检查点超时
当我们配置每 10 秒检查点一次时,我们遇到了频繁的检查点超时,通常超过 1 分钟。这是由于检查点的大小很大。
解决方案:管理检查点大小
在 Apache Beam Flink 作业中,finishBundleBeforeCheckpointing 选项起着至关重要的作用。启用时,它确保在启动检查点之前完成所有捆绑的处理。这会导致仅包含捆绑完成后的状态的检查点,从而显着减小检查点的大小。最初,我们的检查点每个管道约为 2 MB。通过这种改变,它们始终下降到 150 KB。
解决大型作业中的检查点大小
尽管减小了检查点大小,但每十秒钟 150 KB 的检查点仍然可能很大,尤其是在运行多个管道的作业中。例如,在单个作业中使用 100 个管道,此大小会膨胀到每 10 秒间隔 15 MB。
进一步优化:使用 PipelineOptions 减少检查点大小
我们发现,由于特定问题(BEAM-8577),我们的 Flink 运行器将我们的大型 PipelineOptions 对象包含在每个检查点中。我们通过从 PipelineOptions 中删除不必要的与应用程序相关的选项解决了这个问题,进一步将检查点大小减少到每个管道更易于管理的 10 KB。
Kafka 读取器等待时间:解决 Beam 作业中的自动伸缩挑战
了解未对齐的检查点
在我们的系统中,我们使用未对齐的检查点来加快检查点过程,这对于确保分布式系统中的数据一致性至关重要。但是,当我们激活 finishBundleBeforeCheckpointing 功能时,我们开始遇到检查点超时问题以及检查点步骤的延迟。Apache Beam 利用 Apache Flink 的传统源实现来处理无界源。在 Flink 中,任务分为两种类型:源任务和非源任务。
- 源任务:从外部系统获取数据到 Flink 作业中
- 非源任务:处理传入的数据
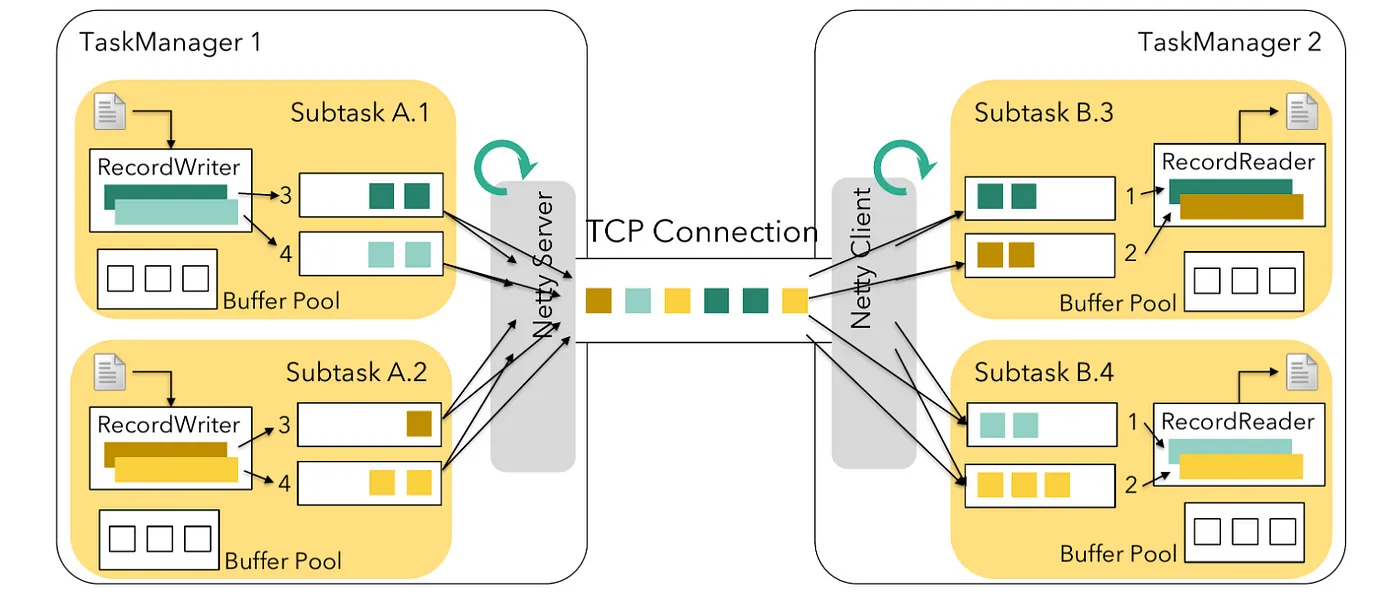
在标准配置中,非源任务会在拉取数据之前检查是否有可用缓冲区。如果源任务不执行此检查,它们可能会在将数据写入输出缓冲区时遇到检查点延迟。这种延迟会影响未对齐检查点的效率,这些检查点只有在输出缓冲区可用时才会被传统源任务识别。
使用 Beam 中的 UnboundedSourceWrapper 解决挑战
为了解决这个问题,Apache Flink 引入了一种新的源实现,该实现以拉取模式运行。在此模式下,任务会在获取数据之前检查是否有空闲缓冲区,这与非源任务的方法一致。
但是,Apache Beam 的 Flink Runner 仍然使用的传统源以推送模式运行。它会立即将数据发送到下游任务。这种设置可能会在缓冲区已满时造成瓶颈,导致检测未对齐的检查点屏障延迟。
我们的解决方案
尽管已弃用,但 Apache Beam 的 Flink Runner 仍然使用传统源实现。为了解决它的问题,我们实施了我们的修改以及FLINK-26759中建议的快速解决方法。这些增强功能在我们最近的拉取请求中有所说明。您也可以在拉取请求中找到更多关于未对齐检查点问题的相关信息。您还可以找到更多关于Flink 未对齐检查点的博客文章中的相关信息。
解决高流量场景中的缓慢读取
在我们使用 Apache Beam 和 Flink Runner 的过程中,我们遇到了与 How Intuit Debug Consumer Lags in Apache Beam 中记录的类似重大挑战。这是 Antonio Si 在 Intuit 的经历中记录的。他们的实时数据处理管道存在越来越严重的 Kafka 消费者延迟,尤其是在遇到大量消息流量的主题中。这个问题被追踪到 Apache Beam 通过 UnboundedSourceWrapper 和 KafkaUnboundedReader 处理 Kafka 分区的方式。具体来说,对于流量较低的主题,处理线程会不必要地暂停,从而延迟对高流量主题的处理。我们在自己的系统中也遇到了类似的情况,高流量主题和低流量主题之间的处理速度不平衡导致了效率低下。

为了解决这个问题,我们开发了一种创新的解决方案:KafkaIO 中的自适应超时策略。这种策略会根据每个主题的流量动态调整超时持续时间。对于低流量主题,它会缩短超时时间,防止不必要的延迟。对于高流量主题,它会延长超时时间,提供更多处理机会。这种方法在我们最近的拉取请求中有所详细说明。
Beam 作业自动伸缩中不平衡的分区分配
该系统的核心是自适应调度程序,它是一个专为快速资源分配而设计的组件。它会根据可用计算槽位的数量智能地调整作业执行的并行任务数(并行度)。这些槽位就像独立的工作站,每个槽位都能够处理作业的特定部分。
但是,我们遇到了一个问题。我们的作业包含多个独立的管道,每个管道都需要自己的资源集。最初,系统倾向于通过为前几个工作器分配更多任务而使它们不堪重负,而其他工作器则处于未充分利用状态。这个问题是由于 Flink 分配任务的方式造成的,它偏向于为每个管道分配前几个工作器。

为了解决这个问题,我们为 Flink 的SlotSharingSlotAllocator 开发了一个自定义补丁,它是一个负责任务分配的组件。此补丁确保更平衡的工作负载分布在所有可用工作器上,从而提高效率并防止出现瓶颈。有了这种改进,每个工作器都将获得公平的任务份额,从而实现更好的资源利用率,并使我们的 Beam 作业运行更加顺畅。
使用 Flink 在 Kubernetes Operator 中支持排空
挑战
在使用 Apache Flink 处理数据的世界中,一项常见的任务是管理和更新数据处理作业。这些作业可以是有状态的,它们会记住过去的数据,也可以是无状态的,它们不会记住过去的数据。
过去,当我们需要更新或删除由 Kubernetes Operator 管理的 Flink 作业时,系统会使用保存点或检查点来保存作业的当前状态。但是,缺少一个关键步骤:系统没有阻止作业处理新数据(这就是我们所说的排空作业)。这种疏忽会导致两个主要问题
- 对于有状态的作业:潜在的数据不一致,因为作业可能会处理保存点中未考虑的新数据
- 对于无状态的作业:数据重复,因为作业可能会重新处理已处理过的數據
解决方案:排空功能
这就是需要参考为FLINK-32700的更新的地方。此更新引入了排空功能。把它想象成告诉作业,“完成你正在处理的內容,但不要接受任何新内容。”以下是它的工作原理
- 停止新数据:作业停止读取新输入。
- 标记源:作业使用无限水位线标记源。将此水位线想象成一个标记,它告诉系统没有更多新数据需要处理。
- 在管道中传播: 然后,这个标记会通过作业的处理管道,确保作业的每个部分都知道不要再期待新数据。
这个看似很小的改变却带来了很大的影响。它确保当作业被更新或删除时,它所处理的数据保持一致性和准确性。这对任何数据处理任务来说都是至关重要的,因为它维护着数据的完整性和可靠性。此外,如果排水失败,你可以取消作业,而不需要保存点,这为整个流程增加了灵活性,提高了安全性。
结论
随着我们结束关于在 Kubernetes 上构建和管理 Apache Beam Flink 服务系列的第 2 部分,很明显,实施自动扩展的过程既具有挑战性又发人深省。我们遇到的障碍,从理解 Flink Runner 环境中的 Apache Beam 积压指标,到解决高流量场景下的慢速读取,促使我们开发了创新解决方案,加深了我们对流式基础设施的理解。
我们对检查点、Kafka Reader 等待时间和不平衡分区分配的复杂性的探索揭示了自动扩展 Beam 作业的复杂性。这些挑战促使我们设计了一些策略,例如 KafkaIO 中的自适应超时和 Flink 的 SlotSharingSlotAllocator 中的平衡工作负载分配。此外,Kubernetes Operator 中引入 Flink 的排水支持标志着在有效管理有状态和无状态作业方面取得了重大进展。
这段旅程不仅增强了我们系统的稳健性和效率,还为更广泛的 Apache Beam 和 Flink 社区贡献了宝贵的见解。我们希望我们的经验和解决方案能够帮助其他人解决项目中遇到的类似挑战。
请继续关注我们的下一篇文章,我们将深入探讨 Apache Beam 中自动扩展的细节。我们将分解概念、策略和最佳实践,以有效地扩展您的 Beam 作业。感谢您关注我们的系列,我们期待与您分享更多我们的旅程和经验。
致谢
这是在规模上从云提供商管理的流式基础设施迁移到自管理的基于 Flink 的基础设施的大量工作,并构建新的基础设施。感谢 Palo Alto Networks CDL 流式团队帮助我们实现了这一切:Kishore Pola,Andrew Park,Hemant Kumar,Manan Mangal,Helen Jiang,Mandy Wang,Praveen Kumar Pasupuleti,JM Teo,Rishabh Kedia,Talat Uyarer,Naitk Dani 和 David He。
了解更多
加入讨论,分享您在我们的 社区 上的经验,或为我们正在进行的项目贡献代码,请访问 GitHub。您的反馈非常宝贵。如果您对本系列有任何意见或问题,请随时通过 用户邮件列表 联系我们。
请关注我们,获取有关 Apache Beam、Flink 和 Kubernetes 的更多更新和见解。